TensorFlow实现迁移学习(附思维导图与代码)
看了李宏毅的机器学习视频和莫凡的TensorFlow视频,对迁移学习的理解其实就是为了偷懒, 在训练好了的模型上接着训练其他内容, 充分使用原模型的理解力”. 有时候也是为了避免再次花费特别长的时间重复训练大型模型.
本文根据《TenorFlow实战Google深度学习框架》的代码进行深度解读。
首先要先从网上下载两个文件
(1)花的数据集 http://download.tensorflow.org/example_images/flower_photos.tgz
(2)已经训练好的Inception-v3模型(书上给的url打不开,下面的是可以的,在下面选择inception_v3_2016_08_28.tar即可)
https://github.com/tensorflow/models/tree/master/research/slim
下载好的数据集没法直接用,需要将数据集解压,并且利用代码将原始代码图像数据整理成模型需要的输入数据
分割成,训练数据,验证数据和测试数据,因为代码没有特别复杂的,我就不像其他文章一样,把书上的注释带领大家读一遍了,我直接上一个思维导图(导图软件为XMind 8 Update 7,现在最新的软件是XMind 8 Pro据说不错,但是好像要钱)。
这个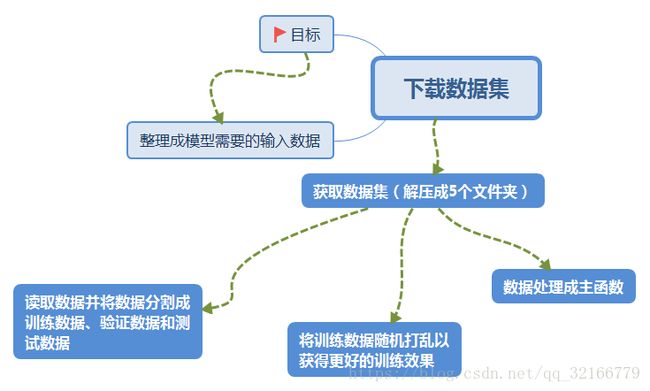
import glob
import os.path
import numpy as np
from tensorflow.python.platform import gfile
import tensorflow as tf
INPUT_DATA = 'flower_photos'
OUTPUT_FILE = 'flower_processed_data.npy'
VALIDATION_PERCENTAGE = 10
TEST_PERCENTAGE = 10
def create_image_lists(sess,testing_percentage,validation_percentage):
sub_dirs = [x[0] for x in os.walk(INPUT_DATA)]
is_root_dir = True
training_images = []
training_labels = []
testing_images = []
testing_labels = []
validation_images = []
validation_labels = []
current_label = 0
for sub_dir in sub_dirs:
if is_root_dir:
is_root_dir = False
continue
extensions = ['jpg', 'jpeg', 'JPG', 'jpeg']
file_list = []
dir_name = os.path.basename(sub_dir)
for extension in extensions:
file_glob = os.path.join(INPUT_DATA, dir_name, '*.'+extension)
file_list.extend(glob.glob(file_glob))
if not file_list:continue
for file_name in file_list:
image_raw_data = gfile.FastGFile(file_name, 'rb').read()
image = tf.image.decode_jpeg(image_raw_data)
if image.dtype != tf.float32:
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
image_value = sess.run(image)
chance = np.random.randint(100)
if chance < validation_percentage:
validation_images.append(image_value)
validation_labels.append(current_label)
elif chance < (testing_percentage + validation_percentage):
testing_images.append(image_value)
testing_images.append(current_label)
else:
training_images.append(image_value)
training_images.append(current_label)
current_label += 1
state = np.random.get_state()
np.random.shuffle(training_images)
np.random.set_state(state)
np.random.shuffle(training_labels)
return np.asarray([training_images,testing_labels,validation_images,validation_labels,testing_images,testing_labels])
def main():
with tf.Session()as sess:
processed_data = create_image_lists(sess, TEST_PERCENTAGE, VALIDATION_PERCENTAGE)
np.save(OUTPUT_FILE,processed_data)
if __name__=='__main__':
main()
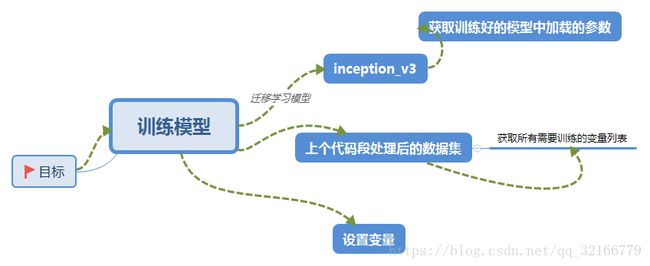
上图是在计算loss之前的步骤,计算loss方法 和我的另一篇文章差不太多,这里就不介绍了 https://blog.csdn.net/qq_32166779/article/details/83035409
import glob
import os.path
import numpy as np
import tensorflow as tf
from tensorflow.python.platform import gfile
import tensorflow.contrib.slim as slim
import tensorflow.contrib.slim.python.slim.nets.inception_v3 as inception_v3
INPUT_DATA = 'flower_processed_data.npy'
TRAIN_FILE = 'save_model1'
CKPT_FILE = 'inception_v3.ckpt'
LEARNING_RATE = 0.0001
STEPS = 300
BATCH = 32
N_CLASSES = 5
CHECKPOINT_EXCLUDE_SCOPES = 'InceptionV3/Logits,InceptionV3/Auxlogits'
TRAINNABLE_SCOPES='InceptionV3/Logits,InceptionV3/AuxLogits'
def get_tuned_variables():
exclusions = [scope.strip() for scope in CHECKPOINT_EXCLUDE_SCOPES.split(',')]
variables_to_restore= []
for var in slim.get_model_variables():
excluded = False
for exclusion in exclusions:
if var.op.name.startswith(exclusion):
excluded = True
break
if not excluded:
variables_to_restore.append(var)
return variables_to_restore
def get_trainable_variables():
scopes = [scope.strip() for scope in TRAINNABLE_SCOPES.split(',')]
variables_to_train = []
for scope in scopes:
variables = tf.get_collection(
tf.GraphKeys.TRAINABLE_VARIABLES,scope
)
variables_to_train.extend(variables)
return variables_to_train
def main(argv=None):
processed_data = np.load(INPUT_DATA)
training_images = processed_data[0]
n_training_example = len(training_images)
training_labels = processed_data[1]
validation_images = processed_data[2]
validation_labels = processed_data[3]
testing_images = processed_data[4]
testing_labels = processed_data[5]
print("%d training examples, %d validation examples adn %d""testing examples."%(n_training_example,
len(validation_labels),len(testing_labels)
))
images = tf.placeholder(tf.float32,[None, 299,299, 3])
labels = tf.placeholder(tf.int64, [None],name='labels')
with slim.arg_scope(inception_v3.inception_v3_arg_scope()):
logits, _ = inception_v3(images, num_classses=N_CLASSES)
trainable_variables = get_trainable_variables()
tf.losses.softmax_cross_entropy(tf.one.hot(labels,N_CLASSES),logits, weights=1.0)
train_step = tf.train.RMSPropOptimizer(LEARNING_RATE).minimize(tf.losses.get_total_loss())
with tf.name_scope('evaluation'):
correct_prediction = tf.equal(tf.argmax(logits,1),labels)
evaluation_step = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
load_fn = slim.assign_from_checkpoint_fn(
CKPT_FILE,
get_tuned_variables(),
ignore_missing_vars=True
)
saver = tf.train.Server()
with tf.Session()as sess:
init = tf.global_variables_initializer()
sess.run(init)
print('Loading tuned variables from %s' %CKPT_FILE)
load_fn(sess)
start = 0
end = BATCH
for i in range(STEPS):
sess.run(train_step, feed_dict={images: training_images[start:end],labels:testing_labels[start:end]})
if i % 30 == 0 or i+1 == STEPS:
saver.save(sess, TRAIN_FILE,globel_step=i)
validation_accuracy = sess.run(evaluation_step, feed_dict={images:validation_images,labels:validation_labels})
print('Step %d:Validation accuracy = %.1f%%'%(i,validation_accuracy*100.0))
start = end
if start == n_training_example:
start = 0
end = start+BATCH
if end>n_training_example:
end = n_training_example
test_accuracy = sess.run(evaluation_step, feed_dict={images:testing_images, labels:testing_labels})
print('Final test accuracy = %.1f%%' %(test_accuracy*100))
if __name__=='__main__':
tf.app.run()