【TensorFlow实战笔记】 迁移学习实战--卷积神经网络CNN-Inception-v3模型
IDE:pycharm
Python: Python3.6
OS: win10
代码已存档于github中
DL-tenserflow/The_migration_study_Inception-v3/
希望您 star一下,在此 感谢
迁移学习
1.所谓迁移学习,就是将一个问题上训练好的模型通过简单的调整使其适用于一个新的问题。
2.说白了就是别人已经训练好的强大的模型,你不需要去浪费时间训练,直接拿过来用,虽然这样最后的acc(准确率)可能会稍微低一些,但是可以节省大量的时间,还是非常划算的
几个须知的基本概念
1.Inception-v3模型 是一个 卷积神经网络(CNN)模型 (因为最近一直在忙着学,过一段时间会把经典的神经网络和CNN基本概念和基础知识全都补上)
2.瓶颈层:在最后一层全连接层之前统称为瓶颈层,将一个新的图像经过训练好的卷积神经网络直到瓶颈层的过程可以看成对图像进行特征提取的过程,输出的节点向量可以看做为图像的的一个更加精简并且表达能力更像的特征向量(这也是我感觉最为神奇的部分)
3.全连接层: 就是神经网络的每一层直接所有节点都相连。
这里使用的是经过模型之后再经过一层全连接层进行对图片的分类
前提准备
1.需要知道基本的神经网络的架构(前向传播算法、loss函数、优化算法、基本tf编程,这些我今后会整理)
2.Inception-v3模型 下载Inception-v3模型
3.数据集下载flower_photos
#模型和数据集介绍
1.模型的运用为tf的持久化,通过模型得到数据输入所对应的张量,以及计算瓶颈层所对应的张量
模型文件如图所示:

2.数据集:

数据集中有五个子文件夹,每个文件夹中名称即这个文件中所有照片的所属类别
每个文件夹中存放对应类别的分辨率大小不一的图片
#程序
以下程序有详细的标注
"""
@Author:Che_Hongshu
@Function: 迁移学习
@Modify:2018.2.21
"""
#导入相应的包
import glob
import os.path
import random
import numpy as np
import tensorflow as tf
from tensorflow.python.platform import gfile
#Inception-v3 模型瓶颈层的节点个数
BOTTLENECK_TENSOR_SIZE = 2048
#模型中代表瓶颈层张量的名称
BOTTLENECK_TENSOR_NAME = 'pool_3/_reshape:0'
#图像输入张量所对应的名称
JPEG_DATA_TENSOR_NAME = 'DecodeJpeg/contents:0'
#下载的谷歌训练好的Inception-v3模型文件目录
MODEL_DIR = './inception_dec_2015'
#Inception-v3模型文件名
MODEL_FILE = 'tensorflow_inception_graph.pb'
#因为一个训练数据会被使用很多次,所以可以将原始图像通过nception-v3模型计算得到的特征向量保存到文件中
CACKE_DIR = './bottleneck'
#输入图片的文件位置
INPUT_DATA = './flower_photos'
#验证的数据百分比
VALIDATION_PERCENTAGE = 10
#测试的数据百分比
TEST_PERCENTAGE = 10
#定义神经网络的设置
LEARNING_RATE = 0.01
STEPS = 4000
BATCH = 100
"""
函数说明: 得到图片的列表
Parameters:
testing_percentage-测试集的大小
validation_percentage-验证集的大小
Returns:
result-保存图片的dict
CSDN:
http://blog.csdn.net/qq_33431368
Modify:
2018-2-20
"""
def create_image_lists(testing_percentage, validation_percentage):
#所有的图片都存在这个字典里
result = {}
#获取当前目录下所有的子目录 包括此时的目录
sub_dirs = [x[0] for x in os.walk(INPUT_DATA)]
#用于过滤掉此时的目录
is_root_dir = True
#遍历flower_photos的子目录
for sub_dir in sub_dirs:
#过滤掉
if is_root_dir:
is_root_dir = False
continue
#获取当前目录下所有的有效图片文件格式
extensions = ['jpg', 'jpeg', 'JPG', 'JPEG']
#用于存放有效照片的文件夹,存放的是图片的名称
file_list = []
#返回path最后的文件名 在这里为 此时的文件夹的名称其实就是分类的名称
dir_name = os.path.basename(sub_dir)
for extension in extensions:
#得出的path为flower_photos/类别/*./照片类型 此时为绝对路径
file_glob = os.path.join(INPUT_DATA, dir_name, '*.'+extension)
#返回所有匹配的文件路径列表 glob.glob(file_glob)
file_list.extend(glob.glob(file_glob)) # 现将所有找到的右下图片加载到filelist上
if not file_list: continue
#通过目录名获取类别的名称
label_name = dir_name.lower()# 变为小写
#初始化当前类别得训练数据集、测试数据集、验证数据集
training_images = []
testing_images = []
validation_images = []
for file_name in file_list:
#得到有效图片的文件名
base_name = os.path.basename(file_name)
#随机得到0-100的数字
chance = np.random.randint(100)
#生成验证集,测试集,训练集
if chance < validation_percentage:
validation_images.append(base_name)
elif chance < (validation_percentage + testing_percentage):
testing_images.append(base_name)
else:
training_images.append(base_name)
# 生成各图片集的dict,key为类别的名称, value为图片的名称
result[label_name] ={
'dir': dir_name,
'training': training_images,
'testing': testing_images,
'validation': validation_images,
}
return result
"""
函数说明: 得到指定类别,训练集类别,编号的图片的最终地址
Parameters:
image_lists-所有图片的字典
image_dir-图片的路径
label_name-类别
index-编号
category-数据集类别
Returns:
full_path-最终地址
CSDN:
http://blog.csdn.net/qq_33431368
Modify:
2018-2-20
"""
def get_image_path(image_lists, image_dir, label_name, index, category):
#获取给定类别中所有图片的信息
label_lists = image_lists[label_name]
#根据所属数据集的名称获取集合中的全部图片信息
category_list = label_lists[category]
#图片的编号
mod_index = index%len(category_list)
#相应编号的图片的名称,即图片的文件名
base_name = category_list[mod_index]
#图片所在文件的名称
sub_dir = label_lists['dir']
#图片的最终地址
full_path = os.path.join(image_dir, sub_dir, base_name)
return full_path
"""
函数说明: 得到Inception-v3 模型处理后的图片的特征向量的文件地址
Parameters:
image_lists-所有图片的字典
image_dir-图片的路径
label_name-类别
index-编号
category-数据集类别
Returns:
get_image_path(image_lists, CACKE_DIR, label_name, index, category)
CSDN:
http://blog.csdn.net/qq_33431368
Modify:
2018-2-20
"""
def get_bottleneck_path(image_lists, label_name, index, category):
return get_image_path(image_lists, CACKE_DIR, label_name, index, category)
"""
函数说明: 用训练好的Inception-v3模型处理一张图片,得到这个图片的特征向量
Parameters:
sess-会话
image_data-图片数据
image_data_tensor-图片的张量
bottleneck_tensor-瓶颈层张量
Returns:
bottleneck_values-图片的特征向量(一维)
CSDN:
http://blog.csdn.net/qq_33431368
Modify:
2018-2-20
"""
def run_bottleneck_on_image(sess, image_data, image_data_tensor, bottleneck_tensor):
bottleneck_values = sess.run(bottleneck_tensor, {image_data_tensor: image_data})
#四维数组压缩成一位数组
bottleneck_values = np.squeeze(bottleneck_values)
return bottleneck_values
"""
函数说明: 如果已经存有这个特征向量直接返回
若没有,则建立文件夹,计算对应图片的特征向量
并且存入对应文件夹(以txt的格式存储)
Parameters:
sess-会话
image_lists-存有所有图片数据字典
label_name-类别
index-编号
category-数据集的种类
jpeg_data_tensor-图片数据张量
bottleneck_tensor-瓶颈层张量
Returns:
bottleneck_values-图片的特征向量(一维)
CSDN:
http://blog.csdn.net/qq_33431368
Modify:
2018-2-21
"""
def get_or_create_bottleneck(sess, image_lists, label_name, index,
category, jpeg_data_tensor, bottleneck_tensor):
#获取相应类别的图片
label_lists = image_lists[label_name]
#获取图片的子文件夹名称
sub_dir = label_lists['dir']
#缓存此类型图片特征向量对应的文件路径
sub_dir_path = os.path.join(CACKE_DIR, sub_dir)
#如果不存在即还没有得出特征向量,则创建文件夹
if not os.path.exists(sub_dir_path):
os.makedirs(sub_dir_path)
#得到Inception-v3 模型处理后的这个特定图片的特征向量的文件地址
bottleneck_path = get_bottleneck_path(image_lists, label_name, index, category)
#如果不存在则进行计算特征向量并保存文件
if not os.path.exists(bottleneck_path):
#图片具体路径
image_path = get_image_path(image_lists, INPUT_DATA, label_name, index, category)
#读入图片的原始数据
image_data = gfile.FastGFile(image_path, 'rb').read()
#得到这个图片的对应的特征向量(一维)
bottleneck_values = run_bottleneck_on_image(sess, image_data, jpeg_data_tensor,bottleneck_tensor)
#用逗号连接成一个string 特征向量用string的格式保存
bottleneck_string = ','.join(str(x) for x in bottleneck_values)
#保存到txt文件中
with open(bottleneck_path, 'w') as bottleneck_file:
bottleneck_file.write(bottleneck_string)
else:
#如果存在特征向量的具体路径 说明已经计算出这个特定图片的特征向量
with open(bottleneck_path, 'r') as bottleneck_file:
bottleneck_string = bottleneck_file.read()
#还原特征向量
bottleneck_values = [float(x) for x in bottleneck_string.split(',')]
return bottleneck_values
"""
函数说明: 得到随机的一个batch的图片作为训练数据
Parameters:
sess-会话
n_classes-类别的个数
image_lists-存有所有图片数据字典
how_many-想得到的数据集的大小
category-数据集的种类
jpeg_data_tensor-图片数据张量
bottleneck_tensor-瓶颈层张量
Returns:
bottlenecks-特征向量data
ground_truths-label
CSDN:
http://blog.csdn.net/qq_33431368
Modify:
2018-2-21
"""
def get_random_cached_bottlenecks(sess, n_classes, image_lists, how_many,
category, jpeg_data_tensor, bottleneck_tensor):
bottlenecks = []
ground_truths = []
for _ in range(how_many):
#得熬一个随机的图片label
label_index = random.randrange(n_classes)
label_name = list(image_lists.keys())[label_index]
#得到一个随机的图片编号
image_index = random.randrange(65536)
#得到一个特定数据集的随机编号随机label的图片的特征向量
bottleneck = get_or_create_bottleneck(sess, image_lists, label_name, image_index
, category, jpeg_data_tensor, bottleneck_tensor)
#这个其实就相当于表示上面这个图片特征向量对应的label
ground_truth = np.zeros(n_classes, dtype=np.float32)
ground_truth[label_index] = 1.0
#特征向量的集合list 其实就是一个随机的训练batch
bottlenecks.append(bottleneck)# data
ground_truths.append(ground_truth)# label
return bottlenecks, ground_truths
"""
函数说明: 得到全部的测试集数据
Parameters:
sess-会话
image_lists-存有所有图片数据字典
n_classes-类别的个数
jpeg_data_tensor-图片数据张量
bottleneck_tensor-瓶颈层张量
Returns:
bottlenecks-特征向量data
ground_truths-label
CSDN:
http://blog.csdn.net/qq_33431368
Modify:
2018-2-21
"""
def get_te_bottlenecks(sess, image_lists, n_classes, jpeg_data_tensor, bottleneck_tensor):
bottlenecks = []
ground_truths = []
#得到label种类的一个列表
label_name_list = list(image_lists.keys())
#python的内置函数enumerate得到label_index为类别的编号, label_name为这个类别的名称
for label_index, label_name in enumerate(label_name_list):
category = 'testing'
#index为图片的编号, unused_base_name为 图片的名称 图片为特定label的测试集
for index, unused_base_name in enumerate(image_lists[label_name][category]):
#得到特征向量
bottleneck = get_or_create_bottleneck(sess, image_lists, label_name, index
, category, jpeg_data_tensor, bottleneck_tensor)
#得到label数据
ground_truth = np.zeros(n_classes, dtype=np.float32)
ground_truth[label_index] = 1.0
# 特征向量的集合list 其实就是一个随机的训练batch
bottlenecks.append(bottleneck)# 特征向量
ground_truths.append(ground_truth)# label
return bottlenecks, ground_truths
"""
函数说明: 主函数
CSDN:
http://blog.csdn.net/qq_33431368
Modify:
2018-2-21
"""
def main(argv=None):
# 获取所有图片
image_lists = create_image_lists(TEST_PERCENTAGE, VALIDATION_PERCENTAGE)
# 得到类别的个数
n_classes = len(image_lists.keys())
# 读取训练好的Inception-v3模型
with gfile.FastGFile(os.path.join(MODEL_DIR, MODEL_FILE), 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
# 加载读取这个模型,得到瓶颈层张量,和数据输入所对应的张量
bottleneck_tensor, jpeg_data_tensor = tf.import_graph_def(graph_def,
return_elements=[BOTTLENECK_TENSOR_NAME, JPEG_DATA_TENSOR_NAME])
# 定义新的神经网络输入,即新的图片经过模型之后前向传播到达瓶颈层时的节点取值(特征提取)
bottleneck_input = tf.placeholder(
tf.float32, [None, BOTTLENECK_TENSOR_SIZE], name='BottleneckInputPlaceholder')
#定义新的标准答案输入
ground_truth_input = tf.placeholder(tf.float32, [None, n_classes], name='GroundTruthInput')
#定义一层全链接神经网络
with tf.name_scope('final_training_ops'):
# 权重和偏置
weights = tf.Variable(tf.truncated_normal(
[BOTTLENECK_TENSOR_SIZE, n_classes], stddev=0.1))
biases = tf.Variable(tf.zeros([n_classes]))
# 求出前向传播算法的结果
logits = tf.matmul(bottleneck_input, weights)+biases
#通过激活函数去线性化
final_tensor = tf.nn.softmax(logits)
#定义交叉损失函数
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(logits=logits, labels=ground_truth_input)
#算平均损失
cross_entropy_mean = tf.reduce_mean(cross_entropy)
#优化算法来优化损失函数
train_step = tf.train.GradientDescentOptimizer(LEARNING_RATE).minimize(cross_entropy_mean)
#计算正确率
with tf.name_scope('evaluation'):
#argmax(a,axis=1)返回每一行中最大值的索引
#equal 相等为 True 不相等为False
correct_prediction = tf.equal(tf.argmax(final_tensor, 1), tf.argmax(ground_truth_input, 1))
#cast将True转换为1.0 False转换为0.0 之后算平均就为正确率
evaluation_step = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
#训练过程
for i in range(STEPS):
#获取一个batch训练数据
train_bottlenecks, train_ground_truth = \
get_random_cached_bottlenecks(sess, n_classes,
image_lists, BATCH,
'training',
jpeg_data_tensor,
bottleneck_tensor)
sess.run(train_step, feed_dict={bottleneck_input: train_bottlenecks,
ground_truth_input: train_ground_truth})
#在验证数据上 测试正确率
if i % 100 == 0 or i + 1 == STEPS:
validation_bottlenecks, validation_ground_truth =\
get_random_cached_bottlenecks(sess, n_classes,
image_lists, BATCH,
'validation',
jpeg_data_tensor,
bottleneck_tensor)
validation_acc = sess.run(evaluation_step, feed_dict={
bottleneck_input: validation_bottlenecks, ground_truth_input: validation_ground_truth})
print('Step %d: Valdation acc on random sampled %d examples = %.1f%%'%
(i, BATCH, validation_acc*100))
#在测试集测试正确率
test_bottlenecks, test_ground_truth = \
get_te_bottlenecks(sess, image_lists, n_classes, jpeg_data_tensor, bottleneck_tensor)
test_acc = sess.run(evaluation_step, feed_dict={
bottleneck_input: test_bottlenecks, ground_truth_input: test_ground_truth})
print("Final test acc = %.1f%%" % (test_acc*100))
if __name__ == '__main__':
tf.app.run()
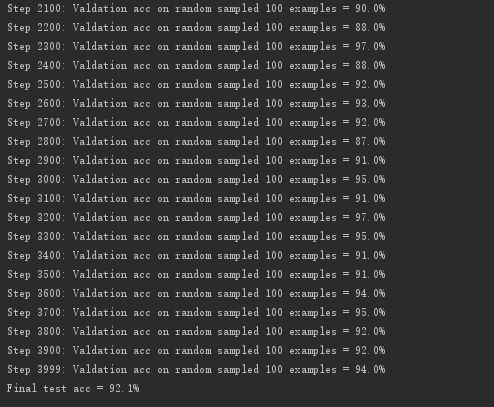
经过大概40多分钟(30分钟的处理数据得到特征文件,训练10分钟)的等待 结果如下