scrapy实战多级页面抓取
今天实战为大家介绍多级页面的抓取,以车质网投诉为例
1.准备工作
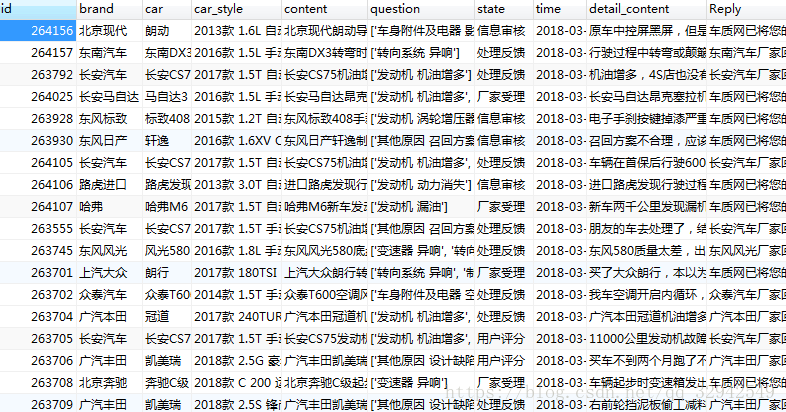
首先明确要抓取的字段,包括投诉编码,投诉品牌,车型等和投诉简述里面的日期,详细投诉内容和回复,分为两个页面。

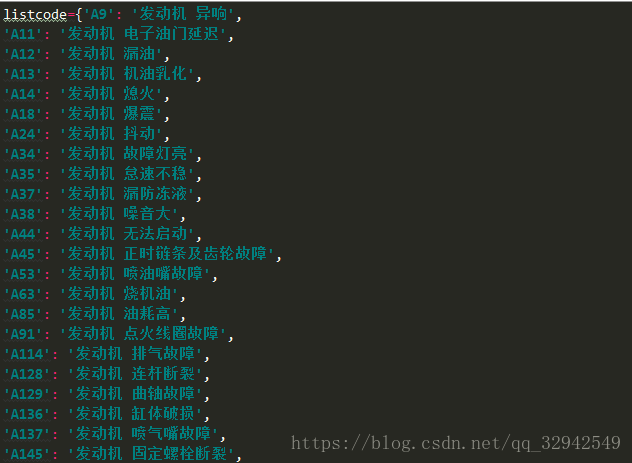
通过查看典型问题是通过JS动态加载的,这里我们先处理一下,转成字典格式,是通过编码识别来判断的

调整后的数据是这样的,保存跟item同级目录下命名为chezhi.py
2.项目开始
创建一个项目
scrapy startproject chezhi明确要抓取的字段
import scrapy
class ChezhiItem(scrapy.Item):
id = scrapy.Field()
brand = scrapy.Field()
car = scrapy.Field()
car_style = scrapy.Field()
content = scrapy.Field()
question = scrapy.Field()
state = scrapy.Field()
time = scrapy.Field()
detail_content = scrapy.Field()
Reply = scrapy.Field()编写spider代码
# -*- coding: utf-8 -*-
import scrapy
from chezhi.items import ChezhiItem
from chezhi.chezhi import listcode
class TousuSpider(scrapy.Spider):
name = 'tousu'
allowed_domains = ['www.12365auto.com']
def start_requests(self):
url='http://www.12365auto.com/zlts/0-1878-0-0-0-0_0-0-{0}.shtml'
for i in range(1,51):
yield scrapy.Request(url.format(i),callback=self.pare)
def pare(self,response):
trs=response.xpath('//table//tr')
# trs=article_list.xpath("tr")
# items=[]
# print(listcode)
# list1=[]
for i in trs[1:]:
items=ChezhiItem()
items['id']=i.xpath("td[1]/text()")[0].extract()
items['brand']=i.xpath("td[2]/text()")[0].extract()
items['car']=i.xpath("td[3]/text()")[0].extract()
items['car_style']=i.xpath("td[4]/text()")[0].extract()
items['content']=i.xpath("td[5]/a/text()")[0].extract()
url=i.xpath("td[5]/a/@href")[0].extract()
question_list=i.xpath("td[6]//text()")[0].extract()
codes=question_list.split(',')
# print(article['id'],codes,[listcode.get(j) for j in codes][:-1])
items['question']=str([listcode.get(j) for j in codes][:-1])
items['state']=i.xpath("td[8]/em/text()")[0].extract()
# items.append(article)
# print(url)
# print (items,'------------')
# yield items
yield scrapy.Request(url=url,meta={'items':items},callback=self.pare_detail,dont_filter=True)
def pare_detail(self,response):
items=response.meta['items']
items['time']=response.xpath('//div[@class="jbqk"]/ul/li[5]/text()')[0].extract()
items['detail_content']=response.xpath('//div[@class="tsnr"]/p/text()')[0].extract()
items['Reply']=response.xpath('//div[@class="tshf"]/p/text()')[0].extract()
# print(items)
yield items
pipelines
import pymysql
import pymysql.cursors
class ChezhiPipeline(object):
def process_item(self, item, spider):
DBKWARGS=spider.settings.get('DBKWARGS')
con=pymysql.connect(**DBKWARGS)#链接数据库
cur=con.cursor()游标
sql=('insert into chezhi values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)')
lis=(item['id'],item['brand'],item['car'],item['car_style'],item['content'],
item['question'],item['state'],item['time'],item['detail_content'],item['Reply'])
try:
cur.execute(sql,lis)#插入数据
except Exception as e:
print("insert err:",e)
con.rollback()#回滚
else:
con.commit()
cur.close()#关闭游标
con.close()#关闭链接
return itemsettings文件编写
BOT_NAME = 'chezhi'
SPIDER_MODULES = ['chezhi.spiders']
NEWSPIDER_MODULE = 'chezhi.spiders'
DBKWARGS={'db':'test',"user":"root","passwd":"12345","host":"localhost","use_unicode":True,"charset":"utf8"}
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36",
]
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, sdch',
'Accept-Language': 'zh-CN,zh;q=0.8,en;q=0.6,zh-TW;q=0.4',
'Connection': 'keep-alive',
'Cookie': 'uuid=384279260814621; UM_distinctid=1624818bb6a404-0fe2919d52c83c-546d3974-100200-1624818bb9730a; uuid=384279260814621; ASP.NET_SessionId=eyhvs1zwzzbeonr05b41o455; CNZZDATA2115974=cnzz_eid%3D1359293862-1521625094-null%26ntime%3D1521684499; Hm_lvt_d08ac25fd4c45e85e8d9f1c32e97a0eb=1521628003,1521684855; Hm_lpvt_d08ac25fd4c45e85e8d9f1c32e97a0eb=1521689053',
'Cache-Control': 'max-age=0',
'DNT': '1',
'Host': 'www.12365auto.com',
'Referer': 'http://www.12365auto.com/zlts/0-1878-0-0-0-0_0-0-1.shtml',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'chezhi (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False到这里就可以运行啦,有兴趣的朋友可以在优化一下。
查看下抓取到的数据