Hotspot JNIEnv API详解(二)
目录
一、字符串操作
1、常见的编码格式
2、乱码问题根源
3、字符串API
4、jni_NewString和jni_NewStringUTF源码解析
二、数组操作
三、Monitor操作
四、NIO操作
五、反射支持
本篇继续上一篇《Hotspot JNIEnv API详解(一)》,总共2篇,包含JNIEnv的所有API说明及测试用例,详情可以参考
《Java Native Interface Specification Contents》。
一、字符串操作
1、常见的编码格式
标准ASCII是美国在19世纪60年代建立的英文字符和二进制的对应关系的编码规范,它能表示128个字符,其中包括英文字符、阿拉伯数字、西文字符以及32个控制字符。它用一个字节来表示具体的字符,但它只用后7位来表示字符(2^7=128),即用0-127来表示,最前面的一位统一规定为0。扩展ASCII码是用128-256来表示附加的128 个特殊符号字符、外来语字母和图形符号,最初由IBM PC制定,后面Microsoft在Windows 1.0(1985年11月发行)中制定了自己的字符集,不同语言环境的扩展ASCII码不一样。
GBK全称“汉字内码扩展规范”,英文名称:Chinese Internal Code Specification,GBK即“国标”、“扩展”汉语拼音的第一个字母,由全国信息技术标准化技术委员会1995年12月1日制订。GBK编码,是在GB2312-80标准基础上的内码扩展规范,使用了双字节编码方案,其编码范围从8140至FEFE(剔除xx7F),共23940个码位,共收录了21003个汉字,完全兼容GB2312-80标准,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,并包含了BIG5编码中的所有汉字,目前WinDows系统上默认的都是GBK编码,注意对国际标准只是支持并非兼容,即直接无法完成两者间的转换,需要人工确认两者间的对应关系,然后根据对应关系逐一转换。
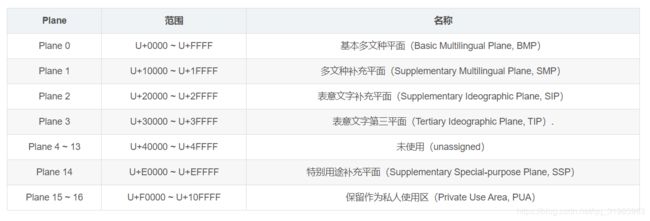
Unicode是为了满足跨语言、跨平台进行文本转换处理的要求而产生的编码规范,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,1990年开始由统一码联盟研发,1994年正式公布,目前最新版本是12.1,JDK会自动跟踪Unicode规范的演变,JDK1.8采用的Unicode版本是6.2,可以参考Character类的注释。Unicode标准最初设计的是16位固定宽度的字符编码机制,后来经过修改,允许表示超过16位的字符,合法的码点范围是U+0000 - U+10FFFF,整个编码空间划分为17个平面(plane),每个平面包2^16=65536个码点,其中0号空间叫做基本多文种平面(Basic Multilingual Plane, BMP),其中的字符叫做基本字符,其他平面叫做辅助平面(supplementary planes),其中的字符称为补充字符。各平面的范围如下:
Unicode编码规范定义了一种称为UTF-16的编码格式,UTF是Unicode Transformation Format(Unicode转换格式)的简称,16表示16位,即2个字节。其中位于BMP的字符的编码值和码点是一样的,用2个字节就可以表示,位于辅助平面的字符被编码为一对16位的码元,即用4字节表示,称作代理对(surrogate pair),具体方法是:
-
码点减去0x10000,得到的值的范围为20比特长的0x00000..0xFFFFF.
-
高位的10比特的值(值的范围为0x000..0x3FF)被加上0xD800得到第一个码元或称作高位代理(high-surrogates),其值范围是0xD800-0xDBFF。
-
低位的10比特的值(值的范围也是0x000..0x3FF)被加上0xDC00得到第二个码元或称作低位代理(low surrogate),其值的范围是0xDC00..0xDFFF.
即如果一个编码值在0xD800-0xDBFF间认为其是高位代理,编码值在0xDC00..0xDFFF认为其是低位代理从而识别出这是一个补充字符的代理对,执行反向计算可以得出代理对对应的补充字符,也因此BMP中U+D800..U+DFFF的码点不对应于任何字符。Java程序文本用的就是UTF-16的机制表示的,即当源代码文件编译成二进制的class文件时,源代码文件中的所有字符都会转换成用UTF-16表示的Unicode字符,char[],String,StringBuffer等的字符在内存中也是用UTF-16编码表示的,因此Java的char类型用两个字节表示,而C/C++中的char类型用一个字节表示,参考Chracter的类注释。
与UTF-16对应的是UTF-32,前者使用定长的2字节表示字符,后者使用定长的4字节表示字符,所以UTF-32不需要通过代理对的方式表示辅助字符,所有字符的编码值和码点一致。
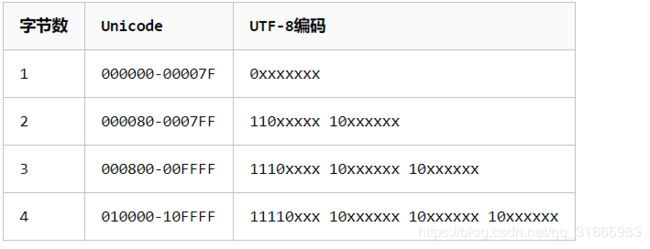
UTF-16和UTF-32都是定长的,对于使用单个字节就可以表示的字符而言就比较浪费存储空间和传输带宽了,因此制定了变长的UTF-8编码格式。UTF-8只是编码方式跟UTF-16不同,其依赖的字符集都是Unicode字符集,具体规则如下:
- ASCII码中的符号,使用单字节编码,其编码值与码点相同。其中ASCII值的范围为0~0x7F,所有编码的二进制值中第一位为0,可以据此区分单字节编码和多字节编码。
- 其它字符用多个字节来编码,假设用N个字节,第一个字节的前N位都为1,第N+1位为0,后面N-1 个字节的前两位都为10,这N个字节中其余位全部用来存储Unicode中的码位值。
如下图:
UCS编码,全称是Universal Character Set,由ISO组织制定,对应的标准是ISO 10646。1991年前后,Unicode和UCS的参与者都认识到,世界不需要两个不兼容的字符集。于是,它们开始合并双方的工作成果,并为创立一个单一编码表而协同工作,从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码。UCS的编码方式有两种,UCS-2和UCS-4,都是定长的,UTF-16是UCS-2的扩展,即增加了使用代理对表示辅助字符的机制,UTF-32是UCS-4的子集,因为ISO承诺SO 10646将不会替超出U+10FFFF的UCS-4编码赋值,所以两者是一致的。
2、乱码问题根源
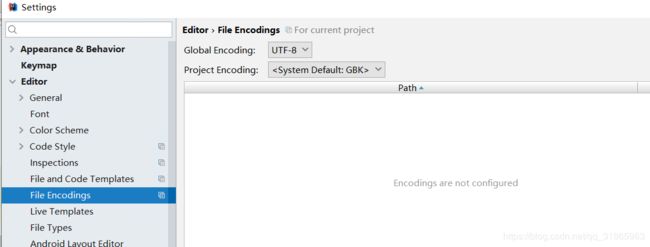
源代码文件编码是编辑器的文件编码,以IDEA为例,windows下默认是GBK,其编码设置如下图:
编译器编码是指编译器编译时源代码文件的编码,javac通过-encoding选项指定,gcc通过-finput-charset指定,默认都是UTF-8,如果编译器编码与源文件编码不一致,javac命令会报错,gcc不会报错,如下图:

执行文件编码,对Java而言就是编译生成的class文件的编码,Java规定是UTF-16,对C/C++而言就是生成的链接库或者二进制可执行文件编码,通过gcc的命令行选项fexec-charset指定,默认是UTF-8,该编码决定了源文件字符在内存中的表示方式。
测试代码C代码如下:
#include
#include
int main() {
char * str="Hello World 中文测试";
printf("%s\n",str);
printf("str len->%d\n",strlen(str));
}
注意strlen不像String.length返回的长度是字符串的字符数量,而是这个字符串经过编码后的char数组的长度,注意不包含代表字符串结束的空字符,即该字符串在内存中实际占用的内存是strlen返回的结果加1个字节。如果只是ASCII字符则两者是一样的,但是如果是中文字符,因为中文字符至少是两个字节表示所以两者不一样。测试代码的执行文件编码依次指定成UTF-8和GBK,然后运行可执行文件,结果如下:
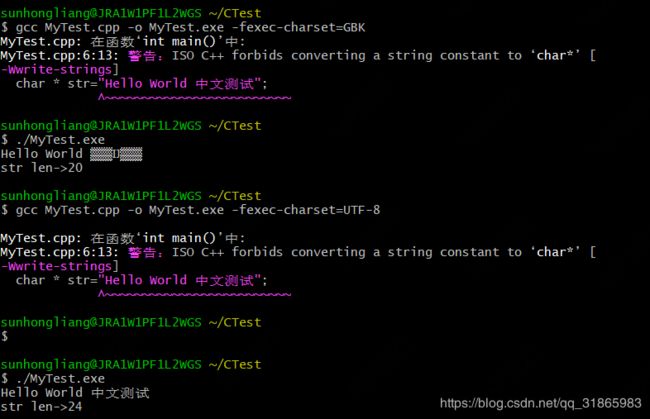
同一个字符串在不同执行文件编码下的char数组的长度是不一样的,可以用Java代码验证上述逻辑,测试用例如下:
public class MyTest {
public static void main(String[] args) throws Exception {
String test = "Hello World 中文测试";
System.out.println(test.length());
System.out.println(test.getBytes("GBK").length);
System.out.println(test.getBytes("UTF-8").length);
System.out.println(test.getBytes("UTF-16").length);
System.out.println(test.getBytes("UTF-32").length);
}
}执行结果如下:

字符串的字符数量是16,在GBK下字节数是20,在UTF-8下字节数是24,与C代码的测试结论一致。
运行环境编码,即控制台或者命令行终端的编码,上述C测试用例中如果执行文件编码为GBK,则打印的中文字符为乱码,而执行文件编码为UTF-8则不会乱码,这是因为cygwin和Linux默认是UTF-8编码的。在cygwin可以在外框处点击右键options,然后修改控制台编码,如下图:
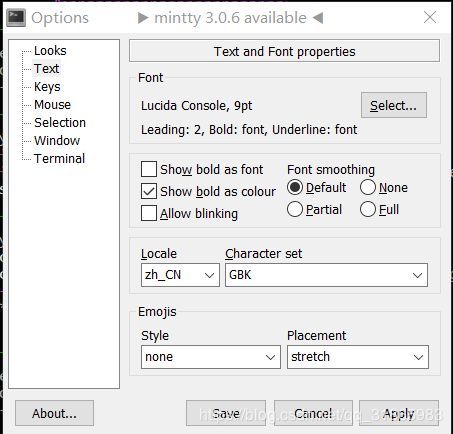
再次以GBK作为执行文件编码编译并执行,结果如下:

编译报错用的是源文件的UTF-8编码,所以这里是乱码,执行的时候没有乱码。
Java的控制台打印跟C/C++不一样,Java的执行编码固定为UTF-16,打印到控制台时输出的编码就是由file.encoding选项指定系统默认编码,windows默认是GBK,Linux下默认是UTF-8,控制台的编码必须与系统默认编码一致,否则控制台显示的是乱码,系统默认编码的逻辑在Charset中,如下图:

测试用例如下:
import java.nio.charset.Charset;
public class MyTest {
public static void main(String[] args) throws Exception {
String test = "Hello World 中文测试";
System.out.println(Charset.defaultCharset().displayName());
System.out.println(test);
}
}编译完成后,执行java命令时可以分别指定file.encoding为UTF-8和GBK观察,先是控制台默认的UTF-8,如下:

接着将控制台编码调整成GBK,测试结果如下:

3、字符串API
Java内部使用UTF-16来表示字符,JNI允许使用UTF-16的字符串构建java.lang.String对象,也允许使用UTF-8字符串构建java.lang.String对象。但是JNI使用改良版的UTF-8字符串,与标准UTF-8主要有两个不同,第一个表示null的char 0被编译成2个字节而非一个字节,这表示改良版的UTF-8编码不会有嵌入的null字符;第二个,改良版的UTF-8只使用1个,2个或者3个字节形式的UTF-8字符编码,不支持4字节形式的,会使用替代的1或者2或者3字节形式的编码。
相关API如下:
- jstring NewString(JNIEnv *env, const jchar *unicodeChars,jsize len); 用UTF-16字符数组构建一个jstringjsize
- GetStringLength(JNIEnv *env, jstring string); 获取UTF-16字符串的字符数量
- const jchar * GetStringChars(JNIEnv *env, jstring string,jboolean *isCopy); 获取UTF-16字符串的字符数组,如果isCopy不是NULL,则当JVM返回的字符数组是复制自字符串时,isCopy被置为TRUE,如果是返回指向字符串的一个指针时,则isCopy被置为FALSE
- void ReleaseStringChars(JNIEnv *env, jstring string,const jchar *chars); 通知JVM释放chars指向的字符数组
- void GetStringRegion(JNIEnv *env, jstring str, jsize start, jsize len, jchar *buf);将str中指定范围的字符复制到buf中
- const jchar * GetStringCritical(JNIEnv *env, jstring string, jboolean *isCopy);
- void ReleaseStringCritical(JNIEnv *env, jstring string, const jchar *carray); 这两个方法的用途同GetStringChars和ReleaseStringCritical,不同的是这两个方法的使用更严格。这两个方法中间的区域称为关键区,关键区内不能调用其他的JNI方法,不能执行类似读取文件这类会阻塞当前线程的操作。
上面的API都是针对UTF-16字符串,针对通用的UTF-8字符串的API如下,函数的功能都一样,最大的变化就是从jchar换成了char:
- jstring NewStringUTF(JNIEnv *env, const char *bytes); 使用UTF-8编码后的char数组构建一个新的java.lang.String对象
- jsize GetStringUTFLength(JNIEnv *env, jstring string); 返回一个字符串用UTF-8编码后的字符数组的长度,因为UTF-8是变长的,所以字符数组的长度不一定等于字符的长度
- const char * GetStringUTFChars(JNIEnv *env, jstring string,jboolean *isCopy); 获取一个字符串用UTF-8编码后的字符数组,同GetStringChars,可以通过isCopy判断返回的字符数组是否复制自原数组
- void ReleaseStringUTFChars(JNIEnv *env, jstring string,const char *utf); 通知JVM释放utf指向的字符数组
- void GetStringUTFRegion(JNIEnv *env, jstring str, jsize start, jsize len, char *buf); 将str中指定范围的UTF-16字符用UTF-8编码后复制到buf中
测试代码如下:
package jni;
public class StringTest {
static
{
System.load("/home/openjdk/cppTest/StringTest.so");
}
public static native void stringTest(String test);
public static void printStr(String test){
System.out.println("str length:"+test.length());
System.out.println("str:"+test);
}
public static void main(String[] args) {
String test="Hello World 中文测试";
stringTest(test);
printStr(test);
}
}#include "StringTest.h"
#include
#include
int unicode_length(const char* str);
void convert_to_unicode(const char* utf8_str, jchar* unicode_str, int unicode_length);
char* next(const char* str, jchar* value);
int utf8_length(const jchar* base, int length);
u_char* utf8_write(u_char* base, jchar ch);
char* convert_to_utf8(const jchar* base, u_char* result,int length);
JNIEXPORT void JNICALL Java_jni_StringTest_stringTest
(JNIEnv * env, jclass jcl, jstring jstr){
jsize size=env->GetStringLength(jstr);
printf("GetStringLength length->%d\n",size);
jsize size2=env->GetStringUTFLength(jstr);
printf("GetStringUTFLength length->%d\n",size2);
jboolean isCopy=1;
const jchar* jcharStr=env->GetStringChars(jstr, &isCopy);
jstring testStr=env->NewString(jcharStr+2, size-4);
const char* charStr=env->GetStringUTFChars(testStr,&isCopy);
printf("GetStringChars str->%s,isCopy->%d\n",charStr,isCopy);
int utf8_len=utf8_length(jcharStr, (int)size)+1;
u_char * utf8Char=(u_char*)malloc(sizeof(u_char)*utf8_len);
convert_to_utf8(jcharStr, utf8Char, size);
printf("convert_to_utf8 Test str->%s\n",utf8Char);
free(utf8Char);
//ReleaseStringChars底层调用的还是free,因此jcharStr不会变成NULL,只是其指向的内存被标记成释放了,继续访问结果不确定
env->ReleaseStringChars(jstr, jcharStr);
printf("ReleaseStringChars str->%d\n",jcharStr==NULL);
jstring testStr2=env->NewStringUTF(charStr+2);
//释放charStr原来指向的字符串
env->ReleaseStringUTFChars(testStr, charStr);
//重新赋值
charStr=env->GetStringUTFChars(testStr2,&isCopy);
printf("GetStringUTFChars str->%s,isCopy->%d\n",charStr,isCopy);
env->ReleaseStringUTFChars(testStr2, charStr);
printf("ReleaseStringUTFChars str->%s\n",charStr);
jchar newJcharStr[4]={};
env->GetStringRegion(jstr, 11, 4, newJcharStr);
testStr=env->NewString(newJcharStr, 4);
charStr=env->GetStringUTFChars(testStr,&isCopy);
printf("GetStringRegion str->%s,isCopy->%d\n",charStr,isCopy);
env->ReleaseStringUTFChars(testStr, charStr);
char newCharStr[4]={};
//注意底层实现不会校验newCharStr的长度是否够,调用方需要确保足够的容量
env->GetStringUTFRegion(jstr, 11, 4, newCharStr);
printf("GetStringUTFRegion str->%s\n",newCharStr);
jmethodID printTestId=env->GetStaticMethodID(jcl, "printStr", "(Ljava/lang/String;)V");
char* newStr="NewStringTest 中文测试";
//创建新字符串,可执行编码必须是UTF-8,否则打印的是乱码
jstring test=env->NewStringUTF(newStr);
env->CallStaticVoidMethod(jcl, printTestId,test);
int len=unicode_length(newStr);
jchar* unicodeChar=(jchar*)malloc(len*sizeof(jchar));
convert_to_unicode(newStr, unicodeChar, len);
//使用NewString的话需要手动将UTF-8字符串转换成UTF-16字符串
test=env->NewString(unicodeChar,(jsize)len);
printf("convert_to_unicode test\n");
env->CallStaticVoidMethod(jcl, printTestId,test);
free(unicodeChar);
if(env->ExceptionCheck()){
env->ExceptionDescribe();
}
}
int unicode_length(const char* str) {
int num_chars = 0;
for (const char* p = str; *p; p++) {
if (((*p) & 0xC0) != 0x80) {
num_chars++;
}
}
return num_chars;
}
void convert_to_unicode(const char* utf8_str, jchar* unicode_str, int unicode_length) {
unsigned char ch;
const char *ptr = utf8_str;
int index = 0;
/* ASCII case loop optimization */
for (; index < unicode_length; index++) {
if((ch = ptr[0]) > 0x7F) { break; }
unicode_str[index] = ch;
ptr = (const char *)(ptr + 1);
}
for (; index < unicode_length; index++) {
ptr = next(ptr, &unicode_str[index]);
}
}
char* next(const char* str, jchar* value) {
unsigned const char *ptr = (const unsigned char *)str;
unsigned char ch, ch2, ch3;
int length = -1; /* bad length */
jchar result;
switch ((ch = ptr[0]) >> 4) {
default:
result = ch;
length = 1;
break;
case 0x8: case 0x9: case 0xA: case 0xB: case 0xF:
/* Shouldn't happen. */
break;
case 0xC: case 0xD:
/* 110xxxxx 10xxxxxx */
if (((ch2 = ptr[1]) & 0xC0) == 0x80) {
unsigned char high_five = ch & 0x1F;
unsigned char low_six = ch2 & 0x3F;
result = (high_five << 6) + low_six;
length = 2;
break;
}
break;
case 0xE:
/* 1110xxxx 10xxxxxx 10xxxxxx */
if (((ch2 = ptr[1]) & 0xC0) == 0x80) {
if (((ch3 = ptr[2]) & 0xC0) == 0x80) {
unsigned char high_four = ch & 0x0f;
unsigned char mid_six = ch2 & 0x3f;
unsigned char low_six = ch3 & 0x3f;
result = (((high_four << 6) + mid_six) << 6) + low_six;
length = 3;
}
}
break;
} /* end of switch */
if (length <= 0) {
*value = ptr[0]; /* default bad result; */
return (char*)(ptr + 1); // make progress somehow
}
*value = result;
// The assert is correct but the .class file is wrong
// assert(UNICODE::utf8_size(result) == length, "checking reverse computation");
return (char *)(ptr + length);
}
int utf8_length(const jchar* base, int length) {
int result = 0;
for (int index = 0; index < length; index++) {
jchar c = base[index];
if ((0x0001 <= c) && (c <= 0x007F)) result += 1;
else if (c <= 0x07FF) result += 2;
else result += 3;
}
return result;
}
u_char* utf8_write(u_char* base, jchar ch) {
if ((ch != 0) && (ch <=0x7f)) {
base[0] = (u_char) ch;
return base + 1;
}
if (ch <= 0x7FF) {
/* 11 bits or less. */
unsigned char high_five = ch >> 6;
unsigned char low_six = ch & 0x3F;
base[0] = high_five | 0xC0; /* 110xxxxx */
base[1] = low_six | 0x80; /* 10xxxxxx */
return base + 2;
}
/* possibly full 16 bits. */
char high_four = ch >> 12;
char mid_six = (ch >> 6) & 0x3F;
char low_six = ch & 0x3f;
base[0] = high_four | 0xE0; /* 1110xxxx */
base[1] = mid_six | 0x80; /* 10xxxxxx */
base[2] = low_six | 0x80; /* 10xxxxxx */
return base + 3;
}
char* convert_to_utf8(const jchar* base, u_char* result,int length) {
u_char* p = result;
for (int index = 0; index < length; index++) {
p = utf8_write(p, base[index]);
}
*p = '\0';
return (char*) result;
}
上述示例中UTF-16编码和UTF-8编码之间的转换的代码参考hotspot/src/share/vm/utilities/utf8.cpp,在此基础上稍作调整。
上述示例在默认的可执行编码为UTF-8的情况下不会乱码,输出如下:
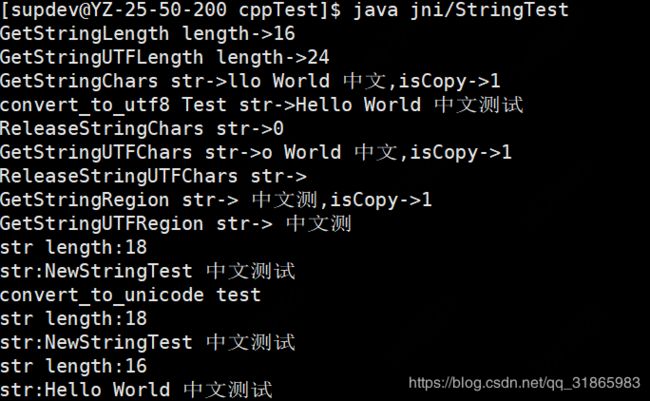
当通过-fexec-charset=GBK显示设置执行编码后出现乱码了,由本地代码直接定义的字符串都是乱码,从Java方法传进来的字符串没有乱码,如下图:
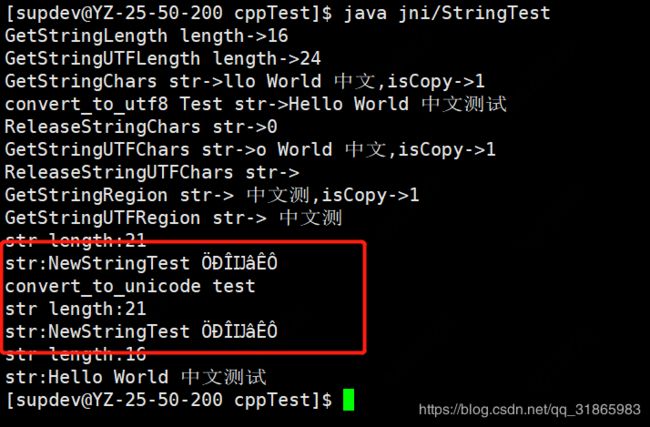
即JNI编译成动态链接库时为了避免乱码问题,必须使用默认的UTF-8编码。
4、jni_NewString和jni_NewStringUTF源码解析
为了进一步了解Java字符串在内存中的表示机制,可以从这两个入口方法开始研究,这两个方法的实现都在jni.cpp中,源码如下:
JNI_ENTRY(jstring, jni_NewString(JNIEnv *env, const jchar *unicodeChars, jsize len))
jstring ret = NULL;
oop string=java_lang_String::create_oop_from_unicode((jchar*) unicodeChars, len, CHECK_NULL);
ret = (jstring) JNIHandles::make_local(env, string);
return ret;
JNI_END
JNI_ENTRY(jstring, jni_NewStringUTF(JNIEnv *env, const char *bytes))
jstring ret;
oop result = java_lang_String::create_oop_from_str((char*) bytes, CHECK_NULL);
ret = (jstring) JNIHandles::make_local(env, result);
return ret;
JNI_END即创建jstring的核心实现都在java_lang_String这个类中,这个类的定义在hotspot/src/share/vm/classfile/javaClasses.hpp中,实现在同目录下的javaClasses.cpp中,这个文件定义的都是JVM本身会经常用到的Java类的快捷操作方法,如这里的创建String对象,如下图:
create_oop_from_str和create_oop_from_unicode两者的源码如下:
Handle java_lang_String::basic_create(int length, TRAPS) {
assert(initialized, "Must be initialized");
oop obj;
//创建一个java.lang.String对象
obj = InstanceKlass::cast(SystemDictionary::String_klass())->allocate_instance(CHECK_NH);
Handle h_obj(THREAD, obj);
typeArrayOop buffer;
//创建一个jchar数组
buffer = oopFactory::new_charArray(length, CHECK_NH);
obj = h_obj();
//设置String对象的value属性和count属性
set_value(obj, buffer);
assert(offset(obj) == 0, "initial String offset should be zero");
set_count(obj, length);
return h_obj;
}
Handle java_lang_String::create_from_unicode(jchar* unicode, int length, TRAPS) {
Handle h_obj = basic_create(length, CHECK_NH);
typeArrayOop buffer = value(h_obj());
for (int index = 0; index < length; index++) {
//将unicode字符数组中的字符逐一保存到value属性中
buffer->char_at_put(index, unicode[index]);
}
return h_obj;
}
oop java_lang_String::create_oop_from_unicode(jchar* unicode, int length, TRAPS) {
Handle h_obj = create_from_unicode(unicode, length, CHECK_0);
return h_obj();
}
Handle java_lang_String::create_from_str(const char* utf8_str, TRAPS) {
if (utf8_str == NULL) {
return Handle();
}
//获取UTF-8字符串中的Unicode字符数
int length = UTF8::unicode_length(utf8_str);
Handle h_obj = basic_create(length, CHECK_NH);
if (length > 0) {
//将utf-8字符串逐一转换成unicode,并保存在value属性中
UTF8::convert_to_unicode(utf8_str, value(h_obj())->char_at_addr(0), length);
}
return h_obj;
}
oop java_lang_String::create_oop_from_str(const char* utf8_str, TRAPS) {
Handle h_obj = create_from_str(utf8_str, CHECK_0);
return h_obj();
}从上述源码可以进一步确认Java字符串在内存中就是一个Unicode字符数组,即用UTF-16编码的单个字符占两字节的short数组,这种方式相比UTF-8要占用更多的内存,但是能够加快字符本身相关计算的速度,如排序,比较等,省掉了UTF-8到Unicode的中间转换。
二、数组操作
数组API说明如下:
- jsize GetArrayLength(JNIEnv *env, jarray array); 获取字符串长度,适用于所有元素类型的数组
- jobjectArray NewObjectArray(JNIEnv *env, jsize length,jclass elementClass, jobject initialElement); 创建一个指定长度length和指定类型elementClass的数组,initialElement为该数组的0号元素
- jobject GetObjectArrayElement(JNIEnv *env,jobjectArray array, jsize index); 获取指定索引index处的数组元素
- void SetObjectArrayElement(JNIEnv *env, jobjectArray array,jsize index, jobject value); 将数组的指定索引index的元素设置为指定对象value
注意上述API除GetArrayLength外都是针对对象数组,对int等基本类型的数组的API如下:
- ArrayType New
Array(JNIEnv *env, jsize length); 创建一个指定长度length的基本类型数组,ArrayType与PrimitiveType的对应关系如下:

- NativeType *Get
ArrayElements(JNIEnv *env,ArrayType array, jboolean *isCopy); 获取基本类型数组的元素数组,isCopy表示返回的元素数组是否复制自原数组,如果是复制自原数组则isCopy被设置成1,否则设置成false。返回的数组指针一直是有效的,直到调用了Release <PrimitiveType>ArrayElements()方法。对返回的数组元素的修改不会同步到原数组,除非调用了ReleaseArrayElements方法。NativeType,PrimitiveType和ArrayType三者的对应关系如下:

- void Release
ArrayElements(JNIEnv *env,ArrayType array, NativeType *elems, jint mode); 通知JVM本地代码不在需要elems指向的数组,如果elems不是原数组array的一份复制则后面的mode参数无效。mode有三个取值,通常传递0,这时程序会将elems指向的数组元素写回到原数组array,即对elems的修改会同步到原数组array,然后释放掉elems占用的内存。mode另外两个选项分别是JNI_COMMIT和JNI_ABORT,JNI_COMMIT也会将elems写回到array中,但是不会释放elems占用的内存,JNI_ABORT与之相反,会释放elems占用的内存,但是不会将elems写回到array中。NativeType,PrimitiveType和ArrayType三者的对应关系同上。 - void Get
ArrayRegion(JNIEnv *env, ArrayType array,jsize start, jsize len, NativeType *buf); 将基本类型数组的一部分元素拷贝到对应的JNI元素类型数组中。NativeType,PrimitiveType和ArrayType三者的对应关系如下:

- void Set
ArrayRegion(JNIEnv *env, ArrayType array,jsize start, jsize len, const NativeType *buf);将与基本类型元素数组对应的JNI元素类型数组的值写回到基本类型元素数组中。NativeType,PrimitiveType和ArrayType三者的对应关系同上。 - void * GetPrimitiveArrayCritical(JNIEnv *env, jarray array, jboolean *isCopy);
- void ReleasePrimitiveArrayCritical(JNIEnv *env, jarray array, void *carray, jint mode); 这两个函数的功能和Get/Release
ArrayElements基本一样,不过跟字符串操作Get/ReleaseStringCritical一样,这两个函数必须配合使用,这两个函数构成一个关键区,在关键区内的代码不能调用其他的JNI函数,也不能执行任何可能导致当前线程阻塞的操作,如读取文件等。
测试用例如下:
package jni;
public class ArrayTest {
static {
System.load("/home/openjdk/cppTest/ArrayTest.so");
}
public native static void primArrayTest(int[] a);
public native static void objArrayTest(String[] a);
public static void main(String[] args) {
primArrayTest(new int[]{1,2,3,4,5,6,7,8,9});
System.out.println("================================");
objArrayTest(new String[]{"a","b","c","d","e"});
}
}
#include "ArrayTest.h"
#include
JNIEXPORT void JNICALL Java_jni_ArrayTest_primArrayTest
(JNIEnv * env, jclass jcl, jintArray intArray){
jboolean iscopy=1;
jsize len=env->GetArrayLength(intArray);
printf("GetArrayLength len->%d\n",len);
jint * intptr=env->GetIntArrayElements(intArray,&iscopy);
printf("GetIntArrayElements int[2]->%d,iscopy->%d\n",intptr[2],iscopy);
intptr[2]=22;
jclass arraysCls=env->FindClass("java/util/Arrays");
jmethodID convertIntArraysId=env->GetStaticMethodID(arraysCls,"toString","([I)Ljava/lang/String;");
jstring result=(jstring)env->CallStaticObjectMethod(arraysCls,convertIntArraysId,intArray);
const char* resultStr=env->GetStringUTFChars(result,&iscopy);
printf("no release modify result->%s,iscopy->%d\n",resultStr,iscopy);
//释放完后intptr对应的复制数组被释放了,但是依然可以通过intptr访问
env->ReleaseIntArrayElements(intArray,intptr,0);
printf("ReleaseIntArrayElements int[2]->%d\n",intptr[2]);
result=(jstring)env->CallStaticObjectMethod(arraysCls,convertIntArraysId,intArray);
resultStr=env->GetStringUTFChars(result,&iscopy);
printf("ReleaseIntArrayElements modify result->%s\n",resultStr);
jint intArrayTest[4]={};
env->GetIntArrayRegion(intArray,3,4,intArrayTest);
jintArray jintArrayTest=env->NewIntArray(4);
env->SetIntArrayRegion(jintArrayTest,0,4,intArrayTest);
result=(jstring)env->CallStaticObjectMethod(arraysCls,convertIntArraysId,jintArrayTest);
resultStr=env->GetStringUTFChars(result,&iscopy);
printf("SetIntArrayRegion result->%s\n",resultStr);
}
JNIEXPORT void JNICALL Java_jni_ArrayTest_objArrayTest
(JNIEnv * env, jclass jcl, jobjectArray objArray){
jboolean iscopy=1;
jsize len=env->GetArrayLength(objArray);
printf("GetArrayLength len->%d\n",len);
jobject obj=env->GetObjectArrayElement(objArray,0);
jclass stringCls=env->FindClass("java/lang/String");
jboolean result=env->IsInstanceOf(obj,stringCls);
printf("IsInstanceOf result->%d\n",result);
if(result){
jstring str=(jstring)obj;
const char* charStr=env->GetStringUTFChars(str,&iscopy);
printf("str[0] result->%s,iscopy->%d\n",charStr,iscopy);
jstring s=env->NewStringUTF("test");
jstring s2=env->NewStringUTF("test2");
env->SetObjectArrayElement(objArray,2,s);
env->SetObjectArrayElement(objArray,3,s2);
jclass arraysCls=env->FindClass("java/util/Arrays");
jmethodID convertIntArraysId=env->GetStaticMethodID(arraysCls,"toString","([Ljava/lang/Object;)Ljava/lang/String;");
jstring result=(jstring)env->CallStaticObjectMethod(arraysCls,convertIntArraysId,objArray);
const char* resultStr=env->GetStringUTFChars(result,&iscopy);
printf("modify result->%s\n",resultStr);
jobjectArray newObjArray=env->NewObjectArray(2,stringCls,s);
env->SetObjectArrayElement(newObjArray,1,s2);
result=(jstring)env->CallStaticObjectMethod(arraysCls,convertIntArraysId,newObjArray);
resultStr=env->GetStringUTFChars(result,&iscopy);
printf("newObjArray result->%s,iscopy->%d\n",resultStr,iscopy);
}
} 三、Monitor操作
Monitor相关API如下:
- jint MonitorEnter(JNIEnv *env, jobject obj); 获取一个对象监视锁,obj不能为空,返回0表示获取成功,返回负数表示获取失败。如果obj的对象监视锁已经被占用,则当前线程会一直等待直到锁被释放并抢占成功。获取成功后可以重复获取,对象监视锁会维护一个成功获取次数,每次成功获取都会增加该次数,调用MonitorExit会减少该次数,当次数变成0会释放该对象监视锁。注意通过MonitorEnter获取的对象监视锁不能通过monitorexit指令(该指令对应synchronized 关键字)释放,只能通过MonitorExit或者DetachCurrentThread释放。
- jint MonitorExit(JNIEnv *env, jobject obj); 减少当前线程成功获取对象监视锁的次数,当次数变成0时,释放当前线程占用的对象监视锁。注意不能使用MonitorExit释放通过synchronized关键字或者monitorenter 虚拟机指令获取的对象监视锁。
测试用例如下:
package jni;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.CyclicBarrier;
public class MonitorTest {
static
{
System.load("/home/openjdk/cppTest/MonitorTest.so");
}
public static native void monitorTest(Object test);
public static void main(String[] args) throws Exception{
CyclicBarrier cyclicBarrier=new CyclicBarrier(5);
CountDownLatch countDownLatch=new CountDownLatch(5);
Object monitor=new Object();
System.out.println("begin test");
for(int i=0;i<5;i++){
MonitorTest.Worker worker=new Worker(monitor,cyclicBarrier,countDownLatch);
worker.start();
}
countDownLatch.await();
System.out.println("end test");
}
static class Worker extends Thread{
private Object monitor;
private CyclicBarrier cyclicBarrier;
private CountDownLatch countDownLatch;
public Worker(Object monitor,CyclicBarrier cyclicBarrier,CountDownLatch countDownLatch) {
this.monitor = monitor;
this.cyclicBarrier=cyclicBarrier;
this.countDownLatch=countDownLatch;
}
@Override
public void run() {
super.run();
try {
System.out.println("等待执行,thread ID->"+Thread.currentThread().getName());
cyclicBarrier.await();
System.out.println("开始执行,thread ID->"+Thread.currentThread().getName());
monitorTest(monitor);
System.out.println("执行完成,thread ID->"+Thread.currentThread().getName());
countDownLatch.countDown();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}#include "MonitorTest.h"
#include
JNIEXPORT void JNICALL Java_jni_MonitorTest_monitorTest(JNIEnv * env,
jclass jcl, jobject obj) {
jclass threadJcl = env->FindClass("java/lang/Thread");
jmethodID currentThreadId = env->GetStaticMethodID(threadJcl,
"currentThread", "()Ljava/lang/Thread;");
jmethodID getNameId=env->GetMethodID(threadJcl, "getName", "()Ljava/lang/String;");
jmethodID sleepId = env->GetStaticMethodID(threadJcl, "sleep",
"(J)V");
jobject currentThreadObj=env->CallStaticObjectMethod(threadJcl, currentThreadId);
jstring threadName=(jstring)env->CallObjectMethod(currentThreadObj, getNameId);
const char * threadNameStr=env->GetStringUTFChars(threadName, NULL);
for (int i = 0; i < 5; i++) {
jint result = env->MonitorEnter(obj);
if (result == 0) {
printf("MonitorEnter succ,result->%d,threadName->%s\n", result,threadNameStr);
env->CallStaticVoidMethod(jcl, sleepId, 1000);
result = env->MonitorExit(obj);
printf("MonitorExit,result->%d,threadName->%s\n", result,threadNameStr);
break;
}
}
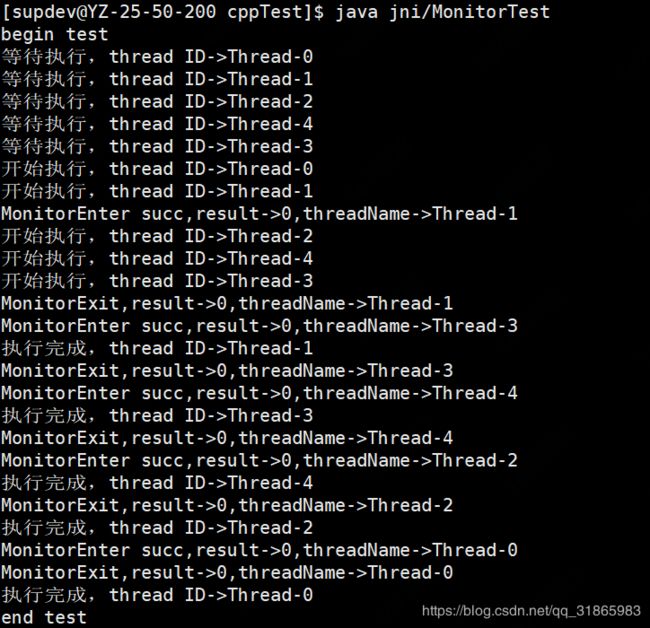
} 测试的输出如下:
四、NIO操作
NIO相关API一共3个,是JDK1.4引入的,所有JVM实现必须提供这三个方法,但是不一定实现了,如果未实现则返回NULL或者-1。这三个方法只能操作DirectByteBuffer,只有他才有保存对应内存地址的address属性,GetDirectBufferAddress方法返回的实际就是该属性的值。具体如下:
- jobject NewDirectByteBuffer(JNIEnv* env, void* address, jlong capacity); 使用指定内存地址和内存大小的一块内存创建一个 java.nio.ByteBuffer对象,该对象可以返回给Java代码,允许java代码读写该内存。如果该块内存是无效的则java代码读写该内存的行为是不确定的,有可能抛出异常,也可能无任何影响。该方法的底层实际DirectByteBuffer(long addr, int cap)构造方法。
- void* GetDirectBufferAddress(JNIEnv* env, jobject buf); 获取java.nio.Buffer对应内存的内存地址,此方法允许本地代码直接操作Buffer对应的内存,该方法的底层实际返回DirectByteBuffer的address的属性值。
- jlong GetDirectBufferCapacity(JNIEnv* env, jobject buf); 获取java.nio.Buffer对应内存的内存容量,此方法的底层实际返回DirectByteBuffer的capacity属性值。
测试代码如下:
package jni;
import java.nio.Buffer;
import java.nio.ByteBuffer;
import java.nio.ByteOrder;
public class NIOTest {
static
{
System.load("/home/openjdk/cppTest/NIOTest.so");
}
public static native void test(Buffer test);
public static void print(ByteBuffer test){
test.order(ByteOrder.LITTLE_ENDIAN);
System.out.println("position->"+test.position()+",limit->"+test.limit());
while (test.hasRemaining()){
System.out.println(test.getInt());
}
}
public static void main(String[] args) {
ByteBuffer byteBuffer=ByteBuffer.allocateDirect(4*5);
//put时默认按照BIG_ENDIAN的方式存储,读取的时候必须保持一致,否则读取的值是错误的
//这里为了跟本地代码的默认行为保持一致,使用LITTLE_ENDIAN存储
byteBuffer.order(ByteOrder.LITTLE_ENDIAN);
byteBuffer.putInt(1);
byteBuffer.putInt(2);
byteBuffer.putInt(3);
byteBuffer.putInt(4);
byteBuffer.putInt(5);
byteBuffer.flip();
print(byteBuffer);
byteBuffer.flip();
test(byteBuffer);
}
}
#include
#include "NIOTest.h"
JNIEXPORT void JNICALL Java_jni_NIOTest_test
(JNIEnv * env, jclass jcl, jobject obj){
jlong size=env->GetDirectBufferCapacity(obj);
printf("GetDirectBufferCapacity size->%d\n",size);
//C/C++默认是按照小端的方式存储,而java.nio.ByteBuffer默认按照大端的方式存储,参考ByteBuffer的注释
//为了确保两者一致,应该在Java中对ByteBuffer实例执行order(ByteOrder.LITTLE_ENDIAN);
int * test=(int *)env->GetDirectBufferAddress(obj);
test[0]=11;
test[1]=12;
test[2]=13;
test[3]=14;
test[4]=15;
jmethodID printId=env->GetStaticMethodID(jcl, "print", "(Ljava/nio/ByteBuffer;)V");
printf("GetDirectBufferAddress\n");
env->CallStaticVoidMethod(jcl, printId,obj);
int test2[]={21,22,23,24};
//底层调用的是DirectByteBuffer(long addr, int cap)构造方法,该方法自动将cap设置为limit,position设置为0
jobject obj2=env->NewDirectByteBuffer(test2, sizeof(int)*4);
printf("NewDirectByteBuffer\n");
env->CallStaticVoidMethod(jcl, printId,obj2);
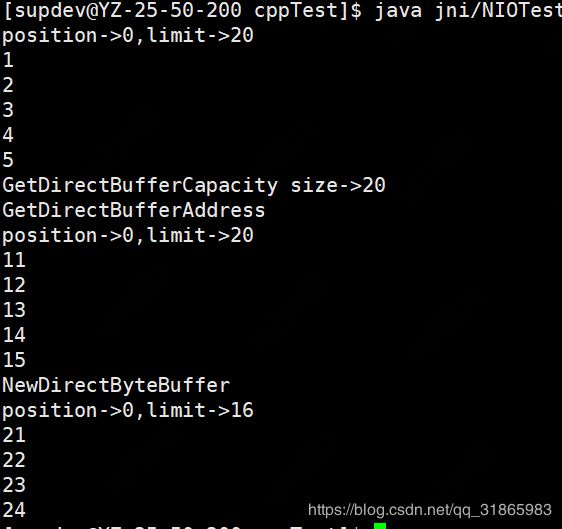
} 测试结果如下:
五、反射支持
这些API是提供给Java反射核心API使用的工具方法,用于将Java反射的类转换成jmethodID或者 jfieldID,具体如下:
- jmethodID FromReflectedMethod(JNIEnv *env, jobject method); 将java.lang.reflect.Method 或者java.lang.reflect.Constructor类实例转换成 jmethodID
- jfieldID FromReflectedField(JNIEnv *env, jobject field); 将java.lang.reflect.Field 转换成jfieldID
- jobject ToReflectedMethod(JNIEnv *env, jclass cls,jmethodID methodID, jboolean isStatic); 将某个类的jmethodID 转换成java.lang.reflect.Method 或者java.lang.reflect.Constructor类实例,如果该方法是静态方法则isStatic传JNI_TRUE,否则传入JNI_FALSE
- jobject ToReflectedField(JNIEnv *env, jclass cls,jfieldID fieldID, jboolean isStatic); 将某个类的jfieldID 转换成java.lang.reflect.Field ,如果该字段是静态字段则isStatic传JNI_TRUE,否则传入JNI_FALSE
测试用例如下:
package jni;
import java.lang.reflect.Field;
import java.lang.reflect.Method;
public class ReflectTest {
static
{
System.load("/home/openjdk/cppTest/ReflectTest.so");
}
public int a;
public static int a2;
public void say(){
System.out.println("say");
}
public static void say2(){
System.out.println("static say2");
}
public void print(ReflectTest test){
System.out.println("ReflectTest a->"+test.a);
}
public native Method test(Method test);
public native Field test(Field test);
public static void main(String[] args) throws Exception {
ReflectTest reflectTest=new ReflectTest();
Method method=ReflectTest.class.getMethod("say");
method=reflectTest.test(method);
method.invoke(null);
Field field=ReflectTest.class.getField("a");
field=reflectTest.test(field);
field.setInt(null,21);
System.out.println(ReflectTest.a2);
}
}#include
#include "ReflectTest.h"
JNIEXPORT jobject JNICALL Java_jni_ReflectTest_test__Ljava_lang_reflect_Method_2
(JNIEnv * env, jobject obj, jobject param){
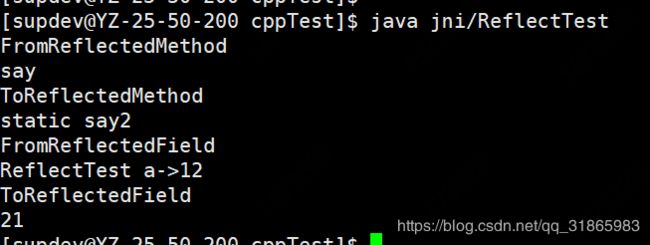
jmethodID sayId=env->FromReflectedMethod(param);
printf("FromReflectedMethod\n");
env->CallVoidMethod(obj, sayId);
jclass jcl=env->GetObjectClass(obj);
jmethodID say2Id=env->GetStaticMethodID(jcl, "say2", "()V");
jobject result= env->ToReflectedMethod(jcl, say2Id, JNI_TRUE);
printf("ToReflectedMethod\n");
return result;
}
JNIEXPORT jobject JNICALL Java_jni_ReflectTest_test__Ljava_lang_reflect_Field_2
(JNIEnv *env, jobject obj, jobject param){
jfieldID aId=env->FromReflectedField(param);
env->SetIntField(obj, aId, 12);
printf("FromReflectedField\n");
jclass jcl=env->GetObjectClass(obj);
jmethodID printId=env->GetMethodID(jcl, "print", "(Ljni/ReflectTest;)V");
env->CallVoidMethod(obj, printId,obj);
jfieldID a2Id=env->GetStaticFieldID(jcl, "a2", "I");
jobject result=env->ToReflectedField(jcl, a2Id, JNI_TRUE);
printf("ToReflectedField\n");
return result;
} 测试输出如下: