大数据技术之Hadoop(入门)
大数据技术之Hadoop(入门)
从Hadoop框架讨论大数据生态
Google是Hadoop的思想之源(Google在大数据方面的三篇论文)
GFS ====> HDFS
Map-Reduce ====> MR
BigTable ====> HBase
Hadoop的优势
高可靠性:因为Hadoop假设计算元素和存储会出现故障,它维护多个工作数据副本,在出现故障时可以对失败的节点重新分布处理。
高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
高容错性:自动保存多份副本数据,并且能够自动将失败的任务重新分配。
Hadoop组成
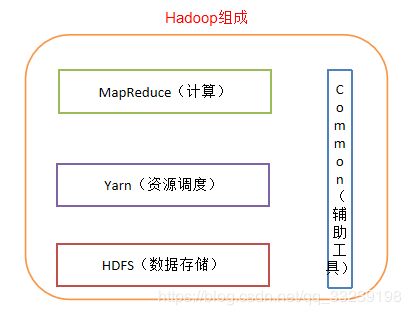
Hadoop HDFS:Hadoop Distributed File System一个高可靠、高吞吐量的分布式文件系统。
Hadoop MapReduce:一个分布式的离线并行计算框架。
Hadoop YARN:作业调度与集群资源管理的框架。
Hadoop Common:支持其他模块的工具模块(Configuration、RPC、序列化机制、日志操作)。
HDFS架构概述
YARN架构概述
ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度
NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令
ApplicationMaster:数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错
Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息
MapReduce架构概述
MapReduce将计算过程分为两个阶段:Map和Reduce
Map阶段并行处理输入数据
Reduce阶段对Map结果进行汇总
Hadoop运行环境搭建
环境配置
关闭防火墙
关闭防火墙:systemctl stop firewalld.service
禁用防火墙:systemctl disable firewalld.service
查看防火墙:systemctl status firewalld.service
关闭Selinux:vi /etc/selinux /config
将SELINUX=enforcing改为SELINUX=disabled
修改IP
善用Tab键
vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.X.51
GATEWAY=192.168.X.2
DNS1=8.8.8.8
DNS2=8.8.4.4
NETMASK=255.255.255.0
X代表本地IP的第三个,即Windows上的IP
vi /etc/resolv.conf
nameserver 8.8.8.8
nameserver 8.8.4.4
重启网卡:servie network restart
修改主机名
hostnamectl set-hostname 主机名
IP和主机名关系映射
vi /etc/hosts
192.168.x.10 CentOS
192.168.x.11 CentOS1
192.168.x.12 CentOS2
192.168.x.13 CentOS3
在windows的C:\Windows\System32\drivers\etc路径下找到hosts并添加
192.168.x.10 CentOS
192.168.x.11 CentOS1
192.168.x.12 CentOS2
192.168.x.13 CentOS3
注意:不知何故,Windows里的hosts修改一段时间后会被注释掉,可能是360杀毒软件的原因,使用Notepad++将注释#号去掉即可。
连接Secure CRT & Xshell
输入IP、用户名和密码
安装jdk
卸载现有jdk
(1)查询是否安装java软件:
rpm -qa|grep java
(2)如果安装的版本低于1.7,卸载该jdk:
rpm -e 软件包名字
在/opt目录下创建两个子文件
mkdir /opt/module /opt/software
解压jdk到/opt/module目录下
tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
配置jdk环境变量
vi /etc/profile
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
测试jdk安装成功
java -version
java version “1.8.0_144”
Hadoop运行模式
伪/完全分布式部署Hadoop
SSH无密码登录
生成公钥和私钥:ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免密登录的目标机器上
ssh-copy-id 主机名1
ssh-copy-id 主机名2
ssh-copy-id 主机名3
注:在另外两台机器上分别执行,共执行9遍
.ssh文件夹下的文件功能解释
(1)~/.ssh/known_hosts :记录ssh访问过计算机的公钥(public key)
(2)id_rsa :生成的私钥
(3)id_rsa.pub :生成的公钥
(4)authorized_keys :存放授权过得无秘登录服务器公钥
配置集群
(一)集群部署规划:
| CentOS | CentOS1 | CentOS2 | |
|---|---|---|---|
| HDFS | NameNode SecondaryNameNode DataNode | DataNode | DataNode |
| YARN | ResourceManager NodeManager | NodeManager | NodeManager |
(二)配置文件:
在core-site.xml中:
fs.defaultFS
hdfs://主机名1:9000
hadoop.tmp.dir
/opt/module/hadoop-2.X.X/data/tmp
在hdfs-site.xml中:
dfs.replication
3
dfs.namenode.secondary.http-address
主机名1:50090
dfs.permissions
false
在yarn-site.xml中:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
主机名1
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
在mapred-site.xml中:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
主机名1:10020
mapreduce.jobhistory.webapp.address
主机名1:19888
另外,hadoop-env.sh、yarn-env.sh、mapred-env.sh(分别在这些的文件中添加下面的路径)
export JAVA_HOME=/opt/module/jdk1.8.0_144(注:是自己安装的路径)
slaves设置自己的主机名:CentOS、CentOS1、CentOS2
格式化Namenode:
hdfs namenode -format
启动集群得命令:
Namenode的主节点:sbin/start-dfs.sh
Yarn的主节点:sbin/start-yarn.sh
注意:Namenode和ResourceManger如果不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn。
scp文件传输
实现两台远程机器之间的文件传输(CentOS主机文件拷贝到CentOS1主机上)
scp -r [文件] 用户@主机名:绝对路径
注:伪分布式是一台、完全分布是三台
完全分布式
步骤:
1)克隆2台客户机(关闭防火墙、静态ip、主机名称)
2)安装jdk
3)配置环境变量
4)安装hadoop
5)配置环境变量
6)安装ssh
7)配置集群
8)启动测试集群
注:此配置直接使用虚拟机克隆伪分布式两台即可
自带官方wordcount案例
随意上传一个文本文件
上传命令:hadoop fs -put 文件名 /
执行命令:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.X.X.jar wordcount /入 /出
命令解析:
hadoop jar 路径的jar包 全类名 输入路径 输出路径
查看结果:
hadoop fs -cat 路径
Hadoop启动和停止命令
以下命令都在$HADOOP_HOME/sbin下,如果直接使用,记得配置环境变量
| 功能 | 命令 |
|---|---|
| 启动/停止历史服务器 | mr-jobhistory-daemon.sh start |
| 启动/停止总资源管理器 | yarn-daemon.sh start |
| 启动/停止节点管理器 | yarn-daemon.sh start |
| 启动/停止 NN 和 DN | start |
| 启动/停止 RN 和 NM | start |
| 启动/停止 NN、DN、RN、NM | start |
| 启动/停止 NN | hadoop-daemon.sh start |
| 启动/停止 DN | hadoop-daemon.sh start |