PaddleNLP 自然语言处理 知识图谱 uie-x-base,uie-m-large,uie-m-base模型使用时,报错Out of memory error on GPU 0 gpu内存不够

- Hi, I’m @货又星
- I’m interested in …
- I’m currently learning …
- ️ I’m looking to collaborate on …
- How to reach me …
- README 目录(持续更新中) 各种错误处理、爬虫实战及模板、百度智能云人脸识别、计算机视觉深度学习CNN图像识别与分类、PaddlePaddle自然语言处理知识图谱、GitHub、运维…
- WeChat:1297767084
- GitHub:https://github.com/cxlhyx
文章目录
- PaddleNLP
- PaddleNLP功能
-
- 1、大模型文本生成
- 2、 开箱即用的NLP工具集:一键UIE预测
- 3、 丰富完备的中文模型库
- 4、️ 产业级端到端系统范例
- 5、 高性能分布式训练与推理
- 6、更直接的知识图谱知识抽取链接
- PaddleNLP的环境搭建
- 我的问题描述
- 原因分析
- 解决方案
PaddleNLP
自然语言处理nlp 大语言模型 知识图谱构建 问答系统 信息检索 知识抽取
PaddleNLP是一款简单易用且功能强大的自然语言处理和大语言模型(LLM)开发库。聚合业界优质预训练模型并提供开箱即用的开发体验,覆盖NLP多场景的模型库搭配产业实践范例可满足开发者灵活定制的需求。PaddleNLP的优势在于它提供一键预测功能,无需训练,直接输入数据即可开放域抽取结果。
paddlenlp GitHub链接:PaddleNLP
PaddleNLP功能
1、大模型文本生成
PaddleNLP提供了方便易用的Auto API,能够快速的加载模型和Tokenizer。
2、 开箱即用的NLP工具集:一键UIE预测
Taskflow提供丰富的开箱即用的产业级NLP预置模型,覆盖自然语言理解与生成两大场景,提供产业级的效果与⚡️极致的推理性能。
PaddleNLP一键预测功能:Taskflow API
PaddleNLP提供一键预测功能,无需训练,直接输入数据即可开放域抽取结果。
值得注意的的是,利用这个功能可以实现知识图谱构建所需的实体识别,关系抽取,时间抽取。

3、 丰富完备的中文模型库
业界最全的中文预训练模型
精选 45+ 个网络结构和 500+ 个预训练模型参数,涵盖业界最全的中文预训练模型:既包括文心NLP大模型的ERNIE、PLATO等,也覆盖BERT、GPT、RoBERTa、T5等主流结构。通过AutoModel API一键⚡高速下载⚡。
全场景覆盖的应用示例
覆盖从学术到产业的NLP应用示例,涵盖NLP基础技术、NLP系统应用以及拓展应用。全面基于飞桨核心框架2.0全新API体系开发,为开发者提供飞桨文本领域的最佳实践。
精选预训练模型示例可参考Model Zoo,更多场景示例文档可参考examples目录。更有免费算力支持的AI Studio平台的Notbook交互式教程提供实践。
4、️ 产业级端到端系统范例
PaddleNLP针对信息抽取、语义检索、智能问答、情感分析等高频NLP场景,提供了端到端系统范例,打通数据标注-模型训练-模型调优-预测部署全流程,持续降低NLP技术产业落地门槛。更多详细的系统级产业范例使用说明请参考PaddleNLP 提供了多个版本的产业范例:Applications。
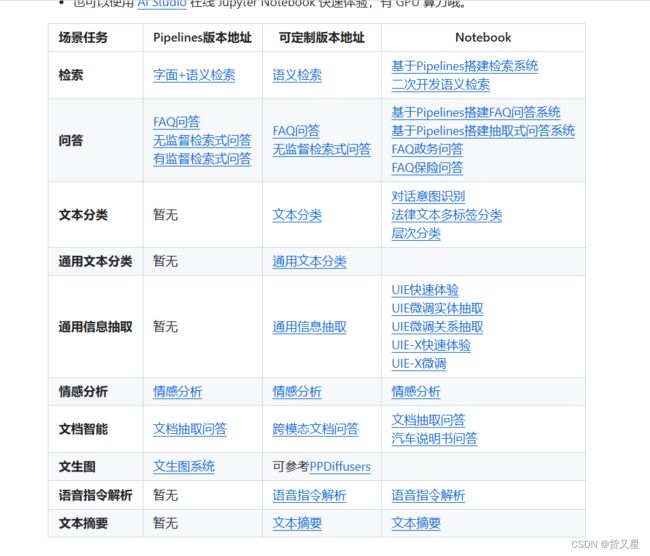
语义检索系统
针对无监督数据、有监督数据等多种数据情况,结合SimCSE、In-batch Negatives、ERNIE-Gram单塔模型等,推出前沿的语义检索方案,包含召回、排序环节,打通训练、调优、高效向量检索引擎建库和查询全流程。
❓ 智能问答系统 和 文档智能问答
基于RocketQA技术的检索式问答系统,支持FAQ问答、说明书问答等多种业务场景。
评论观点抽取与情感分析
基于情感知识增强预训练模型SKEP,针对产品评论进行评价维度和观点抽取,以及细粒度的情感分析。
️ 智能语音指令解析
集成了PaddleSpeech和百度开放平台的语音识别和UIE通用信息抽取等技术,打造智能一体化的语音指令解析系统范例,该方案可应用于智能语音填单、智能语音交互、智能语音检索等场景,提高人机交互效率。
5、 高性能分布式训练与推理
⚡ FastTokenizer:高性能文本处理库
为了实现更极致的模型部署性能,安装FastTokenizers后只需在AutoTokenizer API上打开 use_fast=True选项,即可调用C++实现的高性能分词算子,轻松获得超Python百余倍的文本处理加速,更多使用说明可参考FastTokenizer文档。
⚡️ FastGeneration:高性能生成加速库
简单地在generate()API上打开use_fast=True选项,轻松在Transformer、GPT、BART、PLATO、UniLM等生成式预训练模型上获得5倍以上GPU加速,更多使用说明可参考FastGeneration文档。
Fleet:飞桨4D混合并行分布式训练技术
更多关于千亿级AI模型的分布式训练使用说明可参考GPT-3。
6、更直接的知识图谱知识抽取链接
通用信息抽取应用
文本通用信息抽取 UIE(Universal Information Extraction)
文档通用信息抽取UIE Taskflow使用指南
ERNIE-Health 中文医疗预训练模型
使用医疗领域预训练模型Fine-tune完成中文医疗语言理解任务
PaddleNLP的环境搭建
PaddleNLP的环境要求比较复杂,需要我们有以下软件或库:
1、cuda和cudnn,这是PaddleNLP环境搭建的重难点。
2、paddlepaddle或者叫paddle,这两个在我理解来是一个东西,安装方式是一样的。
3、paddlenlp,这个的安装应该是最简单的了。
需要注意的是:paddlenlp的搭建过程挺复杂的,对各个软件或库的安装版本要求比较严格。
博主使用的是:anaconda3-2022.10-Windows-x86_64 + pycharm-community-2023.2.3 + CUDA11.8 + cuDNN8.9. + paddle2.5.2 + paddlenlp2.6.1.post
这里可以参考suibianshen2012博主的paddlenlp安装教程,照着步骤一步一步来对应好版本应该是可以的,建议不要选太新的版本,bug比较多。
我的问题描述
uie-x-base,uie-m-large,uie-m-base模型使用时报错
在使用Taskflow的uie-x-base,uie-m-large,uie-m-base模型时会出现以下错误,而其他模型正常。
Out of memory error on GPU 0. Cannot allocate 70.312500MB memory on GPU 0, 1.999999GB memory has been allocated and available memory is only 0.000000B.
Please check whether there is any other process using GPU 0.
1. If yes, please stop them, or start PaddlePaddle on another GPU.
2. If no, please decrease the batch size of your model.
原因分析
报错显示GPU内存不足
gpt告诉我可以通过以下方法解决
- 检查是否有其他进程正在使用GPU 0。如果有,请停止这些进程,并尝试重新启动您的模型。
- 如果没有其他进程使用GPU 0,请尝试降低模型的batch size。这可能有助于减少所需的计算量,从而释放更多的内存。
- 检查模型是否正确配置。确保您的模型正确地设置了训练和推理所需的参数。有时,错误的参数设置可能会导致内存不足问题。
- 检查您的操作系统是否提供了足够的内存管理功能。例如,某些操作系统可能允许您在一定程度上控制程序运行时使用的内存。您可以在操作系统的设置中检查这些选项。
- 如果以上方法都无法解决问题,您可能需要考虑升级您的硬件配置,以便更好地处理大型模型。
经过尝试都无法解决,而且我们是利用模型直接进行预测而不是训练按理说不应该gpu内存不足。
解决方案
修改一次device_id
按下Crtl,点击Taskflow,可以看到它的构造函数。

可以看到如果你的电脑只有cpu或者device_id==-1,那么将使用cpu进行训练或预测,而如果你的电脑有gpu并且你没有指定device_id,那么是使用gpu:0进行训练或预测的。
我们就是在使用gpu:0时报的错,所以你可以通过设置Taskflow的参数device_id来换成cpu或者其它的gpu来运行程序。
设置完参数后,就可以正确运行了。接着我又把这个参数去掉,发现它又不报错了。神奇。