python爬虫登陆 带Cookie token
用python写爬虫整的很方便,弄了个模拟登陆,登陆后带上token和cooke请求页面
就拿gitlab练下手了,这个还是有一丢丢麻烦的
一、登陆界面
获取隐藏域中的token,构建表单的时候需要
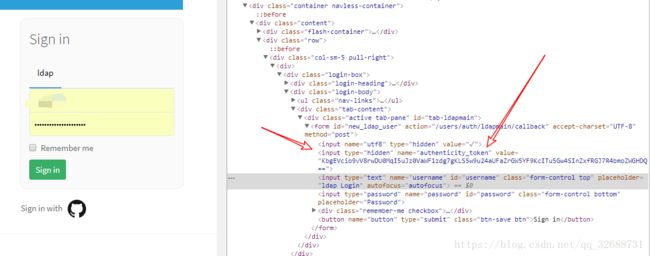
获取到这个_gitlab_session,登陆校验时需要带着这个信息
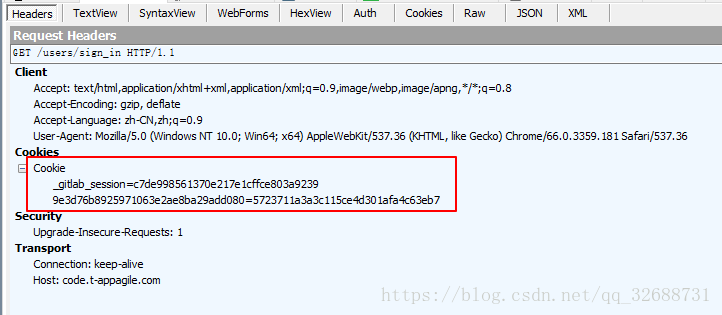
准备好token和cookie,当然还需要一个能登陆用户名和密码
二、登陆验证
登陆验证就是构建表单,不知为何还要传一个utf-8参数

按说应该可以登陆进去的,但是....登陆进去后页面会重定向到一个界面。接着呢,只好看fiddle里抓包的信息
之前一直以为没有登陆成功,其实已经登陆成功,但是请求需要登陆页面,还是会跳转到登陆界面。。
原来登陆成功后会获取一个新的session,然后需要调整 Headers里面的信息
再用这个headers去请求需要登陆的页面,发现都可以了
代码如下,写得很随意:
"""
http://code.t-appagile.com/users/sign_in
http://code.t-appagile.com/users/sign_in
"""
import requests
import json
import string
from bs4 import BeautifulSoup
login = "http://code.t-appagile.com/users/sign_in"
call = "http://code.t-appagile.com/users/auth/ldapmain/callback"
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7',
'Cache-Control': 'no-cache',
# 'Content-Length':'183',
'Content-Type': 'application/x-www-form-urlencoded',
'Cookie': '',
'Host': 'code.t-appagile.com',
'Origin': 'http://code.t-appagile.com',
'Proxy-Connection': 'keep-alive',
'Referer': 'http://code.t-appagile.com/users/sign_in',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36',
}
def HttpPost(apiUrl, data):
try:
global headers
r = requests.post(apiUrl,headers=headers, data=data)
cook = r.request.headers["Cookie"].split('=')
lowCook = headers["Cookie"].split('=')
newCook=lowCook[0]+'='+lowCook[1]+'='+cook[2]
headers["Cookie"] = newCook
print("登陆成功:",newCook)
return r
except:
return
def HttpGet(apiUrl):
try:
global headers
r = requests.get(apiUrl)
cook = ""
for c in r.cookies:
cook += c.name + "="+c.value + ";"
headers["Cookie"] = cook
print("登陆前的:",cook)
return r.text
except:
return
def HttpGetLcmm(apiUrl):
try:
r = requests.get(apiUrl,headers=headers)
return r.text
except:
return
res = HttpGet(login)
html = BeautifulSoup(res,"html.parser")
token = html.find_all(type="hidden")[1]["value"]
postData ={}
postData["utf8"] ="✓"
postData["authenticity_token"] =token
postData["username"] ="你的账号"
postData["password"] ="你的密码"
res = HttpPost(call,postData)
# print(res.status_code)
# print(res.text)
# print(html)
res = HttpGetLcmm("http://code.t-appagile.com/SI.Web/lcmm-web")
print('ok!')
发现,写模拟登陆需要很耐心,对比真实的http请求headers里面的信息,再去构建模拟请求的
有时间再弄个有验证码的,应该也简单,毕竟都有验证码识别的Api了