实例级语义SLAM: MaskFusion:对多个运动目标进行实时识别、跟踪和重构(翻译)(一)
最近在研究MaskFusion这个语义SLAM的框架,看了看论文,搭了搭环境,因为源码刚刚出所以研究的人比较少,我自己其中也遇到很多问题,有的解决了,有的依然困惑着,孑然前行的路是注定孤独的,分享互助才能更快的进步。想着把自己做的工作分享出来,若有一起研究的,相互交流,岂非幸事?
MaskFusion:对多个运动目标进行实时识别、跟踪和重构
Martin Runz Maud Buffier Lourdes Agapito
计算机科学系 英国伦敦大学学院
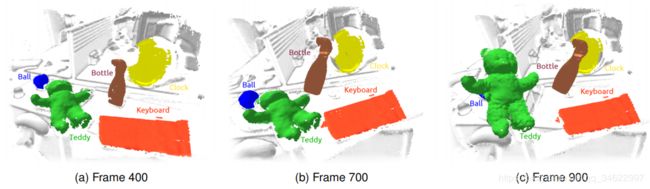

图1:一系列3帧,说明了MaskFusion的识别、跟踪和映射能力。第一行突出显示了系统的输出:重建背景(白色)、键盘(橙色)、时钟(黄色)、运动球(蓝色)、泰迪熊(绿色)和喷雾器(棕色)。当相机在整个拍摄过程中处于运动状态时,瓶子和泰迪熊分别从第500帧和第690帧开始移动。注意,MaskFusion明确地避免重构与持有物品的人相关的几何图形。第二行显示分割神经网络生成的RGBD输入帧和语义掩码作为叠加。
摘 要
我们提出了MaskFusion,一个实时的、对象感知的、语义的和动态的RGB-D SLAM系统,它超越了传统的输出静态场景的纯几何地图的系统。MaskFusion识别、分割和分配语义类标签给场景中的不同对象,同时跟踪和重构它们,即使它们独立于摄像机移动。当RGB-D摄像机扫描一个杂乱的场景时,基于图像的实例级语义分割创建语义对象掩码,从而支持实时对象识别和为世界地图创建对象级表示。与之前的基于是别的SLAM系统,MaskFusion不需要已知的对象模型,它可以识别,并可以处理多个独立的运动。MaskFusion充分利用了使用实例级语义分割的优势,使语义标签能够融合到对象感知地图中,这与最近启用语义的SLAM系统执行三维体素级语义分割不同。我们展示了增强现实应用程序,展示了其独特的特性MaskFusion输出的地图:实例感知、语义和动态。代码将提供开源。
关键词:视觉SLAM SLAM 视觉 跟踪 建图 实时检测 增强现实 机器人
e-mail: [email protected]
e-mail: [email protected]
e-mail:[email protected]
http://visual.cs.ucl.ac.uk/pubs/maskfusion/
以上为作者的邮箱和项目网址信息。
QQ交流群:859814367 欢迎SLAM交流学习
引 言
从移动摄像机获取的图像序列中进行3D感知是计算机视觉、机器人技术、人机交互等领域的一项基础性工作。数十年来,视觉SLAM(同步定位和地图构建)系统一直致力于同时解决摄像机在探索未知地点时的位置跟踪和创建环境3D地图的任务。它们的实时能力已经把SLAM方法变成了雄心勃勃的应用的基石,如自动驾驶、机器人导航以及增强/虚拟现实。研究视觉SLAM进展速度快,从早期作品,重构稀疏地图只有几十或几百个特性使用过滤技术[11],平行跟踪和映射方法,可以利用计算昂贵的批处理优化技术映射线程产生精确的地图与成千上万的地标[25 30],以当代的方法,可以重建完全密集的环境地图[33、34、50]。随着越来越多的SLAM增强现实应用进入到消费产品和手机应用中,这一趋势对增强现实的影响是巨大的。尽管取得了这些进步,SLAM方法及其在增强现实中的应用在两个领域中仍处于非常初级的阶段。
(a)大多数SLAM方法依赖于这样一种假设,即环境大多是静态的,移动的对象最多只能被检测为异常值并被忽略。虽然有些第一步采取非刚性的和动态场景的重建、激动人心的结果是在重建一个单一的非刚性的对象[ 12,20,32,53]或多个移动刚性物体[39],设计一个精确的和健壮的SLAM系统,可以处理任意动态和非刚性的场景仍然是一个开放的挑战。
(b)大多数SLAM系统提供的输出是一个纯粹的环境几何图。添加语义信息是相对近期[6, 8, 28,40,44]的,并且识别主要是限于少数已知的对象实例的三维模型可提前得知[6 8,40,46]或每个3 D地图点划分成一组固定的语义类别没有区分对象实例[28,44]。
贡 献:
我们的方法的新颖之处在于在同一系统内朝着解决这两个限制取得进展。
MaskFusion是一个实时的SLAM系统,可以在物体的层面上表现场景。它可以识别、检测、跟踪和重构多个运动的刚性对象,同时可以精确地分割每个实例并为其分配一个语义标签。我们利用联合的输出:(i)Mask- RCNN [15],这是一个强大的基于图像的实例级分割算法,可以预测80个对象类的对象类别标签,以及(ii)一种基于几何的分割算法,这将根据深度和表面法线线索生成一个对象边缘映射,以增加目标掩码中对象边界的准确性。
我们的动态SLAM框架将这些精确的对象掩码作为输入来跟踪和融合多个移动对象(以及静态背景),同时将语义图像标签传播到时间一致的3D地图标签中。使用instance-aware语义分割的主要优势在标准像素级语义分割(如大多数先前的语义SLAM系统[40 6 8 28,40,44,,46]是它提供了准确的对象掩码和分割不同的实例对象的能力,属于同一个对象类别把他们替换为(当做)单一的一个
MaskFusion相对于以前的语义SLAM系统[6、8、28、40、44、46]的额外优势是不需要场景是静态的,因此可以检测、跟踪和建图多个独立运动的物体。通过提供更丰富的地图(不仅包括背景,还包括运动物体的详细几何形状),并通过改进物体和摄像机姿态的预测和估计,维持运动物体的内部3D表示(而不是将它们视为离群值)极大地改进了整个SLAM系统。
另一方面,MaskFusion相对于之前的动态SLAM系统[3,39]的优势在于它可以实时地利用大量对象类的语义信息增强动态地图。它不仅可以检测单个对象(由于使用了Mask-RCNN [15]),还可以为其对应的3D地图点对象分配语义标签。并且它也可以精确分割每个单独的对象实例。表1总结了我们在其他实时语义SLAM和动态SLAM系统中的贡献。
其结果是一个多用途的系统,可以在对象及其语义标签层次上表示一个动态场景,在机器人和增强现实等领域有许多应用。我们演示如何将对象的标签用于不同的目的。例如,我们经常发现,能够检测和分割人,可以让我们意识到他们的存在,忽略那些像素,而是专注于他们正在操作的对象。我们展示了这在对象操作任务中是如何有用的,因为它可以改进对象跟踪,即使对象是由人手移动和遮挡的。
2 相关工作
可视SLAM领域有着悠久的历史,它为在重构环境地图的同时联合跟踪移动相机的姿态问题提供了解决方案(最近的一项调查见[14])。廉价的消费级RGB-D相机的出现——如微软Kinect——刺激了进一步的研究,并使密集实时方法的飞跃成为可能[23,24,33]。
Dense RGB-D SLAM:该方法能够准确绘制室内环境,在增强现实技术和机器人技术中得到了广泛的应用。KinectFusion[33]证明了一种基于截断有符号距离函数(TSDF)的地图表示方法可以在小环境中实现快速、鲁棒的建图和跟踪。后续工作[38,51]表明,通过选择合适的数据结构,同样的原理也适用于大规模环境。
表面元素(surfels)在计算机图形学中有着悠久的历史并在计算机视觉中得到了广泛的应用[5,49]。最近,[18, 23]还引入了基于面元的地图表示到RGBD-SLAM领域。面元的地图类似于点云,不同之处在于,除了位置,每个元素都编码了局部表面属性-通常是一个半径和法线。与基于TSDF的地图不同,面元云具有自然的内存效率,并且避免了典型的基于TSDF的融合方法由于在建图和跟踪之间交换表示而带来的开销。Whelan等人[50]提出了一种基于面元的RGBD-SLAM系统,适用于大型环境的局部和全局闭环。
Scene segmentation:计算机图形学[7]与视觉[9,17,22,28,46]社区在目标和场景分割方面投入了大量的精力。分割数据可以扩展视觉跟踪和地图系统的功能,例如,通过允许机器人检测对象。提出了一些分割方法基于表面法线几何性质的RGBD数据[9,13, 22, 45],主要通过假设物体是凸的。虽然基于几何图形的分割系统的明显优点是能够产生精确的对象边界,但是它们的缺点是通常会导致过度分割,并且不能传递任何语义信息。
Semantic scene segmentation:另一项工作[2,26,52]是利用马尔可夫随机字段(MRFs)对3D场景进行语义分割。这些方法需要标记的3D数据,然而,与标记的二维图像数据相比,标记的三维数据并不容易获得。这三个工作都涉及到训练数据的手工标注,这就是一个很好的例子。数据集包含孤立RGBD帧,如NYUv2 [31],在这里不适用,需要大量的努力来构建一致的重构数据集进行分割,正如Dai等人最近展示的[10]。
Semantic SLAM:受到卷积神经网络成功的推动[15,36,37],Tateno等人[44]和McCormac等人[28]将深层神经网络集成到实时SLAM系统中。由于推理完全基于2D信息,因此无需使用3D标注数据。由此产生的系统提供了将标记图像数据融合到分割的三维地图的策略。Hermans等人早期的工作[19]实现了一个类似的方案,使用随机决策森林分类器。然而,由于系统不考虑对象实例,独立跟踪多个模型是不可能实现的。
Dynamic SLAM:动态SLAM主要有两种场景:

表1:MaskFusion与其他实时SLAM系统的性能对比。与之前的语义相反SLAM系统[28,40,44,46],MaskFusion既是动态的(即使对象的运动与摄像机不同,它也会重构对象),又是分割对象实例。不像密集的非刚性重建系统[12,32,53],它可以重建整个场景,并为不同的对象添加语义标签。注意,虽然Co-Fusion[39]可以使用语义线索分割场景,在这种情况下,系统不是实时的——只有非语义版本
非刚体的表面重建和独立运动刚体的多体公式。在第一种情况下,假设存在一个可变形的世界[12,32,53],并执行尽可能严格的注册,而在第二种情况下,识别刚性对象实例[40,46]和稀疏的跟踪[48,54]或密集型[39]。这两个类别都使用基于模板或描述符的公式[40,46,53],它们需要预先观察感兴趣的对象,以及无模板的方法。在场景的动态部分不受关注的情况下,将它们识别为异常值以避免优化后端出现错误是有价值的。Jaimez et al.[21]和Scona et al.[41]提出了静态融合动态区域的显式检测方法。
表1概述了相关的实时功能方法,并在五个重要属性下对它们进行了比较。
据我们所知,只有两个动态SLAM系统以前尝试过合并语义知识,但都没有达到MaskFusion的功能。Co-Fusion [39]具有基于语义标签对目标进行跟踪、分割和重构的能力,但整体系统的实时性较差,功能有限。DynSLAM [3]为自主驾驶应用开发了一个建图系统,能够分别重构静态环境和移动车辆。然而,整个系统并不是实时的(这就是为什么它没有出现在表1中的原因)而且车辆是它重建的唯一动态对象类,所以它的功能仅限于道路场景。
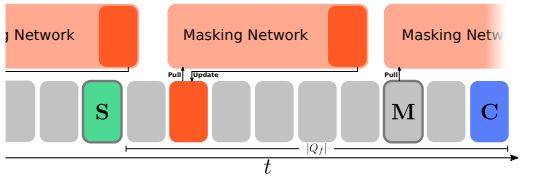
(a)异步组件的定时:在这个时间轴中,帧S和帧M用厚边框突出显示,因为SLAM和mask线程分别在它们上面工作。C,当前帧(队列Qf的尾部)为蓝色,队列的头部为绿色阴影,带有可用对象掩码的帧标记为橙色。
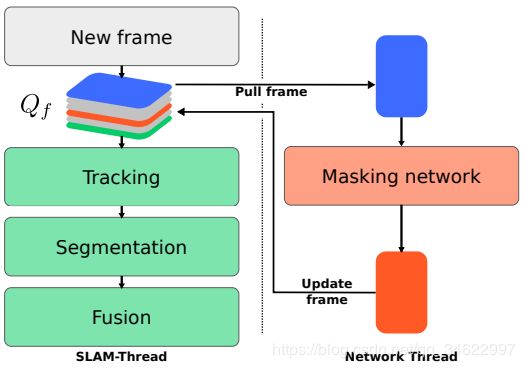
(b) MaskFusion中的数据流:相机帧被添加到一个固定长度的队列Qf中。SLAM系统(绿色)在它的前端运行。语义掩码DNN从尾部提取输入帧,并在结果(语义掩码)可用时将帧更新回队列。
图2: SLAM后端和掩码网络及其交互的高级概述
3. 系统综述
MaskFusion支持实时密集动态RGBD在对象级别进行SLAM。从本质上说,MaskFusion是一个多模型SLAM系统,它为它在场景中识别的每个对象(除了背景模型)保持一个3D表示。每个模型都是独立跟踪和融合的。图2说明了它的帧到帧操作。每次相机获取新的帧时,执行以下步骤:
Tracking: 每个物体的三维几何图形都表示为一组面元。每个模型的六自由度姿态跟踪通过最小化能量结合几何迭代最近点(ICP)错误对应点之间的光度成本基于亮度恒定在当前帧和存储的3 d模型,与前一帧的姿态对对齐。为了降低计算需求,提高鲁棒性,只对非静态对象进行单独跟踪。测试了两种不同的策略来决定一个物体是否是静态的:一种基于运动的不一致性,类似于[39],另一种将被人触摸的物体视为动态的。
Segmentation: MaskFusion结合了两种用于分割的线索:语义线索和几何线索。Mask- RCNN [15]用于提供带有语义标签的对象掩码。虽然这种算法令人印象深刻,并提供了良好的对象掩码,但它有两个缺点。首先,该算法不能实时运行,最多只能在最大5HZ下运行。其次,对象边界并不完美——它们往往会渗透进来背景。为了克服这两个限制,我们运行了基于深度不连续和表面法线分析的几何分割算法。与语义实例分割相比,几何分割是实时运行的,可以产生非常精确的对象边界(见图3(d)和(e)几何边缘图和算法返回的几何组件的可视化示例)。(On the negative side) 消极的一面是,基于几何图形的分割往往会过度分割对象。这两个分割策略的组合——对每一帧进行几何分割并且尽可能的进行语义分割-提供最好的两个世界,让我们(1)实时运行整个系统(几何分割用于没有语义对象掩码的帧,而两者的结合用于拥有对象掩码的帧)和(2)获得语义对象掩码改善由于几何分割的对象边界。
Fusion:通过利用对象标签将面元与正确的模型相关联,每个对象的几何形状会随着时间的推移而融合。我们的融合遵循与[23,50]相同的策略。
论文的其余部分组织如下。在第4节中,我们首先描述了动态RGBD-SLAM方法的原理;关于语义和几何分割结果的集成的进一步细节在第5节中提供。第6节对本文提出的方法进行了定性和定量的评估。
4. MULTI-OBJECT SLAM

(注:由于特殊的数学符号公式,翻译编辑比较麻烦,所以进行了原文图片浮现)
4.1 Tracking

(注:由于特殊的数学符号公式,翻译编辑比较麻烦,所以进行了原文图片浮现)
校准对齐是通过最小化联合几何和光度误差函数来实现的[39,50]:


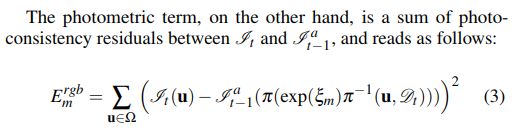
在这里,π执行一个透视投影π:![]() ,而
,而![]() 是2D坐标深度图的一个反向投射。为了优化这个非线性最小二乘代价,我们使用了一个四层粗到精细的金字塔结构的高斯牛顿求解器。CUDA加速了解决程序的实现,它基于[50]和[39]的开放源代码的发行版本。
是2D坐标深度图的一个反向投射。为了优化这个非线性最小二乘代价,我们使用了一个四层粗到精细的金字塔结构的高斯牛顿求解器。CUDA加速了解决程序的实现,它基于[50]和[39]的开放源代码的发行版本。
4.2 Fusion
给出![]() 和
和![]() , 通过与当前RGBD帧执行投影数据关联,更新每个模型
, 通过与当前RGBD帧执行投影数据关联,更新每个模型![]() 的surfels。这一步的灵感来自于[23],但是基于第5节中讨论的分割的模板化被用于遵守对象边界。因此,每个新创建的surfel都是一个模型的一部分。此外,我们还引入了一个对模板外的面元的置信度惩罚,这是由于不完全分割所需要的。
的surfels。这一步的灵感来自于[23],但是基于第5节中讨论的分割的模板化被用于遵守对象边界。因此,每个新创建的surfel都是一个模型的一部分。此外,我们还引入了一个对模板外的面元的置信度惩罚,这是由于不完全分割所需要的。
5. SEGMENTATION
MaskFusion同时重构和跟踪多个对象,维护独立的模型。因此,在执行融合之前,新数据必须与正确的模型相关联。在Co-Fusion[39]的启发下,在建立2D和模型到分割的对应关系之下执行分割代替3D数据关联。由于这些对应关系,新的帧被掩模,只有数据子集与现有模型融合。掩码是基于DNN[15]提出的语义实例分割标签,结合几何分割,提高了目标边界的质量。我们的语义分割管道提供30Hz或更高的掩码。
管道的设计是基于以下的观察:(i)目前的语义分割方法是擅长于目标检测,但是倾向于提供不完美的对象边框. (ii)目前最好的方法,Mask-RCNN[15],不能在帧的速率上执行.(iii)RGBD帧中包含的信息允许图像的快速过分割,例如通过假设对象是凸面.
第二个观察直接表明想要达到一个总体的实时的性能,我们的系统必须执行实例级语义分割在一个tracking和fusion同时并行的线程. 然而,以不同频率同时执行两个程序需要同步策略. 我们缓冲新的帧在一个队列Qf并且将SLAM系统引用到队列的前端, 同时语义分割运行在队列的后面, 如图2a所示. 这个方法的SLAM管道的与你相嗯是被语义分割的worst-case 耗时的处理过程后延了. 我们的实验中,我们挑选一个12帧的队列长度,它包括一个大约400ms的延时.这个延时是否可以被忽略依赖于系统的使用情况.即使一个等待时间是存在的,系统也会运行在一个30fps的帧率. 另外,一个语义分割是不可用的对于大多数帧来说,因为掩码部分的低执行效率,然而,为了融合新的帧,每个帧都需要一个标签数据. 这个问题被解决通过联结仅带有存在模型的掩码缺失的帧,如5.3部分讨论的.



对不精确边界进行补偿,如观察1所提到的,我们从一个集合过分割到语义掩码确定观察3和地图组成. 这一结果提高掩码,由于高品质的集合语义边框.
图3 分割方法的分解 (a)和(b)展示一个RGBD帧的输入,(c)-(g)可视化不同阶段的输出

图4:比较仅仅通过语义标签与通过融合语义和集合标签的边框产生. 然而语义分割是平滑的,缺少重要的细节.
5.1 实例级语义分割
一个多样的[15,27,36]关于最近提出的神经网络结构用来来解决实例级的目标分分割. 他们的表现超出了传统的方法并且可以解决大集合的物体分类. 这些方法中, Mask-RCNN [15]是尤其有说服力的, 因为它提供了在一个5Hz的相对高帧率的超级分割质量. MaskFusion的语义分割通道是基于Mask-RCNN的. 它映射RGB 帧到一个物体掩码集合 … ,边框盒子和分类ID ,对于所有的实例检测在帧的时间t.
Mask-RCNN 通过延伸Faster-RCNN [37]的结构. Faster-RCNN是一个两步的方法,首先提取感兴趣区域然后在每一个区域预测一个物体分类和边框盒子并且以平行的方式. 在第二步骤添加一个第三分支, 不依赖类IDs和边框盒子的情况下生成. 两个步骤依赖一个 特征图,这个特征图通过 基于ResNet[16]的骨干网络, 并且应用卷积层用来推断.
图3c 可视化Mask-RCNN的输出. 注意 : 同一类的实例用不同的颜色突出显示, 并且掩码与对象的边界没有完全对齐.
5.2 几何分割
假定一个物体—尤其一个人为的目标物—是大的凸面的, 建立在凹形区域和深度不连续区域放置边缘的快速分割方法是可能的. 事实上,这个方法更趋于过分割数据, 由于简化的前提. Moosmann et al. [29] 成功的分割3D 传感数据基于这个假设. 同样的原则也用于其他的分割物体在RGBD 帧情况下[13,22,42,45,47].RGBD 帧情况下.我们的几何分割方法依据这个方法并且与[45]相似,生成一个edginess-map基于深度不连续项φd和凹面项φ。具体地说,一个像素被定义为一个边缘像素如果φd +ˆλφc >τ,τ是一个阈值并且ˆλ是一个相关权重。给定一个局部紧邻的N,φd和φc计算如下:
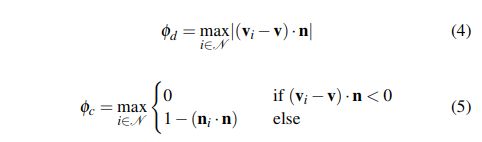

5.3 合并分割
对于SLAM系统处理的每个帧,执行图5所示的管道。虽然几何分割(如左图所示)是针对所有帧执行的,但只有在语义掩码可用时才将几何标签映射到语义掩码。在没有语义掩码的情况下,几何标签直接与现有模型关联,跳过以下步骤:

图5:执行的分割步骤概述。对每一帧执行几何分割,得到的组件映射到掩码(如果可用的话),掩码又映射到现有模型。如果可能,没有映射到掩码的组件直接与对象关联。
5.3.1将几何标签映射到掩码

5.3.2将掩码映射到模型

尚未分配给模型的组件现在被认为是直接分配的。这是必要的,Mask-RCNN可能无法识别对象,而且大多数帧预计不会显示任何掩码。同样,重叠度为65%·|Ci|计算了![]() 中剩余组件和标签之间的关系。
中剩余组件和标签之间的关系。
最终的分割![]() 包含与相关组件关联的模型的对象ids。一个特殊的预定义值2用于指定在融合过程中应该忽略的区域。这对于显式地防止某些对象类的重构特别有用,例如图3g中以白色突出显示的人的手臂。
包含与相关组件关联的模型的对象ids。一个特殊的预定义值2用于指定在融合过程中应该忽略的区域。这对于显式地防止某些对象类的重构特别有用,例如图3g中以白色突出显示的人的手臂。
6 评估
由于MaskFusion的映射和跟踪组件是基于[39,50]的工作,我们专注于解决传统SLAM系统无法解决的具有挑战性的问题的能力,并将更多细节提交给相应的出版物。
6.1 定量结果
6.1.1 轨迹预测
为了客观地将MaskFusion与其他方法进行比较,我们在一个已经建立的RGBD基准数据集[43]上对其性能进行了评估。
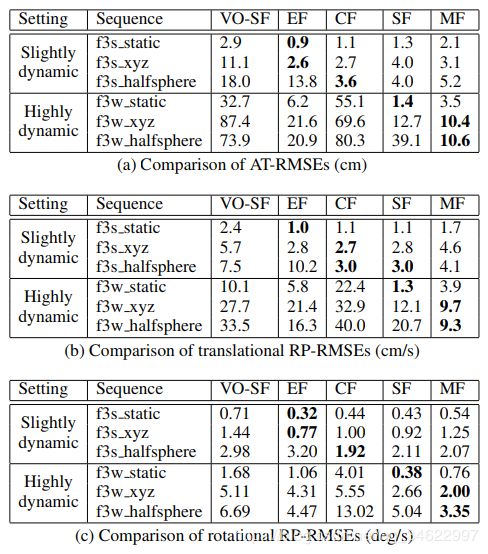
表2:与其他方法的定量比较
这个数据集提供了一系列的彩色和深度帧,并包括地面真实相机的姿态进行比较。通常用于视觉SLAM或视觉里程计分析的测量方法是绝对轨迹误差(ATE)和相对位姿误差(RPE)。当ATE通过叠加地面真值和重建位置的位置偏移量来评估轨迹的整体质量时,RPE考虑了局部运动误差,因此代替了漂移。为了提供独立于场景长度的度量,这两个实体通常表示为均方根误差(RMSE)。
首先,我们在涉及人的快速移动的场景中估计摄像机的运动。由于我们的方法——与我们所比较的方法一样——不能重构可变形的部分,我们利用MaskFusion的上下文知识来忽略与人相关的数据。表2列出了五种方法的AT-RMSE和RP-RMSE测量值,包括MaskFusion (MF):
vof-sf[21]: 一种接近实时的方法,通过计算分段刚性场景流来分割动态对象。
ElasticFusion EF [50]: 一个视觉SLAM系统,它假设一个静态环境。
Co-Fusion (CF) [39]: 一种视觉SLAM系统,通过运动将物体分开。
StaticFusion (SF) [41]: 一种分割和忽略动态部件的三维重建系统。
注意,只有Co-Fusion和MaskFusion系统支持多个对象模型。表2中的序列大致按难度排序,后几行显示出越来越多的动态运动。f3s是freiburg3_sitting的缩写,f3w是freiburg3_walking的缩写。
有趣的是,弹性融合在轻微运动的情况下表现最好,即使它假设是静态场景。我们关于这些的解释其他方法将点标记为动态/离群值,这仍然有利于跟踪,因此表现出较差的性能。
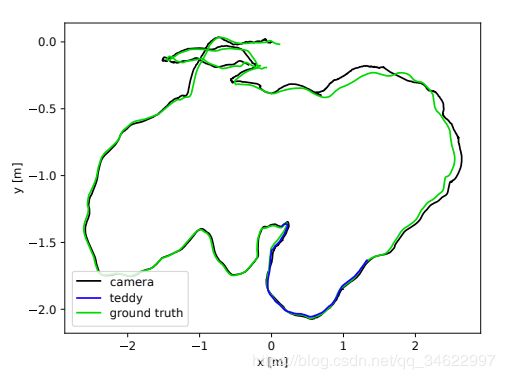
图6:相机和物体轨迹与groundtruth的比较。AT-RMSEs分别为泰迪熊和相机轨迹的2.2cm和8.9cm。由于熊占据了相当大的视场,跟踪它独立影响相机姿态估计的质量。将物体作为背景的一部分将使相机AT-RMSE减少到7.2厘米。
事实证明,在高度动态的场景中,或者在场景开头困难的时候,利用上下文信息特别有用。这些情况很难通过能量最小化来解决,而语义分割的结果是健壮的。
此外,我们重建和跟踪序列f3-long-office的泰迪熊独立于背景运动。这样就可以将估计的目标轨迹与地面真实摄像机轨迹进行比较,如图6所示。熊的轨迹只适用于序列的一部分,因为它在其他情况下是不可见的。
6.1.2 重建
我们利用YCB对象和模型集[4]的对象,对MaskFusion实现的三维重建质量进行了定量评价。YCB集合提供了不同类别的物理日常生活对象,并提供给研究团队,以及一个网格模型和高分辨率的数据库对象的RGB-D扫描。我们从数据集(一个漂白剂瓶)中选择了一个ground truth模型,并获得了一个动态序列来定量评价三维重建中的误差。图9显示了该对象的图像、ground truth 3D模型、我们的重构和热图显示的3D错误的每一个点元。漂白剂瓶平均3D误差为7.0mm,标准差5.8mm (GT瓶高250mm,宽100mm)。

图7:检测人员允许MaskFusion忽略他们。在这个具有挑战性的序列(fr3 walking halfsphere)中,重构只包含静态部分。
6.1.3 分割
为了定量评价分割的质量,我们获得了一个600帧长序列,并为其中一个对象(teddy)泰迪熊的掩码提供了ground truth 2D注解。图8显示了三次不同运行的联合(IoU)的图的交集。仅用MaskRCNN和结合几何分割的MaskRCNN得到的每帧分割掩码的IoU分别用红色和蓝色表示。蓝色曲线表示IoU是用我们的全方法得到的,其中对象掩码是通过重新投影重建的三维模型得到的。这个图显示了如何结合语义和几何线索得到更准确的分割,但通过跟踪和融合在序列上维持时间一致的三维模型,可以取得更好的效果。
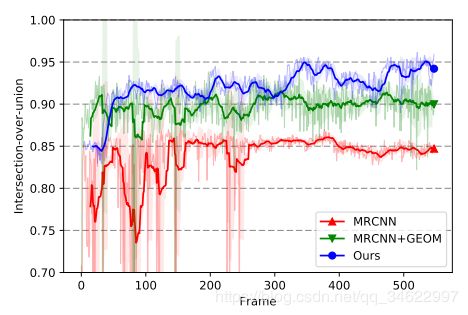
图8:标签性能随时间的比较。结果mask- rcnn (MRCNN)和mask- rcnn(后面是我们的几何分割管道(MRCNN+GEOM))是帧无关的,质量的变化只是由于相机视角的变化。蓝色的图(我们的)显示了相交过并相关的地面真值2D标签与重建的投影3 d模型。
6.2 定性分析结果
我们在各种动态序列上测试了MaskFusion,结果表明,它为不同的用例提供了一个有效的工具箱。
6.2.1 抓取
在机器人技术中,一个常见但具有挑战性的任务是抓取物体。除了需要精密的执行机构,机器人还需要识别正确物体上的抓取点。MaskFusion非常适合提供相关数据,因为它可以密集地检测和重构对象。此外,与大多数其他系统不同,它在交互期间继续跟踪。如果执行器的出现是预先知道的,或者如果一个人与物体相互作用,神经网络可以被训练来排除这些部分的重建。图12显示了框架的时间轴,说明了抓取性能。在这个例子中,前600帧用来检测和建模场景中的5个对象,同时跟踪摄像机。我们实现了一个简单的手控探测器,用来识别什么时候接触到一个物体,当一个物体被触摸时,当人与喷雾器交互时,该物体就会被可靠地跟踪,直到它被放回到桌子上(1100帧时)。
6.2.2 增强现实
Visual SLAM是许多增强现实系统的构建模块,我们相信添加语义信息可以实现新的应用。为了说明MaskFusion可以用于增强现实应用,我们实现了一些演示,这些演示依赖于动态场景中的几何数据和语义数据:
Calories demo 这个原型的目的是根据一个对象的类和形状估计其卡路里。通过估计人体体积,使用简单的原始拟合,并提供一个数据库,以不同类别的单位体积热量比,这是直接增加所需的信息的镜头。基于该原型的实验如图11所示。
Skateboard demo 另一个演示程序展示了一个虚拟角色,它对环境做出积极的反应。滑板一出现在场景中,角色就会跳跃并停留在上面,如图10所示。请注意,即使在有人踢了它并让它动起来之后,这个角色仍然附着在板上。这就要求滑板和相机同时进行准确的跟踪。

图9:从YCB数据集重建漂白剂瓶。重建surfel到ground-truth模型上某一点的平均距离为7.0mm,标准差为5.8mm.

图10:显示与场景交互的虚拟角色的AR应用程序。

图11:AR应用程序,估计食品杂货的卡路里.
6.3 效果
卷积屏蔽组件异步运行到MaskFusion的其余部分,需要专用的GPU。它运行在5Hz,由于长期阻塞GPU, SLAM流水线使用另一个GPU,如果跟踪单个型号,SLAM流水线在>30Hz运行。在存在多个非静态对象的情况下,性能下降,导致3个模型的帧速率为20Hz。我们的测试系统配备了两个Nvidia GTXTitan X和英特尔酷睿i7, 3.5GHz。
7 结论
本文介绍了一种实时可视化SLAM系统MaskFusion,该系统利用语义场景理解来映射和跟踪多个目标。在从二维图像数据中提取语义标签的同时,系统为每个对象实例和背景分别建立了独立的三维模型。我们展示了MaskFusion可以用于实现新的增强现实应用程序或执行常见的机器人任务。
虽然MaskFusion在实现精确、健壮、通用的动态和语义SLAM系统方面取得了有意义的进展,但它在识别、重构和跟踪三个主要问题上存在局限性。在识别方面,MaskFusion只能识别经过MaskRCNN[15]训练的类中的对象(目前MS-COCO数据集的80个类),不考虑对象标签分类错误。其次,虽然MaskFusion可以处理一些非刚性物体的存在,例如人类,但是通过将它们从地图上移除,跟踪和重构仅限于刚性物体。第三,在没有三维模型的情况下,跟踪几何信息较少的小目标会产生误差。解决这些限制为未来的工作提供了机会。
致谢:
这项工作得到了欧盟Horizon 2020研究与创新计划(根据第643950号赠款协议)资助的“二手项目”(SecondHands project)的支持。



图12:评估序列概述。
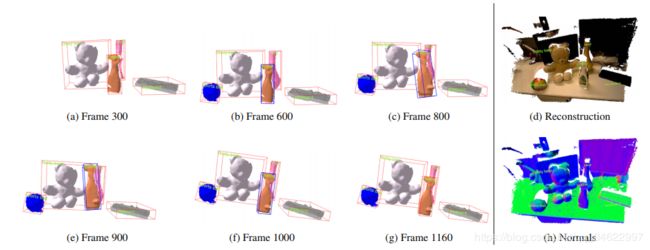
图13:一系列6帧,说明了MaskFusion的识别、跟踪和映射能力。而键盘(灰色),花瓶(粉色)、泰迪熊(白色)、喷雾器(橙色)从一开始就被检测到,球(蓝色)出现在300 - 600帧之间。右边显示重建和估计的法线。喷雾器由一个人在600到1000帧之间移动,但是MaskFusion明确地避免了重构与人相关的几何图形。
注: 下一篇博客我将分享下自己在复现源码,搭建环境的过程中,以如何跑通的过程中遇到的问题,以及解决的办法,欢迎大家批评指正,交流学习。
论文翻译的过程中有不当的地方感谢大家的纠正,欢迎大家帮助完善和提出建议,另外若转载本文请注明出处!