目标检测简介
文章目录
- 目标检测简介
- 1 引言
- 2 目标检测分类
- 2.1 传统的目标检测算法
- 2.2 基于深度学习的目标检测算法
- 2.2.1 基于two stage的目标检测
- 2.2.2 基于one stage的目标检测
- 3 Faster RCNN目标检测算法及其实现
- 3.1 Faster RCNN算法原理
- 3.2 实验结果与分析
- 4 小结
目标检测简介
1 引言
目标检测与跟踪是从复杂的背景中检测出目标,并进行跟踪预测等,为后续的分析处理提供信息。因此,目标检测与跟踪技术是单摄像机多目标跟踪技术的基础,这个模块的性能将会对后续单摄像机多目标跟踪系统的性能产生巨大的影响。
2 目标检测分类
目标检测是指从复杂的图像(视频)背景中定位出目标,并分离背景,对目标进行分类,找到感兴趣的目标,从而更好地完成后续的跟踪、信息处理与响应等任务。目标检测在很多领域都有应用,比如对于脸部、行车、路人等物体的检测,以及一些交叉领域的应用,比如自动驾驶领域交通标志的识别、工程领域里材质表面的缺陷检测,农作物病害检测和医学图像检测等等,所以对目标检测的研究很有实际价值。
目标检测按照是否将深度学习的思想应用于检测又可以分为传统检测方法和基于深度学习的检测方法。本文以最后一种划分标准来介绍主要的目标检测算法,进行对比分析,并结合现在的研究状况,对目标检测方法的研究作出合理展望。
2.1 传统的目标检测算法
由于深度学习诞生之前缺乏有效的特征表达,而且计算资源匮乏,传统的目标检测算法大多数是基于手工特征所构建的精巧的计算方法,其思路流程如下图2.1所示:
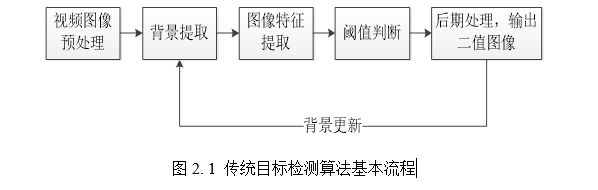
而且传统的目标检测算法众多,不宜一一介绍,但是其主体思路方法大致可以分为几类,主要有帧差法、背景减除法和光流法等,其它许多方法都是由它们衍生而来。
(1) 帧差法
摄像机采集的视频序列具有很强的帧之间的时空联系,即时间上连续的帧的图像区域,如果是目标会呈现明显的变化,否则变化很微弱。帧差法就是基于上述原理发展而来的,具体来说就是对时间上连续的图像帧,然后进行判断。按照选取帧数的区别,帧差法又分为两帧差分法和三帧差分法。
两帧差分法公式如下:
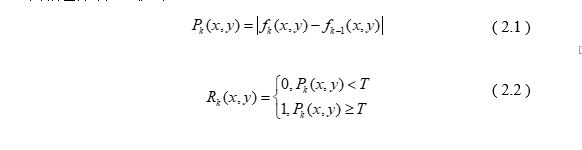
两帧差分法能够能够粗略地分离目标与背景,但是仅适用于目标静止或运动缓慢的情况,而且还存在空洞现象与重影现象。为此,人们在其基础上进一步改进提出了三帧差分法。三帧差分法由于选取三帧图像两两差分处理取逻辑与,能够更好地适应运动较快的目标场景。
三帧差分法公式如下:

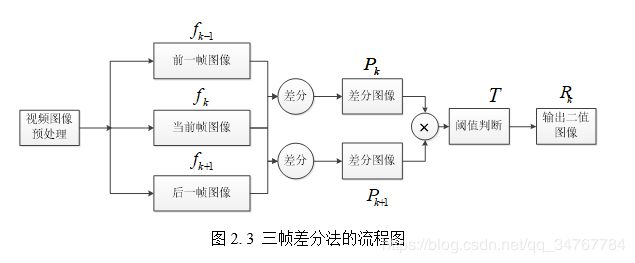
如下图是帧差法的效果图,可以看出,三帧差分法能更好地处理空洞和重影问题。
两帧差分法实现效果图如下:

三帧差分法实现效果图如下:

从上面的论述可以看出,帧间差分法对于光照鲁棒性高,原理简单好实现,但是检测目标不完整,可能存在重影和黑洞现象,所以帧间差分法一般是与其它算法结合使用。
(2) 背景减除法
背景减除法的原理是将当前帧与背景图像差分比较来判别目标与背景。其关键在于建立一个可靠的背景模型,本文选取均值模型基础模型。这个模型首先对视频序列连续N帧同一位置处像素点求均值 ,建立背景模型;将当前帧 与背景模型 进行差分,然后通过阈值比较判断,进一步处理更新,从而将目标于背景区分开来。该过程涉及以下公式:

背景减除法流程如下图2.6:
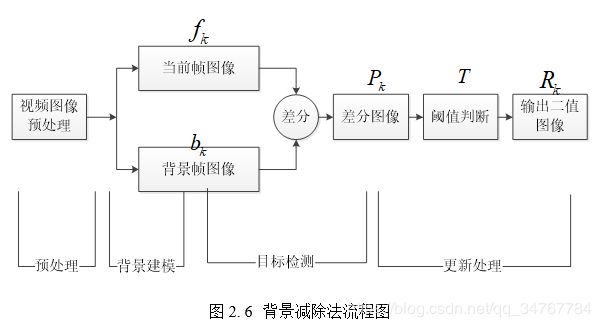
背景减除法效果如下图:

综上所述,背景差值法检测目标速度快,不受运动目标速度的限制,易于实现;但是由于实际应用中可靠的背景模型很难建立,所以应用范围有限。
(3) 光流法
光流简单来说就是运动物体的瞬时运动速度。光流法就是利用很短时间内视频序列中同一位置处连续几帧图像像素之间的瞬时速度保持不变,同时也可转化为瞬时移动距离不变,从而根据上一帧与当前帧这一距离不变关系作计算,预测物体的运动。
基于光流法的目标检测方法就是对采集的图像信息进行初步处理后,根据光流法公式推算出图像中各点的光流场,然后通过阈值判断将目标与背景分离,接着进一步处理,输出二值图像。



用OpenCV在其示例视频剪取片段实现光流法,得到结果如下图2.8:

图中箭头标示了目标物体运动的方向,由图可以看出,光流法能够大致预测标示出物体运动的轨迹,但准确性还有待提高,而且不适合多目标同时检测。
综上所述,光流法能够很好地适应于运动场景中的运动目标检测。光流法前提条件要求过高,适应性有限。
(4) 小结
综上所述,传统目标检测途径主要有帧差法、背景减除法、光流法,三者的比较分析如下表2.1:

总的来说,传统的目标检测算法相对容易实现,提取的特征都是人工选定的很有针对性的直观特征,但不能够很好地进行推广,而深度学习能够很好地弥补这些缺点,所以逐渐占据主导地位。
2.2 基于深度学习的目标检测算法
2012 年,Alex Net取得了ILSVRC竞赛第一名的好成绩,使得深度学习在CV领域大放异彩,之后便有学者尝试应用深度学习来改进传统的目标检测算法。2014年,DeepFace和DeepID的出现,使得深度学习在人脸识别领域大放异彩。2017年,谷歌DeepMind团队推出的AlphaGo与李世石的世纪之战使得深度学习广为人知。近年来,深度学习发展劲头更加猛烈,得到广泛应用。
深度学习相对于传统目标检测算法能够提取更加高层和更好的表达目标的特征,还能将特征的提取、选择和分类集合在一个模型中。
深度学习算法先后出现两种主要类型,即两阶段目标检测算法与单阶段目标检测算法,这依据的是处理流程以及网络架构的设置。其中two stage的目标检测算法分两步进行;而one stage的目标检测算法一步直接对预测的目标物体进行判定识别。下图本文对常见的基于深度学习的目标检测算法进行了分类概括,如下图2.9所示。
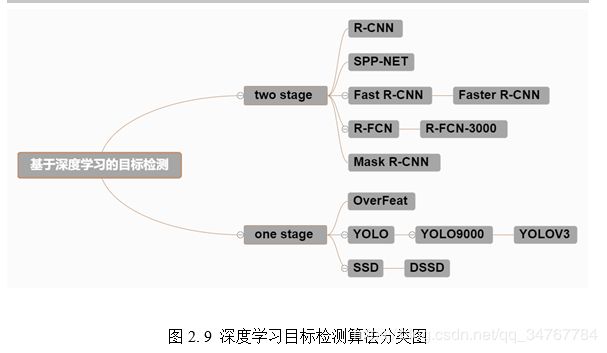
2.2.1 基于two stage的目标检测
基于two stage的目标检测分两步进行目标检测:首先生成可能区域(Region Proposal)并且用卷积神经网络(CNN)提取图像特征;然后放入分类器分类并修正位置。
(1) RCNN算法
Ross Girshick[10]在2014年的CPVR顶会中的论文中提出了RCNN算法,这种方法突破了传统的用滑动窗口进行候选窗口选择的模式,采用选择性搜索来选取候选框,并且一直被后续的two stage算法沿用。
实验表明,RCNN效果较之前的算法有了很大提升,但是RCNN算法仍有许多不足之处:候选区域大量重复造成算法速度缓慢;算法耗费的时空资源相当大等。
(2) SPP-NET
2015年微软研究院的何恺明等[11]提出一种SPP-Net算法一次性对整张图片提取特征。
由于CNN的全连接层要求输入图片的大小一致,所以必须对输入的图片进行归一化处理,之前的算法大多采用不同位置的裁剪,但是该算法采用了SPP进行图像维度归一化,提供特定维度的图像数据给CNN,从而消除了归一化所带来的资源消耗问题,提高了算法速度;但是这种图像处理仍旧会导致图像信息的不完整。
(3) Fast RCNN
2015年Ross Girshick等[12]在对RCNN进行改进下提出了Fast RCNN算法。该算法使用RPN来代替选择性搜索来获取候选框,大大提升了算法效率。
该算法大致可以分为如下几个阶段:
i) 在初始图像中确认候选框,输入整张图片到CNN获取图片的特征层;
ii) 通过RPN网络从图片信息获取候选框以及特征图,然后输入ROI池化层进行尺度归一化;
iii) 利用softmax分类器进行多分类目标识别,并用边界框回归对各个类的候选框进行微调。
Fast RCNN算法将线性分类器SVM替换成softmax进行多分类预测,极大地提升了分类的准确性;将边界框回归与区域分类合并成一个多任务模型,实现了卷积网络的权重共享;使用Rol pooling来保持多尺度的输入,能够直接传播梯度,大大节省了空间。但是仍然是用选择性搜索算法来提取特征,会耗费大量时间,所以还存在着诸多不足。
(4) Faster RCNN
2015年何恺明等人[13]提出了Faster RCNN算法,该算法真正实现了two stage的全网络结构。
该算法大致可以分为以下三个步骤:
i) 对图像信息进行预处理操作并输入网络,利用卷积神经网络得到图片的特征图;
ii) 将卷积特征输入到RPN,获取候选框及其特征图;
iii) 用Softmax网络进行分类,用回归网络进行Bbox回归,然后输出实验结果。
Faster RCNN使用的RPN网络使得候选区域、分类、回归一起共享卷及特征很大程度上提高了算法效率。但是,该算法由于处理繁琐,计算复杂,系统开销较大。
(5) R-FCN
为了解决上述问题,2016年的NIPS顶会中,Jifeng Dai等[14]发表了R-FCN算法,该算法使用全卷积网络(Fully Convolutional Network, FCN)来实现计算共享,大大提高了速度。
该算法大致可以分为三个步骤:
i) 将图片输入到预训练网络,得到RPN网络相应的TOI,图片特征层的用于分类的位置敏感得分图;
ii) 使用RPN来生成候选框;
iii) 利用RPN获得的特征与位置敏感得分图进行分类,遴选候选框,然后分类别进行回归微调。
FCN应用于Faster RCNN使得整个网络的计算共享,使得R-FCN检测速度比Fast RCNN提高了2.5-20倍;同时该算法提出了位置敏感得分来平衡平移不变性(translation-invariance)和平移可变性(translation-variance)之间的矛盾。但是该算法只是在一个特征尺度上进行,不能够完整地展现目标的特征。
(6) Mask RCNN
一年后,何恺明[15]团队再一次改进Faster RCNN,提出了Mask RCNN,该算法用ROI对齐代替ROI池化,能够很好地聚集图像特征,而且该算法还增加了一个mask层用来候选框识别。
该算法大致可以分为三个步骤:
i) 将图片进行预处理,然后通过预训练好的ResNet网络处理图片信息来获取图片特征图;
ii)生成候选ROI并输入RPN网络进行分类
iii)对处理过的ROI进行ROI Align操作,并进行分类回归。
Mask RCNN的精髓就是设计出了RoI对齐层,以及添加了一个额外的分支来预测分割层来处理候选框,所以是一个多任务的训练过程,这也提高了目标检测的准确率。但是其检测速度仍然达不到实际应用的实时性要求。
综上所述,基于two stage的目标检测算法大多聚焦于分类问题,用RPN(region proposal network)获取候选框,而且大多使用RCNN进行分类确定目标,采用“图片特征CNN生成分类提取特征+分类器分类并进行回归微调”的思路。该类算法由于复杂的结构与候选框的反复遴选使得算法的速度受到很大限制。
2.2.2 基于one stage的目标检测
由于two stage算法的网络结构特点使得其速度存在瓶颈,于是一些研究人员开始转换思路,直接将目标检测转化到回归上,一步完成特征提取、分类回归,判定识别步骤,因此以YOLO为代表的one stage算法逐渐发展起来。
(1) OverFeat算法
OverFeat[16]是最早将深度学习应用于目标检测的算法之一,并在2013获得了ImageNet定位任务的冠军。
搞懂OverFeat算法首先要明白OverFeat就是类似于传统算法中的特征提取算子,该算法大致可以分为以下三个步骤:
i) 利用滑动窗口选择出不同尺度的候选框,并用CNN进行提取特征图;
ii) 将图像信息输入后续处理网络,以便多尺度滑动窗口对候选框筛选和分类;
iii) 利用回归模型预测每个对象的位置并进行边框合并。
该算法第一次系统阐述了CNN是如何应用于定位与检测的,使用了一个CNN来集成处理分类、定位和预测三个任务,功能强大,另外该算法提出了一个多尺度、滑动窗口的方法,而且是通过累积预测来求标记框,相比于传统算法大大提高了效率,但错误率较高,准确性有待提高。
(2) YOLO(You Only Look Once)算法
为了解决OverFeat等算法面临的困境,2016年Redmon[17]等人提出了YOLO算法。根据其英文全称,可以看出该算法把目标判定和识别结合在一起,即one stage思想,这在很大程度上提升了算法的速度。
YOLO算法大致可以分为三个步骤:
i) 输入预处理好的图片,并将其归一化到固定尺寸;
ii) 将i)处理好的图片输入卷积神经网络运行;
iii) 根据阈值判定,得到目标位置与类别。
这里需要解释一下,输入图片归一化固定尺寸是指将卷积后提取的特征图划分为一个固定为S×S的网格(cell),将检测任务分配到每个独立的网格自主对本网格区域进行分类检测,并输出检测结果及其置信度。
YOLO将判定与检测结合在一起,简化了目标检测流程,使得算法的速度提升很大,但是YOLO还存在对小物体、多目标检测效果不理想;精准度都有待提升等问题。
(3) SSD算法(Single Shot MultiBox Detector)
YOLO发布同年之后一段时间,Wei Liu[18]等提出了SSD算法改进了YOLO检测精度不足的问题。该算法在YOLO的基础上借鉴了Faster RCNN中RPN的思路,兼顾了检测速度和精度。
SSD算法创造性地引入了RPN的思想,使得one stage算法的准确度得到很大提升;而且引入了多尺度(scale)预测的思想,更好地体现了目标的特性;设置了先验框,增加了检验的准确性。
综上所述,two stage的深度学习目标检测主要倾向准确性,one stage的目标检测主要倾向于速度,两者侧重点不同。前者的方法和后者方法两者相互借鉴,不断融合,取得了很好的效果。尽管深度学习的应用极大提升了目标检测算法的效果,但是仍旧存在一些问题:如深度学习需要大量的数据以及强大的计算与硬件资源,无法对小目标做出准确检测等。
3 Faster RCNN目标检测算法及其实现
如前文所述,Faster RCNN目标检测算法是RCNN系列的最为先进的一种算法,正处于深度学习目标检测算法从two stage到one stage转换的临界阶段。
3.1 Faster RCNN算法原理
Faster RCNN使用RPN来代替选择性搜索来获取特征图,并将其与Fast RCNN网络结合到一起,其具体的流程如下图所示:
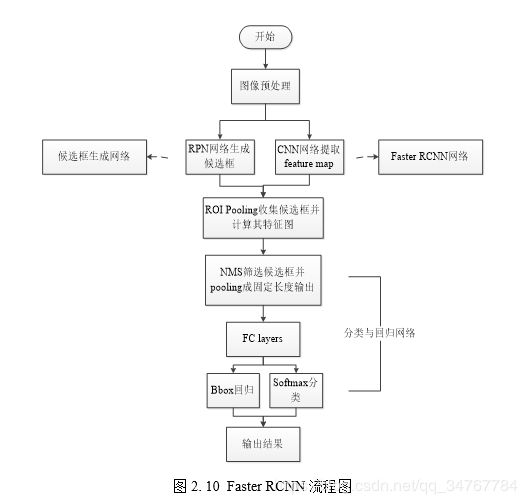
为了更深层次地理解Faster RCNN算法,下面结合其流程图对其网络结构进行进一步的探究。
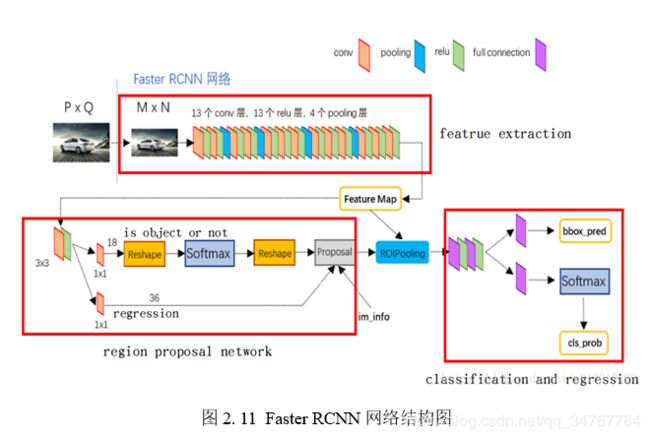
如图2.11所示,预处理的图像信息输送给一个卷积神经网络来提取特征图,这个CNN由1个input layer(输入层),13个conv(卷积层),13个激活函数RELU,13个pooling(池化层)组成。然后将提取的特征图一方面送给候选框提取网络,一方面送给ROI池化层。候选框提取网络先是将由特征提取网络获取的特征图进行处理分流,这个功能由33的卷积层与全连接层组成;然后分流的信息流分别经过一个11的卷积层流进候选框获取网络与候选框回归网络;在候选框获取网络中图片信息先是被重塑为固定大小尺寸,然后经过Softmax网络进行分类,然后在被重塑为特定大小尺寸,然后提交候选框。而流入候选框回归网络的图片信息直接作用于候选框,用于校正。然后选出的候选框以及图片信息流以及特征图信息一起输入ROI池化层,对候选框进行非极大值抑制筛选,并将其池化为固定尺度输出。然后图片信息流流入一个RELU激活函数与全连接层混合的网络进行处理,然后分流,分别经过一个全连接层后,一个进行Bbox回归,对输出的图像框进行修正;另一个经过Softmax进行分类,获取检测物体的类别与置信度信息。然后输出结果,即在输出图像中标出图相框,物体类别与置信度信息。
3.2 实验结果与分析
实验采用自己拍的照片作为实验对象,使用最为常用的评价算法精确度与速度的指标。
Faster RCNN检测算法效果如下所示:

由图2.12中可以看出,Faster RCNN检测效果很好,标记框很好地标出物体的范围,而且能够检测出图片中各类物体给出物体标签并给出置信度分数,可以看出,在成功识别物体类别的情况下越是明显的物体置信度分数越高(如图中的大象、熊猫、鸟,露出耳朵以及身体的人),而相对来说露出一部分形体却特征不明显的物体置信度不高(如图中只露出头发的人以及部分身躯的鸟)。
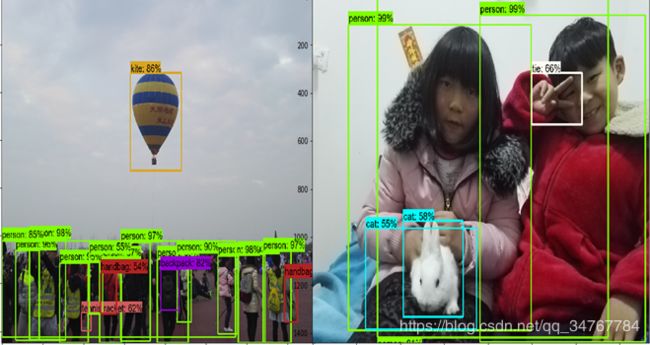
由图2.13可以看出Faster RCNN算法也存在不足,如图中将热气球误判为kite,将兔子和花棉裤误判为cat,将比V的手指误判为tie。
将Faster RCNN系列算法进行性能指标的对比如下表所示:
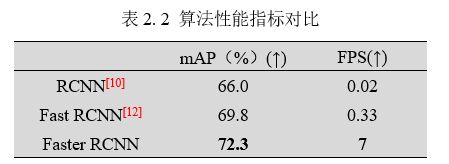
其中mAP代表均值平均精度,FPS代表在单位时间(1秒)内识别的帧数。其中mAP的计算公式如下:
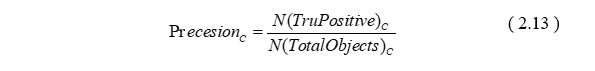

根据单类别物体在单张图上的精度定义,经测试数据集上所有该类物体精度加权平均即可得到均值平均精度mAP。
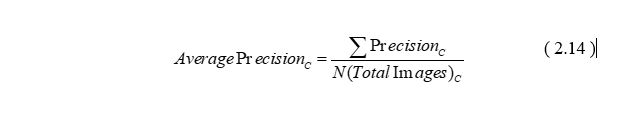
Faster RCNN算法较其之前的RCNN系列算法有了很大的提升,但是其缓慢的速度导致其无法应用于实时性实践活动中;在其之后提出的以YOLO为代表的one stage算法明显性能更为优越,特别是速度得到了很大提升。
4 小结
传统的目标检测算法多是人工提取的图像特征,后来深度学习的引入使得卷积网络提取的图像特征更具有代表性,所以目标检测效果获得了巨大提升,但是目标检测仍然面临着诸多困难,如光照变化影响、遮挡、阴影、背景扰动等。同时人们不断追求目标检测算法的精确性、速度与普适性,具体的目标有优良的模板、高效的算法、较好的特征表达等。传统的目标检测算法较为简单、实现起来较为容易,但是精准度不够;深度学习的检测算法难以实现,但是较为准确。由此可以看出目标检测朝着多维度信息融合,基于深度学习的特征表达,多种方法交叉融合的方向前进。
Faster RCNN目标检测算法检测效果很好,标记框很好地标出物体的范围,而且能够检测出图片中各类物体给出物体标签并给出置信度分数,相较于其系列之前的算法在精确度和速度上都有了很大改观。