ubuntu docker 安装 jdk hadoop 分布式
参考链接,参考链接2, 规范化的Dockerfile ,windows 安装JAVA
1.ubuntu 镜像的下载
docker run -ti ubuntu:14.042. Java JDK 的安装,
此时容器已经启动,在容器中安装java,
方便快速下载package 可以 更换源,进入镜像 然后进行接下来的操作。
docker run -it ubuntu bash
接下来是在镜像内操作了
apt-get install wget #wget
apt-get install net-tools #ifconfig
apt-get install iputils-ping #ping
apt-get install vim #你可以下载自己喜欢的编辑器,不一定是vim
sudo add-apt-repository ppa:webupd8team/java
sodu apt-get update
apt-get install oracle-java8-installer
我这里安装的是java8,当然你可以安装其他版本的java,就把oracle-java8-installer中的数字改改就行
或者你可以在oricle 官网下载好 JDK 然后本地解压安装
打开http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
ctrl+左键 在新打开的页面 复制链接
download.oracle.com/otn-pub/java/jdk/8u111-b14/jdk-8u111-linux-x64.tar.gz
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" download.oracle.com/otn-pub/java/jdk/8u111-b14/jdk-8u111-linux-x64.tar.gz
tar -zxvf jdk-8u111-linux-x64.tar.gz 解压tar包
sudo mkdir -pv /usr/java root用户不需要sudo
cp -r jdk1.8.0_111/ /usr/java
3.hadoop 安装
wget https://mirrors.cnnic.cn/apache/hadoop/common/hadoop-2.6.5/hadoop-2.6.5.tar.gz 将压缩包迁移到指定目录然后解压,然后配置环境变量
4. 将hadoop JDK 环境变量配置好, vi /etc/profile
export JAVA_HOME=/soft/jdk-12.0.1
export HADOOP_HOME=/soft/hadoop-2.8.5
export HADOOP_CONFIG_HOME=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin/etc/bashrc /etc/profile 的区别
/etc/profile:此文件为系统的每个用户设置环境信息,当用户第一次登录时,该文件被执行,并从/etc/profile.d目录的配置文件中搜集shell的设置,
/etc/bashrc:为每一个运行bash shell的用户执行此文件,当bash shell被打开时,该文件被读取。
~/.bash_profile:每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该文件仅仅执行一次!默认情况下,他设置一些环境变量,执行用户的.bashrc文件。
~/.bashrc:该文件包含专用于你的bash shell的bash信息,当登录时以及每次打开新的shell时,该文件被读取。添加以下信息到/etc/profile 然后source /etc/profile
export JAVA_HOME=/soft/jdk-12.0.1
export HADOOP_HOME=/soft/hadoop-2.8.5
export HADOOP_CONFIG_HOME=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin5.配置Hadoop
下面,我们开始修改Hadoop的配置文件(/soft/hadoop-2.6.5/etc/hadoop)。主要配置hadoop-env.sh、core-site.xml、hdfs-site.xml、mapred-site.xml这四个文件。
开始配置之前,执行下面命令:
5.1hadoop-env.sh 中
export JAVA_HOME=/usr/java/jdk-12.0.15.2core-site.xml
hadoop.tmp.dir
/soft/hadoop-2.8.5/tmp
A base for other temporary directories.
fs.default.name
hdfs://master:9000
true
The name of the default file system. A URI whose
scheme and authority determine the FileSystem implementation. The
uri's scheme determines the config property (fs.SCHEME.impl) naming
the FileSystem implementation class. The uri's authority is used to
determine the host, port, etc. for a filesystem.
5.3.hdfs-site.xml配置
dfs.replication
2
true
Default block replication.
The actual number of replications can be specified when the file is created.
The default is used if replication is not specified in create time.
dfs.namenode.name.dir
/soft/hadoop-2.8.5/namenode
true
dfs.datanode.data.dir
/soft/hadoop-2.8.5/datanode
true
5.4.mapred-site.xml配置
mapred.job.tracker
master:9001
The host and port that the MapReduce job tracker runs
at. If "local", then jobs are run in-process as a single map
and reduce task.
6 .格式化 namenode
这是很重要的一步,执行命令hadoop namenode -format7 安装SSH
搭建集群环境,自然少不了使用SSH。这可以实现无密码访问,访问集群机器的时候很方便。
sudo apt-get install sshSSH装好了以后,由于我们是Docker容器中运行,所以SSH服务不会自动启动。需要我们在容器启动以后,手动通过/usr/sbin/sshd 手动打开SSH服务。未免有些麻烦,为了方便,我们把这个命令加入到~/.bashrc文件中。通过nano ~/.bashrc编辑.bashrc文件(nano没有安装的自行安装,也可用vi),在文件后追加下面内容:
#autorun
/usr/sbin/sshd生成访问密钥
root@8ef06706f88d:/# cd ~/
root@8ef06706f88d:~# ssh-keygen -t rsa -P '' -f ~/.ssh/id_dsa
root@8ef06706f88d:~# cd .ssh
root@8ef06706f88d:~/.ssh# cat id_dsa.pub >> authorized_keys注意: 这里,我的思路是直接将密钥生成后写入镜像,免得在买个容器里面再单独生成一次,还要相互拷贝公钥,比较麻烦。当然这只是学习使用,实际操作时,应该不会这么搞,因为这样所有容器的密钥都是一样的!!
The authenticity of host 'localhost (127.0.0.1)' can't be established的处理方法:
/etc/ssh/ssh_config 文件后面添加
StrictHostKeyChecking no
UserKnownHostsFile /dev/null8.保存镜像副本
这里我们将安装好Hadoop的镜像保存为一个副本。
root@2c241377ccdf:~# exit
root@lacalhost:~$ docker commit -m "hadoop install" 2c241377ccdf ubuntu:hadoop这里注意docker commit -m “注释” 容器id 镜像名:tag名
到目前为止,hadoop的安装已经结束了,下面就是完全分布式的搭建了.
======================================================================
分布式的搭建
Hadoop分布式环境搭建
因为分布式是三个或者以上的机器之间通讯,所以必须知道对方的ip地址和从属关系.可以参考此处 自定义网络 固定IP
if [ $(hostname) == "master" ]
then
if [ `grep "slave1" $HADOOP_CONFIG_HOME/slaves` ]
then
echo "slave1 has exist"
else
echo "slave1" >> $HADOOP_CONFIG_HOME/slaves
fi
if [ `grep "slave2" $HADOOP_CONFIG_HOME/slaves` ]
then
echo "slave2 has exist"
else
echo "slave2" >> $HADOOP_CONFIG_HOME/slaves
fi
fi
cp /etc/hosts /etc/hosts.tmp
sed -i '$d' /etc/hosts.tmp
cat /etc/hosts.tmp > /etc/hosts
rm /etc/hosts.tmp
echo -e "172.17.0.4\\tmaster\\n172.17.0.5\\tslave1\\n172.17.0.6\\tslave2" >> /etc/hosts
#这里的ip地址用你自己的,用ifconfig查看 要替换为自己的将上述代码 编辑为脚本 然后docker cp 到 容器 然后提交为最终镜像。
启动master容器, -h 是给容器设置的主机名
docker run -ti -h master ubuntu:hadoop
启动slave1容器
docker run -ti -h slave1 ubuntu:hadoop
启动slave2容器
docker run -ti -h slave2 ubuntu:hadoop在每个容器中运行./set.sh文件,
在master节点上执行 $HADOOP_CONFIG_HOME/sbin/start-all.sh命令,启动Hadoop。
激动人心的一刻……

如果看到如下信息,则说明启动成功了:
注意点
1 根据搭建好的ubuntu:hadoop镜像 进行后台开启
docker run -dit --name hadoop_slave2 -h slave2 ubuntu:hadoop
docker run -dit --name hadoop_slave1 -h slave1 ubuntu:hadoop
docker run -dit --name hadoop_master -h master ubuntu:hadoop
2. 配置三个/etc/hosts
docker exec -it hadoop_slave2 /bin/bash echo -e "172.17.0.6\\tmaster\\n172.17.0.5\\tslave1\\n172.17.0.4\\tslave2" >> /etc/hosts
docker exec -it hadoop_slave1 /bin/bash echo -e "172.17.0.6\\tmaster\\n172.17.0.5\\tslave1\\n172.17.0.4\\tslave2" >> /etc/hosts
docker exec -it hadoop_master /bin/bash echo -e "172.17.0.6\\tmaster\\n172.17.0.5\\tslave1\\n172.17.0.4\\tslave2" >> /etc/hosts
master 中要配置
/soft/hadoop-2.8.5/etc/hadoop/slaves
localhost
slave1
slave2
最终运行
/soft/hadoop-2.8.5/sbin/start-all/shroot@master:~/soft/apache/hadoop/hadoop-2.6.0/etc/hadoop# start-all.sh
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [master]
master: starting namenode, logging to /root/soft/apache/hadoop/hadoop-2.6.0/logs/hadoop-root-namenode-master.out
slave1: starting datanode, logging to /root/soft/apache/hadoop/hadoop-2.6.0/logs/hadoop-root-datanode-slave1.out
slave2: starting datanode, logging to /root/soft/apache/hadoop/hadoop-2.6.0/logs/hadoop-root-datanode-slave2.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /root/soft/apache/hadoop/hadoop-2.6.0/logs/hadoop-root-secondarynamenode-master.out
starting yarn daemons
starting resourcemanager, logging to /root/soft/apache/hadoop/hadoop-2.6.0/logs/yarn--resourcemanager-master.out
slave1: starting nodemanager, logging to /root/soft/apache/hadoop/hadoop-2.6.0/logs/yarn-root-nodemanager-slave1.out
slave2: starting nodemanager, logging to /root/soft/apache/hadoop/hadoop-2.6.0/logs/yarn-root-nodemanager-slave2.out
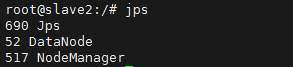
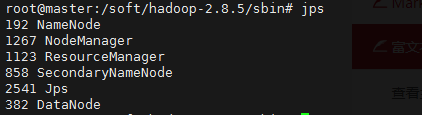
在每个节点上执行jps命令,结果如下:
master节点
slave1

slave2