过拟合与欠拟合
导语:我们使用一系列逐渐复杂的多项式来拟合一个非常简单的数据集。
先导入相应的一系列库:
%matplotlib inline
import pymc3 as pm
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
import seaborn as sns
palette = 'muted'
sns.set_palette(palette); sns.set_color_codes(palette)
sns.set()
生成一个简单的数据集,并做一些拟合。
x = np.array([4.,5.,6.,9.,12, 14.])
y = np.array([4.2, 6., 6., 9., 10, 10.])
order = [0, 1, 2, 5]
plt.plot(x, y, 'o')
for i in order:
x_n = np.linspace(x.min(), x.max(), 100)
coeffs = np.polyfit(x, y, deg=i)
ffit = np.polyval(coeffs, x_n)
p = np.poly1d(coeffs)
yhat = p(x)
ybar = np.mean(y)
ssreg = np.sum((yhat-ybar)**2)
sstot = np.sum((y - ybar)**2)
r2 = ssreg / sstot
plt.plot(x_n, ffit, label='order {}, $R^2$= {:.2f}'.format(i, r2))
plt.legend(loc=2, fontsize=10)
plt.xlabel('$x$', fontsize=14)
plt.ylabel('$y$', fontsize=14, rotation=0)
plt.savefig('B04958_06_01.png', dpi=300, figsize=[5.5, 5.5])
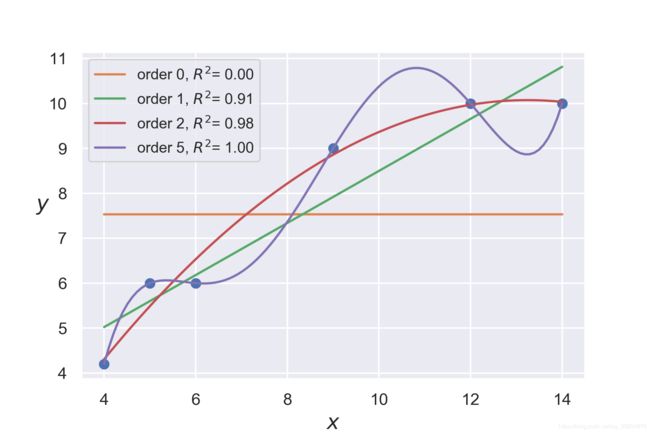 对应上面的结果思考:为什么5阶多项式能够完美地拟合所有数据呢? 因为模型中的参数个数与样本个数相同(都是6),因此模型只是用另一种方式对数据进行了编码,而模型并没有从数据中学到任何内容,只是记住了全部的数据。
对应上面的结果思考:为什么5阶多项式能够完美地拟合所有数据呢? 因为模型中的参数个数与样本个数相同(都是6),因此模型只是用另一种方式对数据进行了编码,而模型并没有从数据中学到任何内容,只是记住了全部的数据。
现在引入测试数据看看各阶曲线的拟合效果:
x = np.array([4.,5.,6.,9.,12, 14.])
y = np.array([4.2, 6., 6., 9., 10, 10.])
order = [0, 1, 2, 5]
plt.plot(x, y, 'o')
for i in order:
x_n = np.linspace(x.min(), x.max(), 100)
coeffs = np.polyfit(x, y, deg=i)
ffit = np.polyval(coeffs, x_n)
p = np.poly1d(coeffs)
yhat = p(x)
ybar = np.mean(y)
ssreg = np.sum((yhat-ybar)**2)
sstot = np.sum((y - ybar)**2)
r2 = ssreg / sstot
plt.plot(x_n, ffit, label='order {}, $R^2$= {:.2f}'.format(i, r2))
plt.legend(loc=2, fontsize=10)
plt.xlabel('$x$', fontsize=14)
plt.ylabel('$y$', fontsize=14, rotation=0)
plt.savefig('B04958_06_01.png', dpi=300, figsize=[5.5, 5.5])
# 引入测试数据
plt.plot([10, 7], [9, 7], 's')
plt.savefig('B04958_06_02.png', dpi=300, figsize=[5.5, 5.5])
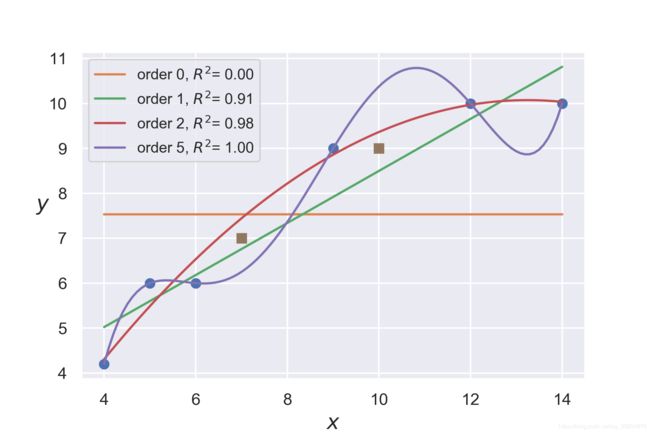 我们发现有些曲线对预测数据拟合得并不好,你应该知道什么是过拟合与欠拟合了!
我们发现有些曲线对预测数据拟合得并不好,你应该知道什么是过拟合与欠拟合了!
1. 过拟合
我觉得百度百科对过拟合定义还是很靠谱的
百度百科:https://baike.baidu.com/item/%E8%BF%87%E6%8B%9F%E5%90%88/3359778?fr=aladdin
1.1 概念
为了得到一致假设而使假设变得过度严格称为过拟合。
1.2 定义
给定一个假设空间 H,一个假设 h 属于 H,如果存在其他的假设 h’ 属于 H,使得在训练样例上 h 的错误率比 h’ 小,但在整个实例分布上 h’ 比 h 的错误率小,那么就说假设h过度拟合训练数据。
1.3 判断方法
一个假设在训练数据上能够获得比其他假设更好的拟合, 但是在训练数据外的数据集上却不能很好地拟合数据,此时认为这个假设出现了过拟合的现象。出现这种现象的主要原因是训练数据中存在噪音或者训练数据太少。
假设数据中存在有意义的模式,一旦模型开始学习模式之外的噪声就会出现过拟合的问题。
1.4 常见原因
(1)建模样本选取有误,如样本数量太少,选样方法错误,样本标签错误等,导致选取的样本数据不足以代表预定的分类规则;
(2)样本噪音干扰过大,使得机器将部分噪音认为是特征从而扰乱了预设的分类规则;
(3)假设的模型无法合理存在,或者说是假设成立的条件实际并不成立;
(4)参数太多,模型复杂度过高;为什么参数越多就能更好地拟合训练数据呢?因为参数越多,适应数据的方式就越多。
(5)对于决策树模型,如果我们对于其生长没有合理的限制,其自由生长有可能使节点只包含单纯的事件数据(event)或非事件数据(no event),使其虽然可以完美匹配(拟合)训练数据,但是无法适应其他数据集;
(6)对于神经网络模型:a)对样本数据可能存在分类决策面不唯一,随着学习的进行,BP算法使权值可能收敛过于复杂的决策面;b)权值学习迭代次数足够多(Overtraining),拟合了训练数据中的噪声和训练样例中没有代表性的特征。
1.5 解决方案
(1)在神经网络模型中,可使用权值衰减的方法,即每次迭代过程中以某个小因子降低每个权值;
(2)选取合适的停止训练标准,使对机器的训练在合适的程度;
(3)保留验证数据集,对训练成果进行验证;
(4)获取额外数据进行交叉验证;
(5)正则化,即在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。
2. 欠拟合
机器学习中一个重要的话题便是模型的泛化能力,泛化能力强的模型才是好模型,对于训练好的模型,若在训练集表现差,在测试集表现同样会很差,这可能是欠拟合导致。欠拟合是指模型拟合程度不高,数据距离拟合曲线较远,或指模型没有很好地捕捉到数据特征,不能够很好地拟合数据。
请回顾一下导语中的 0阶模型 ,从数学角度上解释为什么该模型不能很好地拟合数据?
在 0阶模型 中,两个变量之间的线性关系变成了只是描述因变量的一个高斯模型。换句话说,模型认为数据能够通过因变量的均值以及一些高斯噪声来解释,显然这种模型是欠拟合的,不能从数据中获取到有意义的模式。