mtcnn论文翻译
MTCNN :使用多任务级联卷积网络进行联合人脸检测和对准
文章目录
- MTCNN :使用多任务级联卷积网络进行联合人脸检测和对准
- 摘要
- I。导言
- II。途径
- A. 总体框架
- B. CNN架构
- C. 训练
- III。实验
- A. 训练数据
- B. 在线硬样本挖掘的有效性
- C. 联合检测和校准的有效性
- D. 面部检测评估
- F. 运行时效率
原论文地址: https://kpzhang93.github.io/MTCNN_face_detection_alignment/paper/spl.pdf
Abstract—Face detection and alignment in unconstrained environment are challenging due to various poses, illuminations and occlusions. Recent studies show that deep learning approaches can achieve impressive performance on these two tasks. In this paper, we propose a deep cascaded multi-task framework which exploits the inherent correlation between detection and alignment to boost up their performance. In particular, our framework leverages a cascaded architecture with three stages of carefully designed deep convolutional networks to predict face and landmark location in a coarse-to-fine manner. In addition, we propose a new online hard sample mining strategy that further improves the performance in practice. Our method achieves superior accuracy over the state-of-the-art techniques on the challenging FDDB and WIDER FACE benchmarks for face detection, and AFLW benchmark for face alignment, while keeps real time performance.
Index Terms—Face detection, face alignment, cascaded convolutional neural network
摘要
由于各种姿势,照明和遮挡,无约束环境中的面部检测和对准具有挑战性。最近的研究表明,深度学习方法可以在这两项任务上取得令人印象深刻在本文中,我们提出了一个深度级联的多任务框架,它利用了检测和对齐之间的内在联系来提高它们的性能。特别是,我们的框架利用级联架构,通过三个阶段精心设计的深度卷积网络,以粗略到精细的方式预测面部和地标位置。此外,我们提出了一种新的在线硬样本挖掘策略,可进一步提高实践中的性能。我们的方法在面部检测的具有挑战性的FDDB和WIDER FACE基准以及面部对齐的AFLW基准测试中实现了超过最先进技术的卓越精度,同时保持了实时性能。
索引术语 - 人脸检测,人脸对齐,级联卷积神经网络
I. INTRODUCTION
I。导言
FACE detection and alignment are essential to many face applications, such as face recognition and facial expression analysis. However, the large visual variations of faces, such as occlusions, large pose variations and extreme lightings, impose great challenges for these tasks in real world applications. The cascade face detector proposed by Viola and Jones [2] utilizes Haar-Like features and AdaBoost to train cascaded classifiers, which achieves good performance with real-time efficiency. However, quite a few works [1, 3, 4] indicate that this kind of detector may degrade significantly in real world applications with larger visual variations of human faces even with more advanced features and classifiers. Besides the cascade structure, [5, 6, 7] introduce deformable part models
脸部检测和对齐对于许多面部应用至关重要,例如面部识别和面部表情分析。 然而,面部大的视觉变化,例如遮挡,大的姿势变化和极端的照明,在现实世界的应用中对这些任务提出了巨大的挑战。 Viola和Jones [2]提出的级联人脸检测器利用Haar-Like特征和AdaBoost训练级联分类器,实现了具有实时效率的良好性能。 然而,相当多的作品[1,3,4]表明,这种探测器可能在现实世界的应用中显着降低,即使具有更高级的特征和分类器,人脸的视觉变化也更大。 除级联结构外,[5,6,7]引入了可变形零件模型
(DPM) for face detection and achieve remarkable performance. However, they are computationally expensive and may usually require expensive annotation in the training stage. Recently, convolutional neural networks (CNNs) achieve remarkable progresses in a variety of computer vision tasks, such as image
classification [9] and face recognition [10]. Inspired by the significant successes of deep learning methods in computer vision tasks, several studies utilize deep CNNs for face detection. Yang et al. [11] train deep convolution neural networks for facial attribute recognition to obtain high response in face regions which further yield candidate windows of faces. However, due to its complex CNN structure, this approach is time costly in practice. Li et al. [19] use cascaded CNNs for face detection, but it requires bounding box calibration from face detection with extra computational expense and ignores the inherent correlation between facial landmarks localization and bounding box regression.
(DPM)用于人脸检测并实现卓越的性能。然而,它们通常是计算上昂贵的在训练阶段需要昂贵的注释。最近,卷积神经网络(CNNs)取得了显着成就在各种计算机视觉任务中取得进展,例如图像分类[9]和人脸识别[10]。灵感来自于计算机深度学习方法的重大成功。在视觉任务中,一些研究利用深度CNN进行人脸检测。杨等人。 [11]训练深度卷积神经网络用于面部属性识别以获得面部的高响应,进一步产生面部候选窗口的区域。然而,由于其复杂的CNN结构,这种方法是在实践中耗费时间。李等人。 [19]使用级联CNN面部检测,但它需要边界框校准面部检测具有额外的计算费用而忽略面部地标定位之间的内在联系和边界框回归。
Face alignment also attracts extensive research interests. Researches in this area can be roughly divided into two categories, regression-based methods [12, 13, 16] and template fitting approaches [14, 15, 7]. Recently, Zhang et al. [22] proposed to use facial attribute recognition as an auxiliary task to enhance face alignment performance using deep convolutional neural network.
面部对齐也吸引了广泛的研究兴趣。 该领域的研究大致可分为两类,基于回归的方法[12,13,16]和模板拟合方法[14,15,7]。 最近,张等人。 [22]提出使用面部属性识别作为辅助任务来使用深度卷积神经网络来增强面部对齐性能。
However, most of previous face detection and face alignment methods ignore the inherent correlation between these two tasks. Though several existing works attempt to jointly solve them, there are still limitations in these works. For example, Chen et al. [18] jointly conduct alignment and detection with random forest using features of pixel value difference. But, these handcraft features limit its performance a lot. Zhang et al. [20] use multi-task CNN to improve the accuracy of multi-view face detection, but the detection recall is limited by the initial detection window produced by a weak face detector.
然而,大多数先前的面部检测和面部对齐方法忽略了这两个任务之间的固有相关性。 虽然现有的一些作品试图共同解决它们,但这些作品仍然存在局限性。 例如,陈等人。 [18]利用像素值差异特征,与随机森林联合进行对齐和检测。 但是,这些手工艺功能限制了它的性能。 张等人。 [20]使用多任务CNN来提高多视图面部检测的准确性,但是检测重新调用受到弱面部检测器产生的初始检测窗口的限制。
On the other hand, mining hard samples in training is critical to strengthen the power of detector. However, traditional hard sample mining usually performs in an offline manner, which significantly increases the manual operations. It is desirable to design an online hard sample mining method for face detection, which is adaptive to the current training status automatically.
另一方面,在训练中采集硬样品对于增强探测器的功率至关重要。 然而,传统的硬样本挖掘通常以离线方式执行,这显着增加了手动操作。 期望设计一种用于面部检测的在线硬样本挖掘方法,其自动适应当前训练状态。
In this paper, we propose a new framework to integrate these two tasks using unified cascaded CNNs by multi-task learning. The proposed CNNs consist of three stages. In the first stage, it produces candidate windows quickly through a shallow CNN. Then, it refines the windows by rejecting a large number of non-faces windows through a more complex CNN. Finally, it uses a more powerful CNN to refine the result again and output five facial landmarks positions. Thanks to this multi-task learning framework, the performance of the algorithm can be notably improved. The codes have been released in the project page1. The major contributions of this paper are summarized as follows: (1) We propose a new cascaded CNNs based framework for joint face detection and alignment, and carefully design lightweight CNN architecture for real time performance. (2) We propose an effective method to conduct online hard sample mining to improve the performance. (3) Extensive experiments are conducted on challenging benchmarks, to show significant performance improvement of the proposed approach compared to the state-of-the-art techniques in both face detection and face alignment tasks.
在本文中,我们提出了一个新的框架,通过多任务学习使用统一的级联CNN来集成这两个任务。拟议的CNN包括三个阶段。
第一阶段:通过浅CNN快速生成候选窗口。
第二阶段:通过更复杂的CNN拒绝大量非面部窗口来细化窗口。
第三阶段:使用更强大的CNN再次细化结果并输出五个面部标志位置。
由于这个多任务学习框架,算法的性能可以显着提高。代码已在项目页面1中发布。
本文的主要贡献概括如下:
(1)我们提出了一种新的级联CNN框架,用于联合人脸检测和对齐,并精心设计轻量级CNN架构以实现实时性能。
(2)我们提出了一种有效的方法来进行在线硬样本挖掘,以提高性能。
(3)在具有挑战性的基准测试中进行了大量实验,与人脸检测和面部对齐任务中的最新技术相比,显示出所提方法的显着性能改进
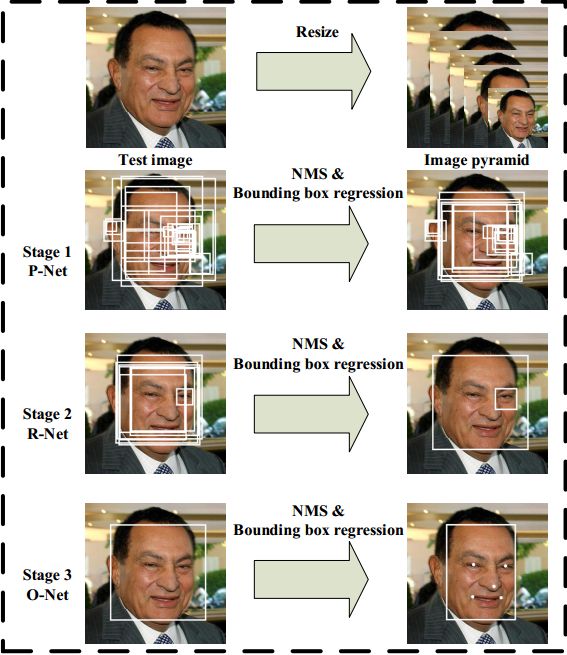
Fig. 1. Pipeline of our cascaded framework that includes three-stage multi-task deep convolutional networks. Firstly, candidate windows are produced through a fast Proposal Network (P-Net). After that, we refine these candidates in the next stage through a Refinement Network (R-Net). In the third stage, The Output Network (O-Net) produces final bounding box and facial landmarks position.
图1.我们的级联框架的流水线,包括三级多任务深度卷积网络。 首先,候选窗口是通过快速提案网络(P-Net)生成的。 之后,我们通过精炼网络(R-Net)在下一阶段完善这些候选人。 在第三阶段,输出网络(O-Net)产生最终边界框和面部地标位置。
II. APPROACH
II。途径
In this section, we will describe our approach towards joint face detection and alignment.
在本节中,我们将介绍我们的方法来联合人脸检测和对齐。
A. Overall Framework
A. 总体框架
The overall pipeline of our approach is shown in Fig. 1. Given an image, we initially resize it to different scales to build an image pyramid, which is the input of the following three-stage cascaded framework:
我们的方法的总体流程如图1所示。给定一个图像,我们最初将其调整到不同的比例以构建图像金字塔,这是以下三级级联框架的输入:
Stage 1: We exploit a fully convolutional network, called Proposal Network (P-Net), to obtain the candidate facial windows and their bounding box regression vectors. Then candidates are calibrated based on the estimated bounding box regression vectors. After that, we employ non-maximum suppression (NMS) to merge highly overlapped candidates.
阶段1:我们利用称为Proposal Network(P-Net)的完全卷积网络来获得候选面部窗口及其边界框回归向量。 然后基于估计的边界框回归向量校准候选者。 之后,我们采用非最大抑制(NMS)来合并高度重叠的候选者。
TABLE I
表I
COMPARISON OF SPEED AND VALIDATION ACCURACY OF OUR CNNS AND
我们CNNS和CNNS的速度和验证准确性的比较
Stage 2: All candidates are fed to another CNN, called Refine Network (R-Net), which further rejects a large number of false candidates, performs calibration with bounding box regression, and conducts NMS.
阶段2:所有候选人都被送到另一个CNN,称为精炼网络(R-Net),它进一步拒绝大量错误候选者,使用边界框回归执行校准,并进行NMS。
Stage 3: This stage is similar to the second stage, but in this stage we aim to identify face regions with more supervision. In particular, the network will output five facial landmarks’ po itions.
阶段3:这个阶段类似于第二阶段,但在这个阶段,我们的目标是识别更多监督的面部区域。 特别是,该网络将输出五个面部地标的点。
B. CNN Architectures
B. CNN架构
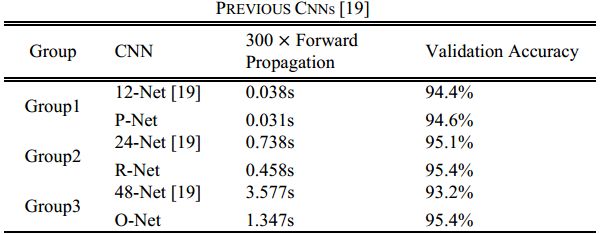
In [19], multiple CNNs have been designed for face detection. However, we notice its performance might be limited by the following facts: (1) Some filters in convolution layers lack diversity that may limit their discriminative ability. (2) Compared to other multi-class objection detection and classification tasks, face detection is a challenging binary classification task, so it may need less numbers of filters per layer. To this end, we reduce the number of filters and change the 5×5 filter to 3×3 filter to reduce the computing while increase the depth to get better performance. With these improvements, compared to the previous architecture in [19], we can get better performance with less runtime (the results in training phase are shown in Table I. For fair comparison, we use the same training and validation data in each group). Our CNN architectures are shown in Fig. 2. We apply PReLU [30] as nonlinearity activation function after the convolution and fully connection layers (except output layers).
在[19]中,已经设计了多个用于面部检测的CNN。但是,我们注意到它的性能可能受到以下事实的限制:
(1)卷积层中的某些滤波器缺乏可能限制其辨别能力的多样性。
(2)与其他多类异议检测和分类任务相比,人脸检测是一项具有挑战性的二元分类任务,因此每层可能需要的滤波器数量较少。
为此,我们减少滤波器的数量并将5×5滤波器更改为3×3滤波器以减少计算,同时增加深度以获得更好的性能。通过这些改进,与[19]中的先前架构相比,我们可以以更少的运行时间获得更好的性能(训练阶段的结果显示在表I中。为了公平比较,我们在每个组中使用相同的训练和验证数据) 。我们的CNN架构如图2所示。我们将PReLU [30]应用为卷积和完全连接层(输出层除外)之后的非线性激活函数。
C. Training
C. 训练
We leverage three tasks to train our CNN detectors: face/non-face classification, bounding box regression, and facial landmark localization.
我们利用三项任务来训练我们的CNN探测器:
- 面部/非面部分类
- 边界框回归
- 面部地标定位。
- Face classification: The learning objective is formulated as a two-class classification problem. For each sample x i x_i xi we use the cross-entropy loss:
1)面部分类:学习目标被制定为两类分类问题。 对于每个样本 x i x_i xi,我们使用交叉熵损失:
公式(1)
L i d e t = − ( y i d e t log ( p i ) + ( 1 − y i d e t ) ( 1 − log ( p i ) ) ) L_i^{det}=-(y_i^{det}\log(p_i)+(1-y_i^{det})(1-\log(p_i))) Lidet=−(yidetlog(pi)+(1−yidet)(1−log(pi)))
where p_i is the probability produced by the network that indicates sample x i x_i xibeing a face. The notation y i d e t ∈ { 0 , 1 } y_i^{det} \in \{0,1\} yidet∈{0,1} denotes the ground-truth label
其中$p_i 是 网 络 产 生 的 概 率 , 表 明 样 本 是网络产生的概率,表明样本 是网络产生的概率,表明样本x_i$是一个面。 符号 y i d e t ∈ { 0 , 1 } y_i^{det} \in \{0,1\} yidet∈{0,1} 表示地面实况标签
- Bounding box regression: For each candidate window, we predict the offset between it and the nearest ground truth (i.e., the bounding boxes’ left, top, height, and width). The learning objective is formulated as a regression problem, and we employ the Euclidean loss for each sample :
2)边界框回归:对于每个候选窗口,我们预测它与最近的地面实况之间的偏移(即边界框的左边,顶部,高度和宽度)。 学习目标被制定为回归问题,我们对每个样本使用欧几里德损失 x i x_i xi:
公式(2)
L i b o x = ∣ ∣ y ^ i b o x − y i b o x ∣ ∣ 2 2 L_i^{box}=||\hat{y}_i^{box}-y_i^{box}||^2_2 Libox=∣∣y^ibox−yibox∣∣22
where y is the regression target obtained from the network and y is the ground-truth coordinate. There are four coordinates, including left top, height and width, and thus y
其中** y ^ i b o x \hat{y}_i^{box} y^ibox是从网络获得的回归目标, y i b o x y_i^{box} yibox是地面实况坐标。 有四个坐标,包括左上角,高度和宽度,因此 y i b o x ∈ R 4 y_i^{box} \in \mathbb{R}^4 yibox∈R4**
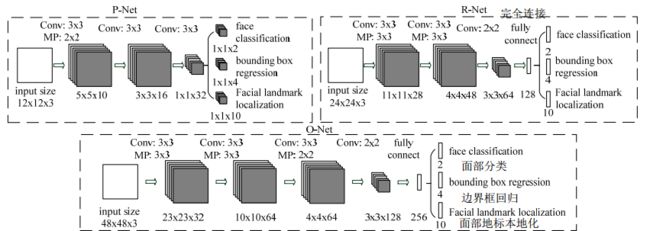
Fig. 2. The architectures of P-Net, R-Net, and O-Net, where “MP” means max pooling and “Conv” means convolution. The step size in convolution and pooling is 1 and 2, respectively
图2. P-Net,R-Net和O-Net的体系结构,其中“MP”表示最大池化,“Conv”表示卷积。 卷积和池化中的步长分别为1和2
- Facial landmark localization: Similar to bounding box regression task, facial landmark detection is formulated as a regression problem and we minimize the Euclidean loss:
3)面部地标定位:类似于边界框回归任务,面部地标检测被公式化为回归问题,我们最小化欧几里德损失:
公式(3):
L i l a n d m a r k = ∣ ∣ y ^ i l a n d m a r k − y i l a n d m a r k ∣ ∣ 2 2 L_i^{landmark}=||\hat{y}_i^{landmark}-y_i^{landmark}||^2_2 Lilandmark=∣∣y^ilandmark−yilandmark∣∣22
where y ^ i l a n d m a r k \hat{y}_i^{landmark} y^ilandmark is the facial landmark’s coordinates obtained from the network and y i l a n d m a r k y_i^{landmark} yilandmark is the ground-truth coordinate for the i th sample. There are five facial landmarks, including left eye, right eye, nose, left mouth corner, and right mouth corner, and thus y i l a n d m a r k ∈ R 1 0 y_i^{landmark} \in \mathbb{R}^10 yilandmark∈R10
其中 y ^ i l a n d m a r k \hat{y}_i^{landmark} y^ilandmark 是从网络获得的面部地标坐标, y i l a n d m a r k y_i^{landmark} yilandmark 是第i个样本的地面实况坐标。 有五个面部标志,包括左眼,右眼,鼻子,左嘴角和右嘴角,因此 y i l a n d m a r k ∈ R 1 0 y_i^{landmark} \in \mathbb{R}^10 yilandmark∈R10
- Multi-source training: Since we employ different tasks in each CNN, there are different types of training images in the learning process, such as face, non-face, and partially aligned face. In this case, some of the loss functions (i.e., Eq. (1)-(3)) are not used. For example, for the sample of background region, we only compute L i d e t L_i{det} Lidet , and the other two losses are set as 0. This can be implemented directly with a sample type indicator. Then the overall learning target can be formulated as:
4)多源训练:由于我们在每个CNN中使用不同的任务,因此在学习过程中存在不同类型的训练图像,例如面部,非面部和部分对齐的面部。 在这种情况下,不使用一些损失函数(即,等式(1) - (3))。 例如,对于背景区域的样本,我们仅计算 L i d e t L_i{det} Lidet,而另外两个损失设置为0.这可以直接使用样本类型指示符来实现。 然后整体学习目标可以表述为:
公式(4)
min ∑ i = 1 N ∑ j ∈ { d e t , b o x , l a n d m a r k } α j β i j L i j \min\sum^N_{i=1}\sum_{j\in\{det,box,landmark\}}\alpha_j \beta_i^jL^j_i mini=1∑Nj∈{det,box,landmark}∑αjβijLij
where ܰ is the number of training samples and yyy denotes on the task importance. We use yyy in P-Net and R-Net, while yyy in O-Net for more accurate facial landmarks localization.yyy is the sample type indicator. In this case, it is natural to employ stochastic gradient descent to train these CNNs
其中ܰN是训练样本的数量, a j a_j aj 表示任务重要性。 我们在P-Net和R-Net中使用 ( a d e t = 1 , a b o x = 0.5 , a l a n d m a r k = 0.5 ) (a_{det}=1,a_{box}=0.5,a_{landmark}=0.5) (adet=1,abox=0.5,alandmark=0.5),而在O-Net中使用 ( a d e t = 1 , a b o x = 0.5 , a l a n d m a r k = 1 ) (a_{det}=1,a_{box}=0.5,a_{landmark}=1) (adet=1,abox=0.5,alandmark=1)以获得更准确的面部地标本地化. β i j ∈ { 0 , 1 } \beta_i^j \in\{0,1\} βij∈{0,1}是样本类型指示器。 在这种情况下,采用随机梯度下降来训练这些CNN是很自然的
- Online Hard sample mining: Different from conducting traditional hard sample mining after original classifier had been trained, we conduct online hard sample mining in face/non-face classification task which is adaptive to the training process.
5)在线硬样本挖掘:与原始分类器训练后进行传统硬样本挖掘不同,我们在面部/非面部分类任务中进行在线硬样本挖掘,适应训练过程。
In particular, in each mini-batch, we sort the losses computed in the forward propagation from all samples and select the top 70% of them as hard samples. Then we only compute the gradients from these hard samples in the backward propagation. That means we ignore the easy samples that are less helpful to strengthen the detector during training. Experiments show that this strategy yields better performance without manual sample selection. Its effectiveness is demonstrated in Section III.
特别是,在每个小批量中,我们对来自所有样本的前向传播中计算的损失进行排序,并选择其中前70%作为硬样本。 然后我们只计算后向传播中这些硬样本的梯度。 这意味着我们忽略了在训练期间不太有助于加强探测器的简单样本。 实验表明,该策略无需手动选择样本即可获得更好的性能。 其有效性在第III节中得到证实。
III. EXPERIMENTS
III。实验
In this section, we first evaluate the effectiveness of the proposed hard sample mining strategy. Then we compare our face detector and alignment against the state-of-the-art methods in Face Detection Data Set and Benchmark (FDDB) [25], WIDER FACE [24], and Annotated Facial Landmarks in the Wild (AFLW) benchmark [8]. FDDB dataset contains the annotations for 5,171 faces in a set of 2,845 images. WIDER FACE dataset consists of 393,703 labeled face bounding boxes in 32,203 images where 50% of them for testing (divided into three subsets according to the difficulty of images), 40% for training and the remaining for validation. AFLW contains the facial landmarks annotations for 24,386 faces and we use the same test subset as [22]. Finally, we evaluate the computational efficiency of our face detector.
在本节中,我们首先评估拟议的硬样本挖掘策略的有效性。 然后我们将人脸检测器和人脸检测与人脸检测数据集和基准测试(FDDB)[25],WIDER FACE [24]和Annotated Facial Landmarks in the Wild(AFLW)基准[最新方法]进行比较[8]。 FDDB数据集包含一组2,845个图像中5,171个面的注释。 WIDER FACE数据集由32,33个图像中的393,703个标记的面部边界框组成,其中50%用于测试(根据图像的难度分为三个子集),40%用于训练,剩余用于验证。 AFLW包含24,386个面部的面部标志注释,我们使用与[22]相同的测试子集。 最后,我们评估人脸检测器的计算效率。
A. Training Data
A. 训练数据
Since we jointly perform face detection and alignment, here we use four different kinds of data annotation in our training process: (i) Negatives: Regions whose the Intersection-over-Union (IoU) ratio are less than 0.3 to any ground-truth faces; (ii) Positives: IoU above 0.65 to a ground truth face; (iii) Part faces: IoU between 0.4 and 0.65 to a ground truth face; and (iv) Landmark faces: faces labeled 5 landmarks’ positions. There is an unclear gap between part faces and negatives, and there are variances among different face annotations. So, we choose IoU gap between 0.3 to 0.4. Negatives and positives are used for face classification tasks, positives and part faces are used for bounding box regression, and landmark faces are used for facial landmark localization. Total training data are composed of 3:1:1:2 (negatives/ positives/ part face/ landmark face) data. The training data collection for each network is described as follows:
由于我们联合进行人脸检测和对齐,这里我们在训练过程中使用了四种不同的数据注释:
(i)否定:对于任何地面真实面,联合交叉(IoU)比率小于0.3的区域;
(ii)积极因素:IoU高于0.65至真实面孔;
(iii)部分面孔:IoU介于0.4和0.65之间的真实面孔;
(iv)地标面孔:标有5个地标位置的面孔。
部分面部和负面部分之间存在不明确的差距,不同的面部注释之间存在差异。 因此,我们选择0.3到0.4之间的IoU差距。 负面和正面用于面部分类任务,正面和部分面用于边界框回归,地标面用于面部标志定位。 总训练数据由3:1:1:2(负数/正数/部分面/地标面)数据组成。 每个网络的培训数据收集描述如下:
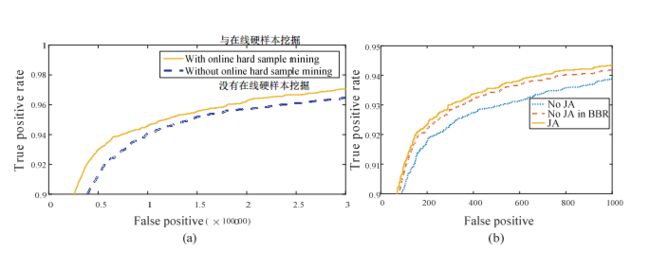
Fig. 3. (a) Detection performance of P-Net with and without online hard sample mining. (b) “JA” denotes joint face alignment learning in O-Net while “No JA” denotes do not joint it. “No JA in BBR” denotes use “No JA” O-Net for bounding box regression.
图3.
(a)有和没有在线硬样本挖掘的P-Net的检测性能。
(b)“JA”表示O-Net中的联合面部对齐学习,而“No JA”表示不联合它。 “BBR中没有JA”表示使用“No JA”O-Net进行边界框回归
- P-Net: We randomly crop several patches from WIDER FACE[24] to collect positives, negatives and part face. Then,we crop faces from CelebA [23] as landmark faces.
(1)P-Net:我们从WIDE FACE[24]中随机裁剪几个补丁,以收集阳性,阴性和部分面部。 然后,我们将CelebA [23]的面孔裁剪为具有里程碑意义的面孔。
- R-Net: We use the first stage of our framework to detect faces from WIDER FACE [24] to collect positives, negatives and part face while landmark faces are detected from CelebA [23].
(2)R-Net:我们使用框架的第一阶段来检测WIDER FACE的面部[24],以收集正面,负面和部分面部,同时从CelebA检测到地标面部[23]。
- O-Net: Similar to R-Net to collect data but we use the first two stages of our framework to detect faces and collect data
(3)O-Net:与R-Net类似,用于收集数据,但我们使用框架的前两个阶段来检测人脸和收集数据
B. The effectiveness of online hard sample mining
B. 在线硬样本挖掘的有效性
To evaluate the contribution of the proposed online hard sample mining strategy, we train two P-Nets (with and without online hard sample mining) and compare their performance on FDDB. Fig. 3 (a) shows the results from two different P-Nets on FDDB. It is clear that the online hard sample mining is beneficial to improve performance. It can bring about 1.5% overall performance improvement on FDDB.
为了评估拟议的在线硬样本挖掘策略的贡献,我们训练两个P-Nets(有和没有在线硬样本挖掘)并比较它们在FDDB上的表现。 图3(a)显示了FDDB上两个不同P-Nets的结果。 很明显,在线硬样本挖掘有利于提高性能。 它可以为FDDB带来约1.5%的整体性能提升。
C. The effectiveness of joint detection and alignment
C. 联合检测和校准的有效性
To evaluate the contribution of joint detection and alignment, we evaluate the performances of two different O-Nets (joint facial landmarks regression learning and do not joint it) on FDDB (with the same P-Net and R-Net). We also compare the performance of bounding box regression in these two O-Nets. Fig. 3 (b) suggests that joint landmark localization task learning help to enhance both face classification and bounding box regression tasks.
为了评估联合检测和对齐的贡献,我们评估了FDDB(具有相同的P-Net和R-Net)的两个不同O-Nets(联合面部标志回归学习并且不联合它)的性能。 我们还比较了这两个O-Nets中边界框回归的性能。 图3(b)表明联合地标定位任务学习有助于增强人脸分类和边界框回归任务。
D. Evaluation on face detection
D. 面部检测评估
To evaluate the performance of our face detection method, we compare our method against the state-of-the art methods [1, 5, 6, 11, 18, 19, 26, 27, 28, 29] in FDDB, and the state-of-the-art methods [1, 24, 11] in WIDER FACE. Fig. 4 (a)-(d) shows that our method consistently outperforms all the compared approaches by a large margin in both the benchmarks.
为了评估我们的人脸检测方法的性能,我们将我们的方法与FDDB中的最先进方法[1,5,6,11,19,26,27,28,29]和国家进行比较。 WIDER FACE中最先进的方法[1,24,11]。 图4(a) - (d)表明,我们的方法在两个基准测试中始终大大优于所有比较方法。
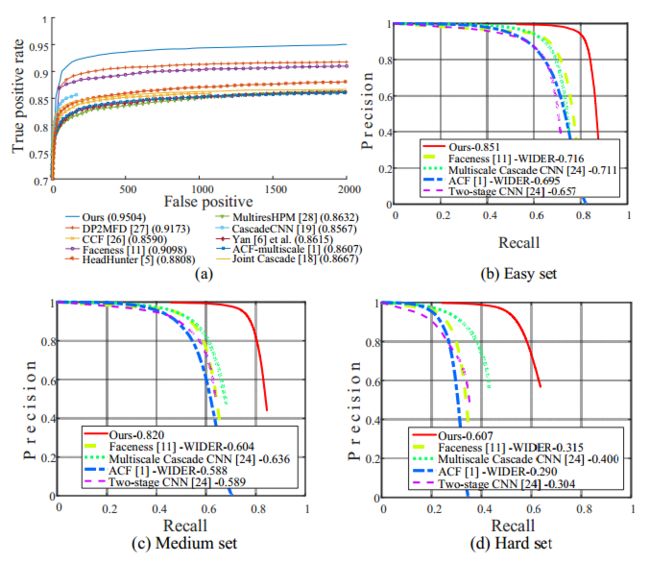
Fig. 4. (a) Evaluation on FDDB. (b-d) Evaluation on three subsets of wider face. The number following the method indicates the average accuracy.
图4.(a)对FDDB的评估。 (b-d)对三个较宽面子集的评估。 方法后面的数字表示平均准确度
E. Evaluation on face alignment
E.面部对齐评估
In this part, we compare the face alignment performance of our method against the following methods: RCPR [12], TSPM [7], Luxand face SDK [17], ESR [13], CDM [15], SDM [21], and TCDCN [22]. The mean error is measured by the distances between the estimated landmarks and the ground truths, and normalized with respect to the inter-ocular distance. Fig. 5 shows that our method outperforms all the state-of-the-art methods with a margin. It also shows that our method shows less superiority in mouth corner localization. It may result from the small variances of expression, which has a significant in fluence in mouth corner position, in our training data
在这一部分中,我们将我们的方法的面部对齐性能与以下方法进行比较:RCPR [12],TSPM [7],Luxand face SDK [17],ESR [13],CDM [15],SDM [21], 和TCDCN [22]。 平均误差通过估计的界标与地面实况之间的距离来测量,并相对于眼间距离进行归一化。 图5显示我们的方法优于所有最先进的方法。 它还表明我们的方法在口角定位方面表现出较低的优势。 这可能是由于我们的训练数据中表达的小变化,其在对角位置具有显着的影响
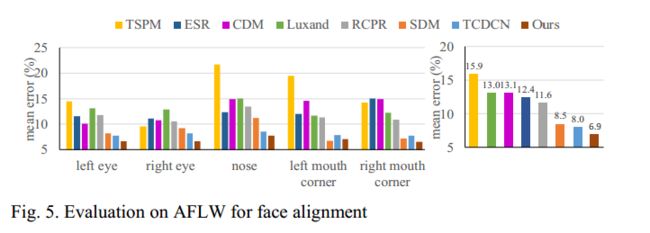
Fig. 5. Evaluation on AFLW for face alignment
图5.面部对齐的AFLW评估
F. Runtime efficiency
F. 运行时效率
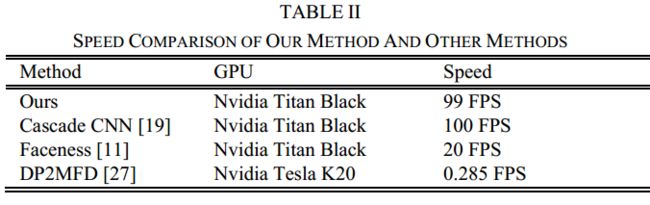
Given the cascade structure, our method can achieve high speed in joint face detection and alignment. We compare our method with the state-of-the-art techniques on GPU and the results are shown in Table II. It is noted that our current implementation is based on un-optimized MATLAB codes.
鉴于级联结构,我们的方法可以实现关节面检测和对准的高速度。 我们将我们的方法与GPU上最先进的技术进行比较,结果如表II所示。 值得注意的是,我们当前的实现基于未优化的MATLAB代码。
表II:
SPEED COMPARISON OF OUR METHOD AND OTHER METHODS
我们的方法和其他方法的速度比较