elk+kafka日志收集
依赖
org.springframework.boot
spring-boot-starter-data-elasticsearch
Dao层

启动类加上Elasticsearch的注解:@EnableElasticsearchRepositories

实体类

Elasticsear的基本操作语句(更多请查看官方文档):
GET _search
{
"query": {
"match_all": {}
}
}
###创建索引
PUT /mytest
####查询索引
GET /mytest
####添加文档 /索引名称/类型/id
PUT /mytest/user/44
{
"name":"test",
"sex":0,
"age":22
}
###查询文档 根据id查询
GET /mytest/user/60
###查询当前所有类型的文档
GET /mytest/user/_search
##根据多个ID批量查询 查询多个id分别为1、4
GET /mytest/user/_mget
{
"ids":["1","4"]
}
###查询年龄为年龄21岁
GET /mytest/user/_search?q=age:22
###查询年龄30岁-60岁之间 注意:TO 一定要大写
GET /mytest/user/_search?q=age[30 TO 60]
#term是代表完全匹配,即不进行分词器分析,文档中必
#包含整个搜索的词汇
GET /mytest/user/_search
{
"query": {
"term": {
"name": "小李"
}
}
}
####match查询相当于模糊,只包含其中一部分关键词就行
GET /mytest/user/_search
{
"from": 0,
"size": 2,
"query": {
"match": {
"name": "李"
}
}
}
###filter过滤年龄
GET /mytest/user/_search
{
"query": {
"bool": {
"must": [{
"match_all": {}
}],
"filter": {
"range": {
"age": {
"gt": 21,
"lte": 51
}
}
}
}
},
"from": 0,
"size": 10,
"_source": ["name", "age"]
}
GET /mytest/user/_mapping
###创建索引
PUT /myuser
####查询索引
GET /myuser
###查询当前所有类型的文档
GET /myuser/user/_search
####创建文档类型并且指定类型
POST /myuser/_mapping/user
{
"user": {
"properties": {
"sex": {
"type": "integer"
},
"age": {
"type": "integer"
},
"introduce": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
#{
# "user":{
# "properties":{
# "age":{
# "type":"integer"
# },
# "sex":{
# "type":"integer"
# },
# "name":{
## "type":"text",
# "analyzer":"ik_smart",
# "search_analyzer":"ik_smart"
# },
# "car":{
# "type":"keyword"
#
# }
# }
# }
#
#}
##创建索引 默认是5个主分片及1个副本分片,我们##这里不需要这么多,手动指定3个主分片和1个副#本分片:
PUT /mytest2
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
POST /mytest2/user/_mapping
{
"properties": {
"type":"text",
"analyzer":"ik_max_word",
"search_analyzer": "ik_max_word"
}
}
###通过命令查询错误日志
GET /consumer_log/doc/_search
{
"query": {
"match": {
"message": "14:11:58"
}
}
}
Elasticsearch 基本操作
_mapping映射很坑,修改之烦人
1、注意版本一致(我是在Windows搭建的,官网下载解压运行)

elasticsearch配置

启动:

地址:http://localhost:9200/ 如下图启动成功

ik中文分词器安装、配置参照(https://blog.csdn.net/mameng1988/article/details/89049189)https://blog.codecp.org/2018/04/15/Elasticsearch中文分词器IK/
kibana配置

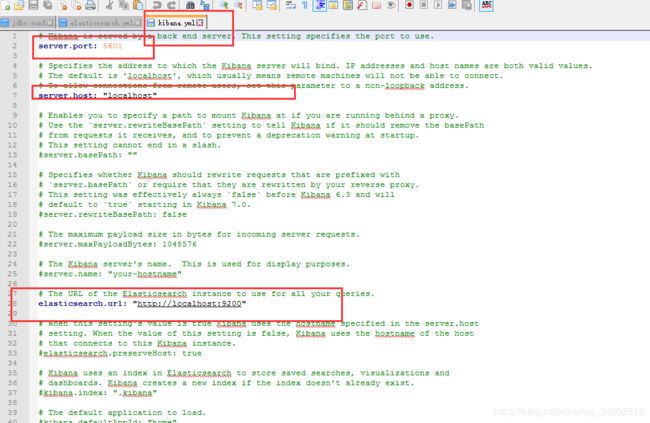
logstash-配置导入数据数据



启动方式:

访问地址:

package com.iccunion.consumer.controller;
import com.github.pagehelper.Page;
import com.iccunion.common.http.HttpResult;
import com.iccunion.consumer.dao.UserDao;
import com.iccunion.consumer.entity.User;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import io.swagger.annotations.ApiParam;
import org.apache.commons.lang3.StringUtils;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.SearchResultMapper;
import org.springframework.data.elasticsearch.core.aggregation.AggregatedPage;
import org.springframework.data.elasticsearch.core.aggregation.impl.AggregatedPageImpl;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.data.elasticsearch.core.query.SearchQuery;
import org.springframework.web.bind.annotation.*;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
import static org.elasticsearch.index.query.QueryBuilders.matchQuery;
/**
* elasticsearch 基本操作
* @author xds
* 访问路径:http://127.0.0.1:8004/swagger-ui.html#/
*/
@Api(value = "elasticsearch 基本操作")
@RestController
public class EsController {
@Autowired
private UserDao userReposiory;
//es工具
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
/**
* 添加修改
* @param user
* @return
*/
@ApiOperation(value="添加用户", notes="添加用户")
@PostMapping("/addUser")
public User addUser(@ApiParam(name = "用户对象", value = "填写用户对象")@RequestBody User user) {
return userReposiory.save(user);
}
/**
* 根据ID查询
* @param id
* @return
*/
@ApiOperation(value="根据ID查询用户", notes="根据ID查询用户")
@GetMapping("/findById")
public Optional findUser( @ApiParam("请输入用户id") @RequestParam(value="id") String id) {
return userReposiory.findById(id);
}
/**
* 查询所有
* @return
*/
@GetMapping("/getAll")
@ApiOperation(value="获取所有的document,不分页", notes="获取所有的document,不分页")
public List getAll() {
Iterable iterable = userReposiory.findAll();
List list = new ArrayList<>();
iterable.forEach(list::add);
return list;
}
/**
* 根据ID删除
* @param id
* @return
*/
@DeleteMapping("/delete/{id}")
@ApiOperation(value="根据ID删除用户", notes="根据ID删除用户")
public HttpResult deleteById(@ApiParam("请输入用户id") @PathVariable String id) {
if (StringUtils.isEmpty(id))
return HttpResult.error();
userReposiory.deleteById(id);
return HttpResult.ok();
}
/**
* 根据姓名查询 作废
* @param introduce
* @return
*/
@GetMapping("/searchIntroduce")
@ApiOperation(value="根据用户介绍查询用户信息", notes="根据用户介绍查询用户信息")
public HttpResult repSearchName( @ApiParam("请输入介绍关键词") @RequestParam(value="introduce") String introduce) {
if (StringUtils.isEmpty(introduce))
return HttpResult.error();
return HttpResult.ok(userReposiory.findByIntroduce(introduce));
}
/**
* 分页查询
* @param name
* @param pageIndex
* @param pageSize
* @return
*/
@ApiOperation(value="根据姓名模糊分页查询", notes="根据姓名模糊分页查询")
@GetMapping("/searchName")
public HttpResult search(@ApiParam("请输入姓名") @RequestParam(value="name")String name,
@ApiParam("页码索引(默认为0)") @RequestParam(value="pageIndex",required=false,defaultValue="0") int pageIndex,
@ApiParam("每页的用户显示数量(默认为2)") @RequestParam(value="pageSize",required=false,defaultValue="2") int pageSize) {
Pageable pageable = new PageRequest(pageIndex, pageSize);
Page users = userReposiory.findByNameLike(name, pageable);
// List list = users.getResult();
return HttpResult.ok(users);
}
/**
* 高级搜索,全文搜索
* 高亮显示参考:https://blog.csdn.net/u014229347/article/details/88895453
* @param keyword 关键字
* @param pageIndex 当前页,从0开始
* @param pageSize 每页大小
*/
@ApiOperation(value="全文检索", notes="全文检索")
@GetMapping("/fullText")
public HttpResult fullText(@ApiParam("请输入关键词(测试输入:java入门佐助李)") @RequestParam(value="keyword")String keyword,
@ApiParam("页码索引(默认为0)") @RequestParam(value="pageIndex",required=false,defaultValue="0") int pageIndex,
@ApiParam("每页的显示数量(默认为20)") @RequestParam(value="pageSize",required=false,defaultValue="20") int pageSize) {
// 构造分页对象
Pageable pageable = PageRequest.of(pageIndex, pageSize);
// 构造查询
NativeSearchQueryBuilder searchQueryBuilder = new NativeSearchQueryBuilder()
.withPageable(pageable)
;
if (!StringUtils.isEmpty(keyword)) {
searchQueryBuilder.withQuery(QueryBuilders.queryStringQuery(keyword))
;
}
// SearchQuery 这个很关键,这是搜索条件的入口, elasticsearchTemplate 会使用它进行搜索
SearchQuery searchQuery = searchQueryBuilder.build();
AggregatedPage users = elasticsearchTemplate.queryForPage(searchQuery, User.class);
return HttpResult.ok(users);
}
/**
* 高级搜索,根据字段进行搜索
* @param name 名称
* @param age 年龄
* @param introduce 介绍
* @param pageIndex 当前页,从0开始
* @param pageSize 每页大小10
*/
@ApiOperation(value="多条件联合查询", notes="多条件联合查询")
@GetMapping("/search")
public HttpResult search(@ApiParam("请输入姓名") @RequestParam(value="name",required = false) String name,
@ApiParam("请输入年龄") @RequestParam(value="age",required = false) String age,
@ApiParam("请输入介绍词") @RequestParam(value="introduce",required = false) String introduce,
@ApiParam("页码索引(默认为0)") @RequestParam(value="pageIndex",required=false,defaultValue="0") int pageIndex,
@ApiParam("每页的显示数量(默认为20)") @RequestParam(value="pageSize",required=false,defaultValue="20") int pageSize
) {
// 构建查询条件
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
if (!StringUtils.isEmpty(name)) {
boolQueryBuilder.must(QueryBuilders.matchQuery("name", name));
}
if (!StringUtils.isEmpty(age)) {
boolQueryBuilder.must(QueryBuilders.matchQuery("age", age));
}
if (!StringUtils.isEmpty(introduce)) {
boolQueryBuilder.must(QueryBuilders.matchQuery("introduce", introduce));
}
// 构造分页对象
Pageable pageable = PageRequest.of(pageIndex, pageSize);
// 封装查询条件
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withPageable(pageable)
.withQuery(boolQueryBuilder)
.build()
;
// 分页查询
AggregatedPage users = elasticsearchTemplate.queryForPage(searchQuery, User.class);
return HttpResult.ok(users);
}
}
ELK+kafka日志收集
为什么要用elk做日志收集系统?
基于es的倒排索引原理,所以查询效率很高,能很快定位,查看系统问题;我这里是用kibana查询,根据系统需要可以集成到自己的项目中.
将错误日志,实时同步到logstash,logstash将日志发到es,通过kibana查询出日志,也可以整合到工程中查询出来
logstash配置

启动命令:logstash -f mylog.conf

也可将系统的日志文件输出路径配置到dao配置文件,每分钟


启动方式:这里我写了一个conf 所以这样启动

请求地址:http://localhost:9600/ 出现如下图内容则启动成功