Python爬虫实战之爬取B站番剧信息(详细过程)
目标:爬取b站番剧最近更新
输出格式:名字+播放量+简介
那么开始撸吧~用到的类库:
requests:网络请求
pyquery:解析xml文档,像使用jquery一样简单哦~
1.分析页面布局,找到需要爬取的内容
目标url:https://bangumi.bilibili.com/22/
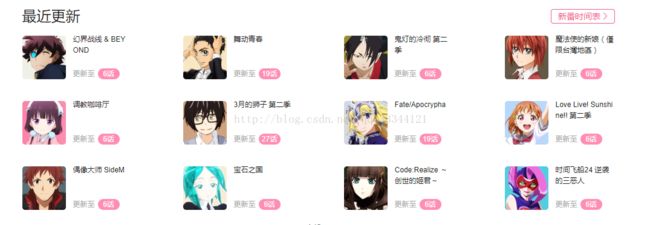
设计video类:
import requests
from pyquery import PyQuery as pq
class Video(object):
def __init__(self,name,see,intro):
self.name=name
self.see=see
self.intro=intro
def __str__(self):
return "{}--{}--{}".format(self.name,self.see,self.intro)分析完页面,设取爬去类:
class bilibili(object):
host="https://bangumi.bilibili.com"
def __init__(self):
self.dom=pq(requests.get('https://bangumi.bilibili.com/22/').text)
def get_recent(self):
'''最近更新'''
items=self.dom('#list_bangumi_new .c-list .new .c-item')
videos=[]
for i in items:
name=i.find('.r-i .t').attr('title')
link=self.host+i.find('.r-i .t').attr('href')
d=pq(requests.get(url=link).text)
see=d(".info-count .info-count-item").eq(1).find('em').text()
intro=d('.info-row').eq(3).find('.info-desc').text()
videos.append(Video(name=name,see=see,intro=intro))
return videos测试运行一下:

哎呀,怎么回事,居然返回为空
这种情况下不要慌,如果代码没有错误,那么一般是由两种情况造成
没有选择到目标,页面是js动态加载的
我们先试下第一种情况,打开浏览器,f12,将选择字符串复制到console中运行下,我们这就是$('#list_bangumi_new .c-list .new .c-item')
![]()
可以选择到我们想要的目标,那看来是页面js动态加载了,那就方便我们了,我们就只要找到它的接口就好了,打开浏览器,f12,在network里面寻找一下就好了,
url:https://bangumi.bilibili.com/api/timeline_v2_global

这是一个item的信息,里面有我们想要的名字信息,那接下来就是去详情页寻找播放量和简介了,但是详情页链接在哪那,刚刚那个接口里并没有,我们f12,审查一下元素。

这里的链接是/anime/6439,刚刚的接口里并没有这个信息啊,那这个信息应该就是拼接出来的了,关键就是6439这个数字了,去刚刚那个接口信息里寻找一下,果然找到了一个season_id字段符合,那么详情页链接就构造如下:
detail_url = "https://bangumi.bilibili.com/anime/{season_id}"
那么接下来就是去分析详情页,爬去我们想要播放量和简介信息了,构造爬去代码如下:
see = d(".info-count .info-count-item").eq(1).find('em').text()
intro = d('.info-desc-wrp').find('.info-desc').text()
那么最终爬取类关键代码如下:
class bilibili(object):
recent_url = "https://bangumi.bilibili.com/api/timeline_v2_global" # 最近更新
detail_url = "https://bangumi.bilibili.com/anime/{season_id}"
def __init__(self):
self.dom=pq(requests.get('https://bangumi.bilibili.com/22/').text)
def get_recent(self):
'''最近更新'''
items=json.loads(requests.get(self.recent_url).text)['result']
videos=[]
for i in items:
name=i['title']
link=self.detail_url.format(season_id=i['season_id'])
d=pq(requests.get(url=link).text)
see = d(".info-count .info-count-item").eq(1).find('em').text()
intro = d('.info-desc-wrp').find('.info-desc').text()
videos.append(Video(name=name,see=see,intro=intro))
return videos运行一下:

很ok,那接下来把它做成命令行~
2.制作命令行版
用到的类库:
argparse:解析命令行参数
主要代码如下:
if __name__ == '__main__':
parser=argparse.ArgumentParser()
parser.add_argument('--recent',help="get the recent info",action="store_true")
parser.add_argument('--num',help="The number of results returned,default show all",type=int,default=0)
parser.add_argument('-v','--version',help="show version",action="store_true")
args=parser.parse_args()
if args.version:
print("bilibili 1.0")
elif args.recent:
b = bilibili()
b.get_recent(args.num)看下效果:

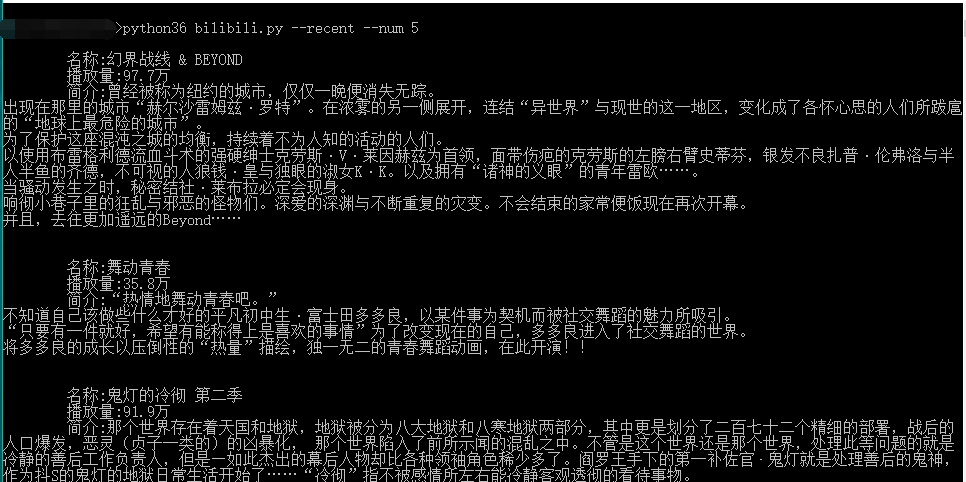
ok,大功告成,接下来大家就自由发挥添加更多的功能吧~:)
完整代码地址:https://github.com/taopeach1998/python-spider/blob/master/bilibili.py