oracle导出数据到 csv文件方法整理
第一种方法,也是我使用的:
我通过这个方法,按照字段筛选数据,并分别导出多个csv文件:
(1)首先创建存储一个过程,如下,直接复制粘贴即可 。这个存储过程可以直接使用,因为它是通用的,只需要你传入SQL和生成文件的路径就可以。
如果你想多了解一下的话,可以搜一搜oracle内置utl_file读写文件包 ,每分钟大约处理百万行。适用于大量导出的情况
CREATE OR REPLACE PROCEDURE SQL_TO_CSV
(
P_QUERY IN VARCHAR2, -- PLSQL文
P_DIR IN VARCHAR2, -- 导出的文件放置目录
P_FILENAME IN VARCHAR2 -- CSV名
)
IS
L_OUTPUT UTL_FILE.FILE_TYPE;
L_THECURSOR INTEGER DEFAULT DBMS_SQL.OPEN_CURSOR;
L_COLUMNVALUE VARCHAR2(4000);
L_STATUS INTEGER;
L_COLCNT NUMBER := 0;
L_SEPARATOR VARCHAR2(1);
L_DESCTBL DBMS_SQL.DESC_TAB;
P_MAX_LINESIZE NUMBER := 32000;
BEGIN
--OPEN FILE
L_OUTPUT := UTL_FILE.FOPEN(P_DIR, P_FILENAME, 'W', P_MAX_LINESIZE);
--DEFINE DATE FORMAT
EXECUTE IMMEDIATE 'ALTER SESSION SET NLS_DATE_FORMAT=''YYYY-MM-DD HH24:MI:SS''';
--OPEN CURSOR
DBMS_SQL.PARSE(L_THECURSOR, P_QUERY, DBMS_SQL.NATIVE);
DBMS_SQL.DESCRIBE_COLUMNS(L_THECURSOR, L_COLCNT, L_DESCTBL);
--DUMP TABLE COLUMN NAME
FOR I IN 1 .. L_COLCNT LOOP
UTL_FILE.PUT(L_OUTPUT,L_SEPARATOR || '"' || L_DESCTBL(I).COL_NAME || '"'); --输出表字段
DBMS_SQL.DEFINE_COLUMN(L_THECURSOR, I, L_COLUMNVALUE, 4000);
L_SEPARATOR := ',';
END LOOP;
UTL_FILE.NEW_LINE(L_OUTPUT); --输出表字段
--EXECUTE THE QUERY STATEMENT
L_STATUS := DBMS_SQL.EXECUTE(L_THECURSOR);
--DUMP TABLE COLUMN VALUE
WHILE (DBMS_SQL.FETCH_ROWS(L_THECURSOR) > 0) LOOP
L_SEPARATOR := '';
FOR I IN 1 .. L_COLCNT LOOP
DBMS_SQL.COLUMN_VALUE(L_THECURSOR, I, L_COLUMNVALUE);
UTL_FILE.PUT(L_OUTPUT,
L_SEPARATOR || '"' ||
TRIM(BOTH ' ' FROM REPLACE(L_COLUMNVALUE, '"', '""')) || '"');
L_SEPARATOR := ',';
END LOOP;
UTL_FILE.NEW_LINE(L_OUTPUT);
END LOOP;
--CLOSE CURSOR
DBMS_SQL.CLOSE_CURSOR(L_THECURSOR);
--CLOSE FILE
UTL_FILE.FCLOSE(L_OUTPUT);
EXCEPTION
WHEN OTHERS THEN
RAISE;
END;
(2)调用此存储过程测试一下:
第一行是创建一个存储路径“OUT_PATH”,第二行是调用存储过程,第一个参数是查询数据的SQL,第二个参数是文件路径,第三个是文件的名称。
create or replace directory OUT_PATH as 'D:\';
EXEC sql_to_csv('select * from DSJ_ZXJC_ZBYQ_XY','OUT_PATH','ODS_MDS.DSJ_ZXJC_ZBYQ_XY.csv');
(3)下面进行实际使用操作,这是我的使用方法:
我这里先查询了表中所有的sbbm数据,然后再循环sbbm数据集合,根据每一个sbbm进行数据的查询和导出
--SET serveroutput ON;
CREATE OR REPLACE directory OUT_PATH
AS
'D:\anliku800';
DECLARE
CURSOR T_DT_GASINOIL_cursor --定义一个游标
IS
--SELECT DISTINCT sbbm FROM T_DT_GASINOIL;(这里是查询集合的SQL,给游标集合赋值)
SELECT DISTINCT sbbm
FROM
(SELECT tb.*
FROM ggy.t_dt_gasinoil tb,
(SELECT DISTINCT sbbm,
COUNT(*)
FROM ggy.t_dt_gasinoil t
GROUP BY (sbbm)
HAVING COUNT(*) > 800
) tmp
WHERE tmp.sbbm=tb.sbbm
);
-- 查询游标集合的sql在此结束
BEGIN
--开始循环游标
FOR T_DT_record IN T_DT_GASINOIL_cursor
LOOP
--注意此处的传参,在拼接参数时,使用了''',因为我们的sbbm数据是字符串数据
sql_to_csv('select * from T_DT_GASINOIL where sbbm ='''||T_DT_record.sbbm||'''','OUT_PATH','ODS_MDS.'||T_DT_record.sbbm||'.csv');
END LOOP;
END;
第二种方法,使用sql developer:
使用oracle的sql developer导出(这种方法有人验证过,比上面的方法大概快一倍,但是操作简单):
(1)在数据库中找到想要导出的表,右键选择导出。去掉勾选的导出DDL,把格式改成csv,选择相应的编码方式,点击下一步:
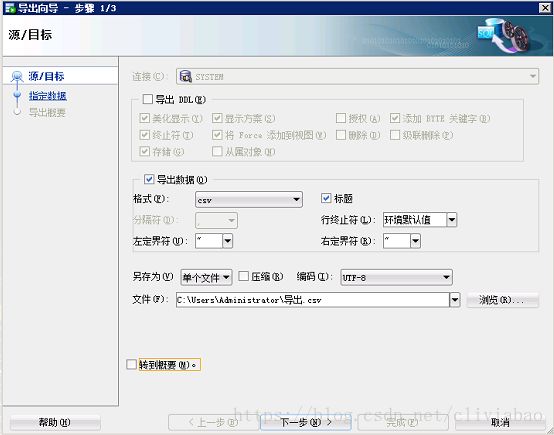
(2)可以在此处添加where子句

(3)根据提示操作
第三种,使用Excel导出,未验证:
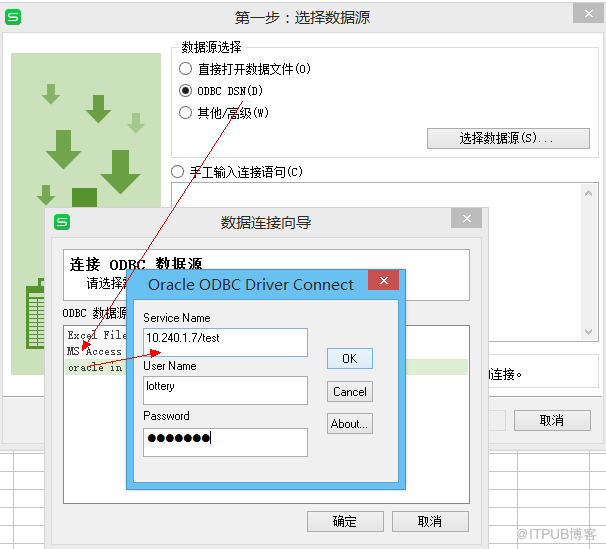
打开excel->数据->导入数据->第一步选择数据源->ODBC DSN->根据情况输入连接信息-->选表字段等
第四种,使用spool导出 (未验证):
(1)新建spool.sql文件
set colsep ,
set feedback off
set heading off
set trimout on
spool D:\DBoracle\lfc.csv
select '"' || user_name || '","' || user_age || '","' || user_card || '","' || user_sex || '","' || user_addres || '","' || user_tel || '"' from lfc_xinxi_tbl;
spool off
exit
(2)sqlplus命令行调用:
sqlplus -s 用户名/密码@数据库名 @spool.sql
参数说明:
set colsep' '; //-域输出分隔符
set newp none //设置查询出来的数据分多少页显示,如果需要连续的数据,中间不要出现空行就把newp设置为none,这样输出的数据行都是连续的,中间没有空行之类的
set echo off; //显示start启动的脚本中的每个sql命令,缺省为on
set echo on //设置运行命令是是否显示语句
set feedback on; //设置显示“已选择XX行”
set feedback off; //回显本次sql命令处理的记录条数,缺省为on即去掉最后的 "已经选择10000行"
set heading off; //输出域标题,缺省为on 设置为off就去掉了select结果的字段名,只显示数据
set pagesize 0; //输出每页行数,缺省为24,为了避免分页,可设定为0。
set linesize 80; //输出一行字符个数,缺省为80
set numwidth 12; //输出number类型域长度,缺省为10
set termout off; //显示脚本中的命令的执行结果,缺省为on
set trimout on; //去除标准输出每行的拖尾空格,缺省为off
set trimspool on; //去除重定向(spool)输出每行的拖尾空格,缺省为off
set serveroutput on; //设置允许显示输出类似dbms_output
set timing on; //设置显示“已用时间:XXXX”
set autotrace on-; //设置允许对执行的sql进行分析参考了此位博主的博客:https://blog.csdn.net/luoyexiadeguang/article/details/81535001