TensorFlow全新的数据读取方式:Dataset API——tf.data.Dataset
转载博客地址:
https://baijia.baidu.com/s?id=1583657817436843385&wfr=pc&fr=new_lst
一、Tensorflow读入数据的三种方式
1)Feeding:Python代码在运行每一步时提供数据
2)从文件中读取:输入管道从TensorFlow图形的开头读取文件中的数据。
3)预加载数据:TensorFlow图中的常量或变量保存所有数据(对于小数据集)。
二、Dataset
1 Dataset API属于第二种方式,使读取数据、复杂的数据格式变换变得更容易
2 tf.data.Dataset表示一系列元素,其中每个元素包含一个或多个Tensor对象。 例如,在图像流水线中,一个元素可能是单个训练样例,其中一对张量表示图像数据和一个标签。 有两种不同的方法来创建数据集
Dataset支持一类特殊的操作:Transformation。一个Dataset通过Transformation变成一个新的Dataset 。
3.dataset的创建可以来自于tensor,也可以来自于文件
#创建来自于tensors的dataset
dataset1=tf.data.Dataset.from_tensor_slices
#创建来自于文件的dataset
dataset1= tf.contrib.data.TextLineDataset(src_file)4 dataset作为API使用,主要做数据转换
1)tf.data.Dataset.zip
2)dataset1.map
map接收 一个函数 ,Dataset中的每个元素都会被当作这个函数的输入,并将函数返回值作为新的Dataset,如我们可以对dataset中每个元素的值加1:
dataset = tf.data.Dataset.from_tensor_slices(np.array([1.0, 2.0, 3.0]))
dataset = dataset.map(lambda x: x+1) #2.0, 3.0, 4.0dataset1.padded_batch
5 iterator创建
dataset1.make_initializable_iterator()
6 使用流程
构造Dataset对象
创建 iterator
7、示例代码
import tensorflow as tf
#An element contains one or more tf.Tensor objects, called components
dataset1 = tf.data.Dataset.from_tensor_slices(tf.random_uniform([4, 10]))
print("dataset1.output_types",dataset1.output_types)
#('dataset1.output_types', tf.float32)
print("dataset1.output_shapes",dataset1.output_shapes)
#('dataset1.output_shapes', TensorShape([Dimension(10)]))
dataset2 = tf.data.Dataset.from_tensor_slices(
{"a": tf.random_uniform([4]),
"b": tf.random_uniform([4, 100], maxval=100, dtype=tf.int32)})
print("dataset2.output_types",dataset2.output_types)
#('dataset2.output_types', {'a': tf.float32, 'b': tf.int32})
print("dataset2.output_shapes",dataset2.output_shapes)
#('dataset2.output_shapes', {'a': TensorShape([]), 'b': TensorShape([Dimension(100)])})
dataset3 = tf.data.Dataset.zip((dataset1, dataset2))
print("dataset3.output_types",dataset3.output_types)
#('dataset3.output_types', (tf.float32, {'a': tf.float32, 'b': tf.int32}))
print("dataset3.output_types",dataset3.output_shapes)
#('dataset3.output_types', (TensorShape([Dimension(10)]), {'a': TensorShape([]), 'b': TensorShape([Dimension(100)])}))接下来运行如下代码:
iterator = dataset1.make_initializable_iterator()
next_element = iterator.get_next()
init_op = iterator.initializer
print("batched data 1:",sess.run(next_element))
print("batch data 2:",sess.run(next_element))
print("batched data 3:",sess.run(next_element))
print("batch data 4:",sess.run(next_element))
#print("batch data 5:",sess.run(next_element)) 运行时报错结果如下:
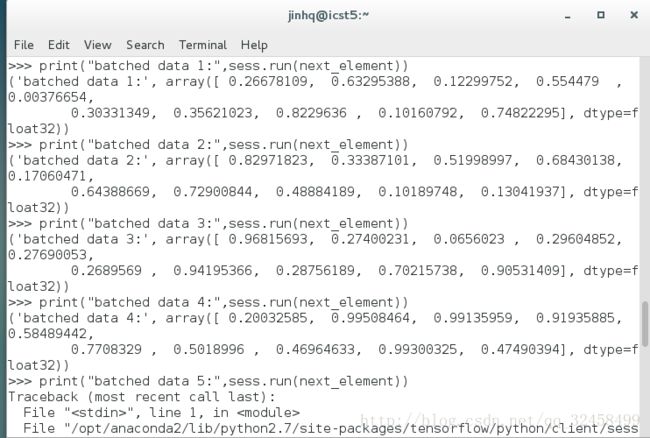
接下来对dataset1做变换
#which apply a function to each element, the element
structure determines the arguments of the function
dataset1 = dataset1.map(lambda x:x+1)
#dataset1 = dataset1.padded_batch(2,padded_shapes=[11])
dataset1 = dataset1.padded_batch(2,padded_shapes=[None])