2017CS231n李飞飞深度视觉识别笔记(九)——CNN架构
第九讲 CNN架构
上一章中讨论了不同的深度学习框架,包括有TensorFlow、PyTorch、Caffe,这一章中将会讨论CNN架构方面的内容。
在这里会深入探讨那些ImageNet比赛获胜者所用的最多的神经网络架构,比如AlexNet、VGG、GoogleNet和ResNet。
(1)LeNet
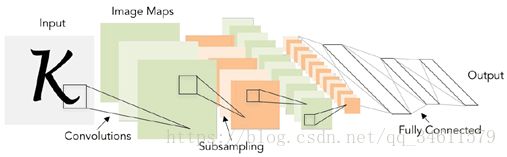
它可以看作是通信网络的第一个实例,并在实际应用中取得成功,使用步长为1、大小为5*5的卷积核来对第一层进行输入,并且同样的卷积层和池化层有好几层以及在网络的最后有一些全连接层,它在数字识别领域方面的应用去得到了成功。
(2)AlexNet

它是第一个在ImageNet的分类比赛中获得成功的大型卷积神经网络,同样也是第一个基于深度学习的网络结构;它的基础架构是卷积层、池化层、归一化层的混合,最后是一个全连接层。
它的输入是227*227*3的图像矩阵,步长为4,大小为11*11的卷积核有96个,算出第一个卷积层的输出数据体积为:(227-11)/4+1=55,那么最后输出的空间维度是55*55*96;输出的参数为11*11*3*96=35K。
这个架构中第一次使用了ReLU非线性函数;使用本地相应归一化层,通过相邻通道来归一化响应,但是这并不太有效果,因为它增加了大量的数据;为了得到更好的效果,还使用了模型集成训练多个模型对它们取平均从而获得性能上的提升。
(3)VGGNet

VGG的思想是一个非常深的网络,包含非常小的卷积核,它从AlexNet的8层扩展到了16~19层,关键是它使用很小的卷积核,只用3*3的卷积核。
问题:为什么使用小的卷积核?
答:当使用小的卷积核可以得到比较小的参数量,然后可以利用堆栈更多的参数不使用大的卷积核,这样可以尝试而更多的网络和卷积,最终的效果比用7*7的卷积核有效接收范围更好些。
问题:3*3的卷积核步长1的有效接收范围是什么?
答:输入的全部空间区域,保证了3层网络的顶层。
(4)GoogleNet

GoogleNet是一个更深的网络结构,它有22层,它尝试设计一个网络结构可以进行高效计算,采用了inception模块,然后简单在每一层的顶部搭这个模块,网络中没有全连接层,节省了大量参数,比AlexNet少了12倍。
那么什么是inception模块呢?
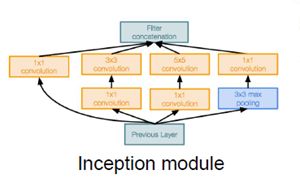
Inception模块中隐含的思想是想要设计一个好的局部网络拓扑,有了拓扑的想法就可以把它视为一个网络,然后堆放大量局部拓扑在每一层的顶部;在局部网络中调用inception模块要做的是对进入相同层的相同输入并行应用不同的滤波操作,来自前面一层的输入然后进行不同的卷积和池化操作,这样就可以在不同的层得到不同的输出,这些层将所有的滤波器输出并在深度层上串联起来,然后在最后得到一个张量输出。
案例:
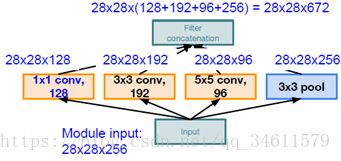
这里输入的Inception模块是28*28*256,经过不同的卷积核处理后得到的输出为28*28*672,保留了相同的尺寸扩充了深度。
为了减少计算量,在其中可以尝试添加一层瓶颈层(1*1的卷积层)帮助降低计算量,GoogleNet做的就是初始化这些模块,然后将它们放入堆栈中。

GoogleNet有22层,同时它有一个高效的Inception模块,没有全连接层,参数向量只有AlexNet的1/12。
(5)ResNet
ResNet这个想法是深度网络的一次革命,它比之前提到的所有神经网络架构都要深,有152层,也叫做残差网络。
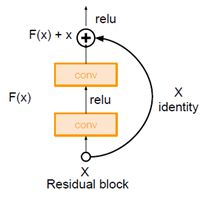
当在普通卷积神经网络上堆叠越来越多的层时,会发生什么?仅仅是通过持续扩展就能得到更深的层以及取得更好的效果吗?
答:显然不是,模型虽然更深却也会变现的更差,如下图的比较所示。

所以解决方法是不仅仅堆叠这些层而是让每层都尝试学习一些所需函数的底层映射,残差块的输入只是传输进来的输入,使用这些块尝试并拟合残差映射而不是直接映射;与其直接学习H(x),需要在输入上加上或减去什么,F(x)=H(x)-x,F(x)就是所说的残差。
下面是上述几种网络架构的训练效果图:

很明显ResNet是最近一段时间来表现最好的模型,如果想寻找某种算法 训练一个新的神经网络模型最好尝试使用ResNet。
(6)其他的架构
NiN是神经网络研究领域的第一个网络模型,它在2014年是GoogleNet和ResNet模型的先驱,瓶颈层的这个概念是从这里开始的。

ResNet的改进:
通过改进ResNet的模型设计,调整了ResNet块路径中的层,并且这个新的结构能够实现一种更直接的路径以便于在整个信息网络中传播,然后就可以得到能够实现整个网络传播的路径,并且能再次反向传播回去,这样模型可以提供更好的性能。
虽然ResNet使网络层数变得更深,也增加了这些残差网络的连接,另一种想法是残差量是是一个十分重要的影响因素,存在这种残差结构并不一定代表这个网络层数就很多,所以使用更宽的残差模块,这就意味着转换成有更多的卷积核,结果表明使用更宽的残差模块仅使用50层的宽残差网络,它的表现就能优于ResNet原来的152层网络。
ResNeXt这是另一种改进结构,为了解决宽度问题,但它并不是通过增加架构中的卷积核来增加残差模块的宽度,而是在每个残差模块内建立多分支,这样也可以达到宽网络的效果同时与Inception模块也有些相似,运动了一些平行运算对各层进行并行运算。
另一种改善ResNet的思路是运用随机深度的思想,当网络越来越深,往往会碰到梯度消失的问题;因此,最初的想法是在训练时让网络变得更“浅”,会随机抛弃一组子层集,对于一个子层集会抛弃其权重,只把它们作为恒等连接,现在网络更浅了就可以更好地进行反向传播。这就是一种随机抛弃法。
这里有一种叫FractaNet的网络结构,它的观点是引入残差并不是必须的,关键在于有效的从浅网络转型为深层网络;因此,使用了一种分形结构:

同时存在浅层和深层路径到达输出值,这里不同的路径通过抛弃子路径的方式来训练具有了dropout的特色。
DenseNet即密集连接卷积网络是另一具有特色的网络结构,它使用称为密集块,每个块中每层都与其后所有层连接,以前馈的形式连接,因此,在这一区块内,对区块的输入也是对其他所有其他各卷积层的输入,会计算出每个卷积层的输出值,然后这些值集中共同作为下一个卷积层的输入;这一方法能够缓解梯度消失的问题。

如何让网络高效的运行非常重要,在最近提出的网络结构SqueezeNet中,它关注的是高效网络,它由一个个fire模块组成,每个模块有一个Squeeze层(挤压层)和许多1*1的卷积核,接着再传递给一个扩大层;利用这样的网络结构可以达到AlexNet水平的准确率,但参数只需1/50,网络也可以继续压缩为1/500,所以一个未来的方向:如何有效压缩网络大小。
总结:
这一章中主要讲了4个主要的网络架构,同时也了解了其他的一些网络模型,所以对这些网络结构可以多去了解一下,细看论文的讲解内容。