序列分类问题
其中一种 RNN 结构为:N vs 1。这种结构的输入为序列,输出为类别, 因此可以解决序列分类问题。 常见的序列分类问题有文本分类 、 时间序列分类 、 音频分类。本文用tensroflow制作一个简单的序列分类器。
一、Nvs1 的 RNN结构
x1,x2,...,Xt 为输入的数据, Y 为最终的分类 。 在不同的问题中,输入 数据 x 有不同的含义,如:
(1)对于文本分类,每一个 Xt 是一个词的向量表示。
(2)对于音频分类,每一个 Xt 是一帧采样的数据 。
(3)对于视频分类,每一个 Xt 是一帧图像(或从单帧图像中提取的特征 )
Nvs1 的 RNN结构如下:
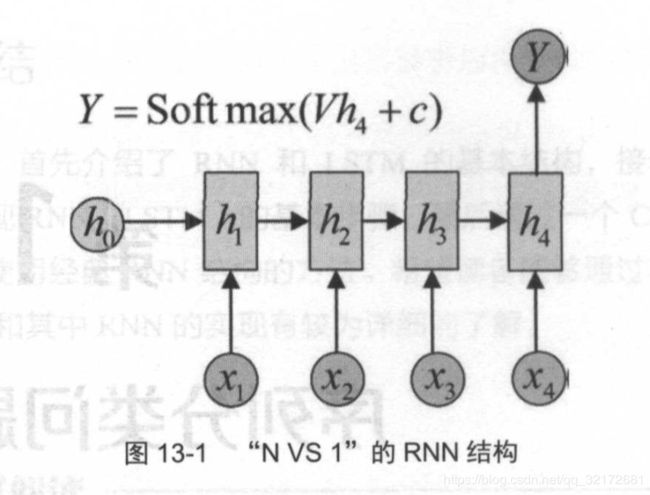
用公式来表达是:

每一次只对最后一个隐层状态 hr 计算类别 。 通常输入的序列长度都是不等长的,hr 应取对应序列的长度 。
二、序列分类问题与数据生成
先处理一个最简单的序列分类问题:数值序列分类,希望能训练一个 RNN 分类器,将这两类数列自动分开。这里数列的长度是不固定的,但它们有一个共同的最大序列长度。生产数据代码如下:
class ToySequenceData(object):
""" 生成序列数据。每个数量可能具有不同的长度。
一共生成下面两类数据
- 类别 0: 线性序列 (如 [0, 1, 2, 3,...])
- 类别 1: 完全随机的序列 (i.e. [1, 3, 10, 7,...])
注意:
max_seq_len是最大的序列长度。对于长度小于这个数值的序列,我们将会补0。
在送入RNN计算时,会借助sequence_length这个属性来进行相应长度的计算。
"""
def __init__(self, n_samples=1000, max_seq_len=20, min_seq_len=3,
max_value=1000):
self.data = []
self.labels = []
self.seqlen = []
for i in range(n_samples):
# 序列的长度是随机的,在min_seq_len和max_seq_len之间。
len = random.randint(min_seq_len, max_seq_len)
# self.seqlen用于存储所有的序列。
self.seqlen.append(len)
# 以50%的概率,随机添加一个线性或随机的序列
if random.random() < .5:
# 生成一个线性序列
rand_start = random.randint(0, max_value - len)
s = [[float(i)/max_value] for i in range(rand_start, rand_start + len)]
# 长度不足max_seq_len的需要补0
s += [[0.] for i in range(max_seq_len - len)]
self.data.append(s)
# 线性序列的label是[1, 0](因为我们一共只有两类)
self.labels.append([1., 0.])
else:
# 生成一个随机序列
s = [[float(random.randint(0, max_value))/max_value] for i in range(len)]
# 长度不足max_seq_len的需要补0
s += [[0.] for i in range(max_seq_len - len)]
self.data.append(s)
self.labels.append([0., 1.])
self.batch_id = 0
def next(self, batch_size):
"""
生成batch_size的样本。
如果使用完了所有样本,会重新从头开始。
"""
if self.batch_id == len(self.data):
self.batch_id = 0
batch_data = (self.data[self.batch_id:min(self.batch_id + batch_size, len(self.data))])
batch_labels = (self.labels[self.batch_id:min(self.batch_id + batch_size, len(self.data))])
batch_seqlen = (self.seqlen[self.batch_id:min(self.batch_id + batch_size, len(self.data))])
self.batch_id = min(self.batch_id + batch_size, len(self.data))
return batch_data, batch_labels, batch_seqlen
三、在 TensorFlow 中定义 RNN 分类模型
1、定义模型的准备工作
# 运行的参数
learning_rate = 0.01
training_iters = 1000000
batch_size = 128
display_step = 10
# 网络定义时的参数
seq_max_len = 20 # 最大的序列长度
n_hidden = 64 # 隐层的size
n_classes = 2 # 类别数
trainset = ToySequenceData(n_samples=1000, max_seq_len=seq_max_len)
testset = ToySequenceData(n_samples=500, max_seq_len=seq_max_len)
# x为输入,y为输出
# None的位置实际为batch_size
x = tf.placeholder("float", [None, seq_max_len, 1])
y = tf.placeholder("float", [None, n_classes])
# 这个placeholder存储了输入的x中,每个序列的实际长度
seqlen = tf.placeholder(tf.int32, [None])
# weights和bias在输出时会用到
weights = {
'out': tf.Variable(tf.random_normal([n_hidden, n_classes]))
}
biases = {
'out': tf.Variable(tf.random_normal([n_classes]))
}
2、定义RNN分类模型
def dynamicRNN(x, seqlen, weights, biases):
# 输入x的形状: (batch_size, max_seq_len, n_input)
# 输入seqlen的形状:(batch_size, )
# 定义一个lstm_cell,隐层的大小为n_hidden(之前的参数)
lstm_cell = tf.nn.rnn_cell.BasicLSTMCell(n_hidden)
# 使用tf.nn.dynamic_rnn展开时间维度
# 此外sequence_length=seqlen也很重要,它告诉TensorFlow每一个序列应该运行多少步
outputs, states = tf.nn.dynamic_rnn(lstm_cell, x, dtype=tf.float32,
sequence_length=seqlen)
# outputs的形状为(batch_size, max_seq_len, n_hidden)
# 如果有疑问可以参考上一章内容
# 我们希望的是取出与序列长度相对应的输出。如一个序列长度为10,我们就应该取出第10个输出
# 但是TensorFlow不支持直接对outputs进行索引,因此我们用下面的方法来做:
batch_size = tf.shape(outputs)[0]
# 得到每一个序列真正的index
index = tf.range(0, batch_size) * seq_max_len + (seqlen - 1)
outputs = tf.gather(tf.reshape(outputs, [-1, n_hidden]), index)
# 给最后的输出
return tf.matmul(outputs, weights['out']) + biases['out']
其中,参数 sequence_length=seqlen为什么要使用呢?原因在于序列是不等长的 ,每一个 batch 中,各个序列的长度都记录在 seqIen 中 。 在调用 tf.nn.dynamic_rnn 时 加入参数 sequence_length=seqlen, TensorFlow 会知道每个序列的具体长度, 在执行到对应长度后不再进行运行 , 可以节省运行时间 。
在 TensorFlow 中,不能直接使用 seqlen取出对应位置的 outputs,因此又多定义了一个 index 变量,借助它和 tf.gather 函数来实现取出对应位置输出值的功能。
3、定义损失并训练
# 这里的pred是logits而不是概率
pred = dynamicRNN(x, seqlen, weights, biases)
# 因为pred是logits,因此用tf.nn.softmax_cross_entropy_with_logits来定义损失
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
optimizer = tf.train.GradientDescentOptimizer(learning_rate=learning_rate).minimize(cost)
# 分类准确率
correct_pred = tf.equal(tf.argmax(pred,1), tf.argmax(y,1))
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
# 初始化
init = tf.global_variables_initializer()
# 训练
with tf.Session() as sess:
sess.run(init)
step = 1
while step * batch_size < training_iters:
batch_x, batch_y, batch_seqlen = trainset.next(batch_size)
# 每run一次就会更新一次参数
sess.run(optimizer, feed_dict={x: batch_x, y: batch_y,seqlen: batch_seqlen})
if step % display_step == 0:
# 在这个batch内计算准确度
acc = sess.run(accuracy, feed_dict={x: batch_x, y: batch_y,seqlen: batch_seqlen})
# 在这个batch内计算损失
loss = sess.run(cost, feed_dict={x: batch_x, y: batch_y,seqlen: batch_seqlen})
print("Iter " + str(step*batch_size) + ", Minibatch Loss= " + \
"{:.6f}".format(loss) + ", Training Accuracy= " + \
"{:.5f}".format(acc))
step += 1
print("Optimization Finished!")
# 最终,我们在测试集上计算一次准确度
test_data = testset.data
test_label = testset.labels
test_seqlen = testset.seqlen
print("Testing Accuracy:", \
sess.run(accuracy, feed_dict={x: test_data, y: test_label,seqlen: test_seqlen}))