几种常用的激活函数
1. 激活函数
如下图,在神经元中,输入的 inputs 通过加权,求和后,还被作用了一个函数,这个函数就是激活函数 Activation Function。
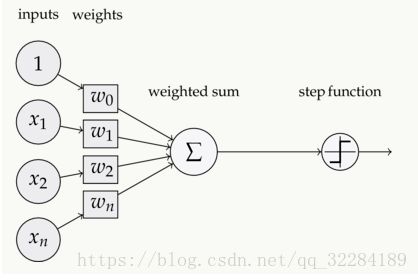
1.1 激活函数的作用:
如果不用激活函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。
如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
激活函数的主要作用是提供网络的非线性建模能力。如果没有激活函数,那么该网络仅能够表达线性映射,此时即便有再多的隐藏层,其整个网络跟单层神经网络也是等价的。因此也可以认为,只有加入了激活函数之后,深度神经网络才具备了分层的非线性映射学习能力。
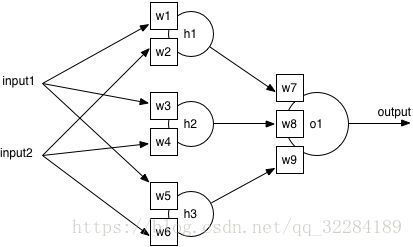
上图中我们对output进行计算(这里i1代表input1,i2代表input2):
![]()
我们将公式转化一下可以得到:
![]()
我们假设outpu=0
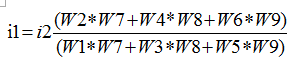
最后我们发现函数的又回到了y=X*W的模式,即线性模式。所以现在神经元的学习能力是非常有限的。解决不了非线性的问题,所以叠加简单的神经网络解决不了非线性的问题。
1.2 激活函数特性:
- 可微性: 当优化方法是基于梯度的时候,这个性质是必须的。
- 单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数。
- 输出值的范围: 当激活函数输出值是 有限 的时候,基于梯度的优化方法会更加 稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是 无限 的时候,模型的训练会更加高效,不过在这种情况小,一般需要更小的learning rate。
2. 各种激活函数
2.1 sigmod函数
函数公式和图表如下图
![]()
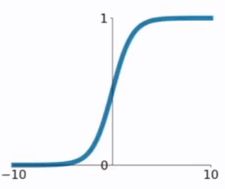
在sigmod函数中我们可以看到,其输出是在[0,1]这个开区间内,我们可以联想到概率,可以被表示做为概率,或用于输入的归一化,代表性的如Sigmoid交叉熵损失函数,但是严格意义上讲,不要当成概率。sigmod函数曾经是比较流行的,它可以想象成一个神经元的放电率,在中间斜率比较大的地方是神经元的敏感区,在两边斜率很平缓的地方是神经元的抑制区。
当然,流行也是曾经流行,这说明函数本身是有一定的缺陷的。
- 当输入稍微远离了坐标原点,函数的梯度就变得很小了,几乎为零。在神经网络反向传播的过程中,我们都是通过微分的链式法则来计算各个权重w的微分的。当反向传播经过了sigmod函数,这个链条上的微分就很小很小了,况且还可能经过很多个sigmod函数,最后会导致权重w对损失函数几乎没影响,这样不利于权重的优化,这个问题叫做梯度饱和,也可以叫梯度弥散(梯度消失)。
- 函数输出不是以0为中心的,这样会使权重更新效率降低。因为这会导致后层的神经元的输入是非0均值的信号,这会对梯度产生影响:假设后层神经元的输入都为正(e.g. x>0 elementwise in ),那么对w求局部梯度则都为正,这样在反向传播的过程中w要么都往正方向更新,要么都往负方向更新,导致有一种捆绑的效果,使得收敛缓慢。 当然了,如果你是按batch去训练,那么每个batch可能得到不同的符号(正或负),那么相加一下这个问题还是可以缓解。因此,非0均值这个问题虽然会产生一些不好的影响,不过跟上面提到的 kill gradients 问题相比还是要好很多的。(不过有一种常用的解决方案是,将最终函数值减去0.5)
- sigmod函数要进行指数运算,这个对于计算机来说训练效率是比较慢的。
具体来说,由于在后向传递过程中,sigmoid向下传导的梯度包含了一个 f′(x)f′(x) 因子(sigmoid关于输入的导数),因此一旦输入落入饱和区,f′(x)f′(x) 就会变得接近于0,导致了向底层传递的梯度也变得非常小。此时,网络参数很难得到有效训练。这种现象被称为梯度消失。一般来说, sigmoid 网络在 5 层之内就会产生梯度消失现象。
此外,sigmoid函数的输出均大于0,使得输出不是0均值,这称为偏移现象,这会导致后一层的神经元将得到上一层输出的非0均值的信号作为输入。
2.2 tanh函数
tanh函数公式和曲线如下
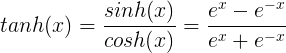
tanh的变形

tanh是双曲正切函数,tanh函数和sigmod函数的曲线是比较相近的,咱们来比较一下看看。首先相同的是,这两个函数在输入很大或是很小的时候,输出都几乎平滑,梯度很小,不利于权重更新;不同的是输出区间,tanh的输出区间是在(-1,1)之间,而且整个函数是以0为中心的,这个特点比sigmod的好。
一般二分类问题中,隐藏层用tanh函数,输出层用sigmod函数。不过这些也都不是一成不变的,具体使用什么激活函数,还是要根据具体的问题来具体分析,还是要靠调试的。
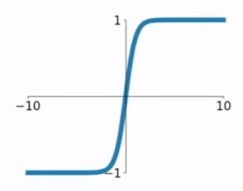
2.3 ReLU函数
ReLU函数公式和曲线如下
![]()
ReLU(Rectified Linear Unit)函数是目前比较火的一个激活函数,相比于sigmod函数和tanh函数,它有以下几个优点:
- Krizhevsky发现使用 ReLU 得到的SGD的收敛速度会比sigmoid/tanh 快很多。有人说这是因为它是linear,而且梯度不会饱和
- 计算速度要快很多。ReLU函数只有线性关系,不管是前向传播还是反向传播,都比sigmod和tanh要快很多。(sigmod和tanh要计算指数,计算速度会比较慢)
当然,缺点也是有的:
- ReLU在训练的时候很”脆弱”,一不小心有可能导致神经元”坏死”。举个例子:由于ReLU在x<0时梯度为0,这样就导致负的梯度在这个ReLU被置零,而且这个神经元有可能再也不会被任何数据激活。如果这个情况发生了,那么这个神经元之后的梯度就永远是0了,也就是ReLU神经元坏死了,不再对任何数据有所响应。实际操作中,如果你的learning rate 很大,那么很有可能你网络中的40%的神经元都坏死了。 当然,如果你设置了一个合适的较小的learning rate,这个问题发生的情况其实也不会太频繁。
- 我们发现ReLU函数的输出要么是0,要么是正数,这也就是说,ReLU函数也不是以0为中心的函数。
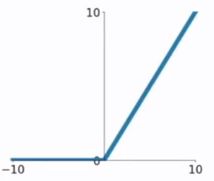
2.4 ELU函数
ELU函数公式和曲线如下图


ELU函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的,而且这部分输出还具有一定的抗干扰能力。这样可以消除ReLU死掉的问题,不过还是有梯度饱和和指数运算的问题。
2.5 PReLU函数
PReLU函数公式和曲线如下图
![]()
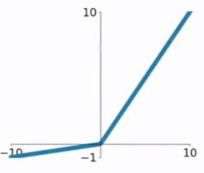
PReLU也是针对ReLU的一个改进型,在负数区域内,PReLU有一个很小的斜率,这样也可以避免ReLU死掉的问题。相比于ELU,PReLU在负数区域内是线性运算,斜率虽然小,但是不会趋于0,这算是一定的优势吧。
我们看PReLU的公式,里面的参数α一般是取0~1之间的数,而且一般还是比较小的,如零点零几。当α=0.01时,我们叫PReLU为Leaky ReLU,算是PReLU的一种特殊情况吧。
2.6 MAXOUT函数
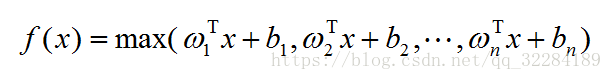
maxout网络能够近似任意连续函数,且当w2,b2,…,wn,bn为0时,退化为ReLU。Maxout能够缓解梯度消失,同时又规避了ReLU神经元死亡的缺点,但增加了参数和计算量。
2.7 softmax函数
softmax--用于多分类神经网络输出
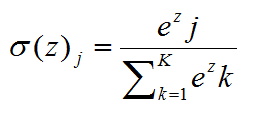

3. 几种激活函数的对比
sigmod和ReLU
隐藏层的激活函数有9中激活函数可以选择:Sigmoid,Linear,Tanh,ArchTan,Relu,Parameteric ReLU(PReLU),ELU,SoftPlus和BentLinear
这里我们在隐藏层分别用sigmod和ReLU,输出层为sigmod。
- 数据比较复杂时,mini_batch的值设置的相对大一些,这样每次能覆盖不同的类型,训练的效果会更好。
- 在训练次数相同时,ReLU激活函数的训练效果确实优于sigmoid函数。在大量次数(几十万次以上)训练后相差不大。
- sigmoid更容易出现过拟合。对于这个实验,隐层神经元为30个的时候,sigmoid会出现过拟合现象,几乎不能分类,在隐层神经元为10个的时候,能够进行部分分类,但是效果比不上ReLU的分类效果。
- ReLU在小batch(比如10)时效果不好
对于ReLU而言,ReLU的特点是,隐层比sigmoid需要的神经元多,学习速率相对要小一点,mini_batch的数量要大一些。
总结:
总体来看,这些激活函数都有自己的优点和缺点,没有一条说法表明哪些就是不行,哪些激活函数就是好的,所有的好坏都要自己去实验中得到。不同的数据不同的场景不同的模型所需要的是不同的激活函数,而我们所需要做的就是优雅的选出那个最合适的为我们所用。
参考链接:
大白话讲解BP算法:【https://blog.csdn.net/zhaomengszu/article/details/77834845】
RNN学习中长期依赖的三种机制:【https://zhuanlan.zhihu.com/p/34490114】
RNN中为什么用tanh作为激活函数而不是ReLU(其实也是可以用ReLU,比如IRNN):【https://www.zhihu.com/question/61265076】
常用的激活函数:【https://www.jianshu.com/p/22d9720dbf1a】