Generative Adversarial Nets——NIPS2014
GAN势如破竹地被Goodfellow提出,Goodfellow师从Bengio,2014年的这一篇Generative Adversarial Nets的发表也是第一次GAN被完整的提出来。
论文翻译:https://m.2cto.com/kf/201610/552124.html
Goodefellow2016于NIPS上的演讲:https://channel9.msdn.com/Events/Neural-Information-Processing-Systems-Conference/Neural-Information-Processing-Systems-Conference-NIPS-2016/Generative-Adversarial-Networks
Goodefellow2016于NIPS上的演讲译文:https://ask.julyedu.com/question/7664
目录
1、背景
2、文章脉络
3、模型架构
4、具体理解:
1)问题和动机:
2)解决方法:https://blog.csdn.net/on2way/article/details/72773771
3)实验:
4)结论:
5)未来展望:
5、分析
1、背景
GAN的提出缘起于Goodfellow庆祝他的一个朋友博士学习结束,酒后饭桌上大家提及想要“试图用数学方法确定进入图片的所有内容,将这些统计信息输入一台机器,以便它可以自己创建照片”。然而Goodfellow却认为这是不可能人为完成的,因为要统计的量太多,没人能全部记下来,但是神经网络可以教会机器如何建立逼真的图片。
一些知识:
深度玻尔兹曼机:https://blog.csdn.net/u014314005/article/details/80583475
GSN生成随机网:https://baike.baidu.com/item/%E7%94%9F%E6%88%90%E9%9A%8F%E6%9C%BA%E7%BD%91%E7%BB%9C/22800088?fr=aladdin && https://blog.csdn.net/zhq9695/article/details/86688525
变分自编码器(VAEs):https://spaces.ac.cn/archives/5253
噪声对比估计(NCE):https://blog.csdn.net/littlely_ll/article/details/79252064
PM模型:PM模型与GAN有一些争议,主要是PM的作者在NIPS2016大会上直接怼了Goodfellow,但其实Goodfellow在2014第一次以论文形式提出GAN时就已经在文中说明了PM模型与GAN的区别,好吧,我就附上从PM到GAN的一篇帖子——https://blog.csdn.net/omnispace/article/details/77790500
另外,附上Goodfellow关于GAN的一些问答:https://baijiahao.baidu.com/s?id=1595081179447191755&wfr=spider&for=pc
GANs介绍:https://www.cntofu.com/book/85/dl/gan/gan.md
2、文章脉络
Introduction——>Related work——>Adversarial nets——>Theoretical Results——>Experiments——>Advantages and disadvantages——>Conclusions and future work
3、模型架构
整个目标函数其实就是一个最小最大化博弈:![]()

4、具体理解
1)问题和动机:
判别模型和生成模型是深度学习领域的两大模型。然而判别模型已经研究的较好(由于反向传播、dropout、relu激活函数的出现),生成模型却由于概率计算困难(最大似然估计计算难)加上不好使用relu函数,使其发展较为缓慢。于是本文提出一种生成模型来避开或解决这些问题。
有了生成模型。或许我们就可以生成一些数据集;可以学习已知数据的概率分布,从而为无监督学习提供新的方向
详细动机Goodfellow在2016NIPS大会上在第一部分做出了详细报告。2016NIPS
前人工作:
玻尔兹曼机是一种比较成功的生成模型,由于配分函数Z难以处理,必须用最大似然梯度来处理。
GSN(Generative stochastic networks生成随机网)不用大量来自玻尔兹曼机的近似而用反向传播训练生成网络,该方法进一步消除了马尔科夫链(?)。
VAEs(variable auto-encoders变分自编码器)中的编码器不是用来编码的,是用来算均值和方差的。文章中写到:与对抗的生成网络相似,变分自编码器为可微分的生成网络配对第2个网络。与对抗的生成网络不同的是,VAE 中的第2个网络是一个使用近似推理的识别模型。GANs 要求对可见单元微分,故不能对离散数据建模。而 VAEs 要求对隐含单元微分,因而不能对离散的潜在变量建模(?)。
NCE(noise -contrastive estimation噪声对比估计)通过学习该模型的权重来训练生成模型,用之前训练好的模型作为噪声分布,提高了训练一系列模型的质量。NCE 是本质上与对抗的网络游戏中的正式竞争相似的一种非正式竞争机制。NCE 关键的局限为它的“判别器”是由噪声分布和模型分布的概率密度比重来定义,从而要求评估和反向传播两个概率密度。
PM模型(predictability minimization可预见性最小化)与GAN相关性最大,但是其二者有着本质区别:1) 本文工作中,网络间的竞争是唯一的训练标准,足以训练网络。可预测性最小化仅是鼓励神经网络中隐含单元在完成其它任务的同时,统计上也相互独立的一个正则项;竞争并不是主要的训练标准。2) 竞争的本质不同。可预测性最小化中,两个网络的输出相互比较,一个网络试图使输出相似,而另一个网络试图使输出不同;输出为标量。GANs 中,一个网络生成一个丰富的高维向量来作为另一个网络的输入,并尝试选择使另一个网络不知如何判别的向量为输入。3) 学习过程不同。可预测性最小化被描述为一个最小化目标函数的优化问题,学习去逼近目标函数的最小值。GANs 基于最大最小游戏,而不是一个优化问题,且一个 Agent 寻求最大化值函数,另一个 Agent 寻求最小化值函数。游戏在鞍点处终止,此处是关于一个 Agent 的策略的最小值,和关于另一个 Agent 的策略的最大值。
2)解决方法:https://blog.csdn.net/on2way/article/details/72773771
我们将最小最大化函数看作两部分,先优化D,再优化G,本质上是两个优化问题。开始时给生成网络一个随机噪声,生成假数据集,然后用假数据集和真数据集去训练判别网络,将训练好的判别网络原模原样搬下来接在生成假数据集的生成网络后面,用刚刚生成的假数据集当作真数据集(将标签由0变为1)来训练搬下来的这个网络,对生成网络的训练实际上是对生成-判别网络串接的训练。

文中第四部分是对这个目标函数以及算法这么优化是有根据的、合理的一些证明以及说明。
3)实验:
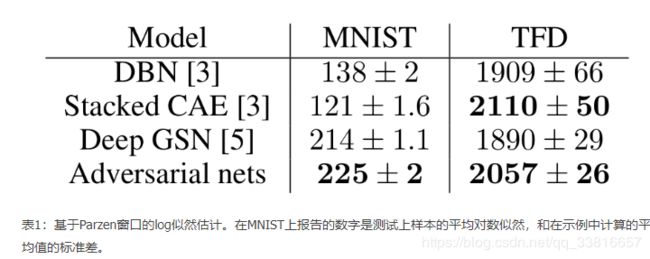
在数据集 MNIST,Toronto Face Database 和 CIFAR-10 上训练对抗的生成网络。生成器用 ReLU 与 Sigmoid 激活单元的混合,而判别器用 maxout 激活单元。训练判别网络时用 Dropout。虽然理论框架可在生成器的中间层用 Dropout 和其它噪声,但这里仅在生成网络的最底层用噪声输入。


4)结论:
根据实验生成的图片不敢说比其他算法生成的图片要好,但是可以看出GAN存在一定 的潜力。
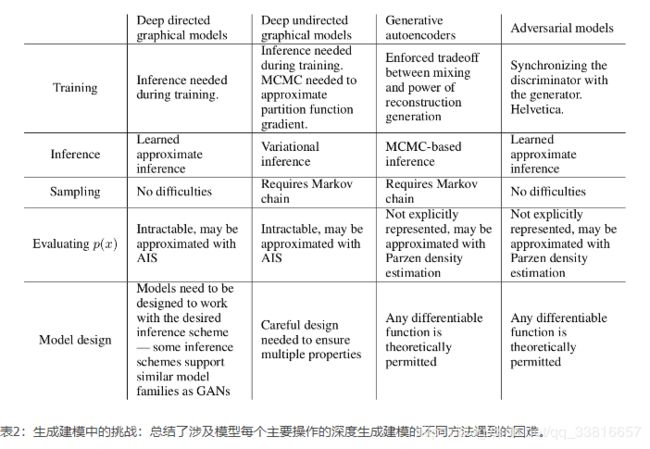
这个框架和先前的模型相比有优点也有缺点。缺点主要在于pg(x)pg(x)没有明确表示,并且在GG训练期间DD必须很好地同步(尤其,没有更新DD的时候,GG一定不能训练的太多,防止“the Helvetica scenario”即GG将太多的z值折叠到x来有足够的多样性来模拟pdatapdata),正如一个玻尔兹曼机的负链必须在学习步骤之间保持最新。优点是不需要马尔科夫链,仅仅使用反向传播获得梯度,在学习期间也不需要推理,并且将多种函数合并到模型。表2总结了生成对抗网络和其它生成模型的比较。
上述优点主要是计算。对抗模型也从生成网络获得一些统计优势,不是直接使用数据示例更新, 而是流经判别器的梯度。这意味着输入的组件不是直接复制到生成器的参数。另一个对抗网路的优点是它们可以表示非常清晰甚至退化的分布,而基于马尔科夫链的方法要求分布有点模糊以便链能够在模式之间混合。
5)未来展望:
该框架允许许多直接的扩展:
1) 添加c至G和D的输入,可获得条件的生成模型p(x|c)。
2) 给定x,为预测z,训练任意的网络可学习近似推理。类似于 wake-sleep 算法训练出的推理网络,但训练推理网络时可能要用到训练完成后的固定的生成网络。
3) 通过训练一组共享参数的条件模型,可以近似地共享所有条件p(xs|xslashedD)p(xs|xslashedD),其中SS是xx索引的子集。从本质上说,可以使用对抗网络来实现确定性MP-DBM的随机扩展。
4) 半监督学习:当标签数据有限时,判别网络或推理网络的特征不会提高分类器效果。
5) 效率改善:为协调G和D设计更好的方法,或训练期间确定更好的分布来采样z,从而加速训练。
5、分析
通过阅读本文,感觉“博弈论”(Game Theory)的思想确实在现实生活中具有很大的应用价值。
二元博弈的特点是什么?
两个具有互斥性的优化目标或任务,在博弈的过程中,保持一方不变优化另一方,如此交替,动态优化自身共同进步。两个目标分别给对方提供一把“尺”作为衡量,博弈过程中,“尺”会越来越严格,以此形成反馈,最终实现两者最优。
互斥性体现在哪?
两个目标相反,必定是若一方强,则另一方弱。不可能在优化过程中始终保持一强一弱,这样强的一方就无法得到反馈,从而优化自己,所以是交替强弱。若一方强一方弱,则是一方始终在追赶另一方。
极限/最优的判断?
生成对抗网络的极限在于,生成器生成了和真图一样的假图,使得判别器对于无论来自自然图像还是生成图像的输出都为1/2。
引用Goodfellow在NIPS上的总结:“GANs相对比较新,仍需要进一步研究,特别的,GANs要求在高维、连续、非凸的策略中找到纳什均衡。研究人员应该努力发展出更好的理论依据和训练算法。GANs对于图像生成、操纵系统等许多方面都具有重要意义,并有可能在未来应用到更广的领域。”