项目 | Java获取Ajax页面(半次元)—— PhantomJS实现(带cookie登录)
写在前面
之前,为了从半次元上下载coser小姐姐的照片,想写个爬虫保存网页上的图片链接,就直接用了Jsoup来读取半次元的网页。
这里说一下,对于想写Java爬虫的小伙伴们来说,Jsoup算是很好用的html解析器,有兴趣深入研究的可以尝试下。
官网:https://jsoup.org/
但是,保存下来的html却和浏览器F12审查元素显示的不一样,这才发觉半次元应该是用了Ajax动态加载网页,而分析异步js又很麻烦(嗯就是懒)。。。
不得已,换方法。
Java+PhantomJs访问网站
PhantomJS是一个可编写脚本的无头网页浏览器。它可以运行在Windows,macOS,Linux和FreeBSD上。
官网:http://phantomjs.org/
所以这里我们的思路就是用PhantomJs当做浏览器访问网站,当然也包括浏览器进行的各种Ajax请求,这样就能在Java中调用并得到一个完整的html,和你在用浏览器访问的效果一样。
1. 下载PhantomJs
- 直接去这里,根据你的系统下载安装包。
- 以win10为例,解压压缩包后,我们需要的只有phantomjs.exe这个文件。
(examples文件夹中有很多使用例子可以查看)

2. 编写访问网站的JavaScript脚本
- 官网Quick Start里有讲到使用方法及代码,这里直接贴我访问网站需要用到的代码。
system = require('system')
address = system.args[1];
path = system.args[2]
var page = require('webpage').create();
var url = address; //访问网址
var savePath = path; //截图保存路径,不写默认保存的调用phantomjs的目录
page.open(url, function (status) {
console.log("Status: " + status);
if (status === 'success') {
window.setTimeout(function () { //设置等待延迟,保证phantom能完整加载出页面
page.render(savePath + "webscreenshot.png"); //网页截图
console.log(page.content); //网页html文本
phantom.exit();
}, 5000);
} else {
console.log('Failed to post!');
phantom.exit();
}
});
- 随便唠唠:
- 截图路径是自己加的,后面保存截图的时候用,不需要的可以不写page.render()相关。
- 吐槽一下PhantomJs有时候很慢而且不稳定,受网速影响很大。为了能保证获取页面加载完毕后的html文本,设置了js的setTimeout()方法,尽可能增加成功率。
3. Java调用PhantomJs执行脚本,获取网页html
- 将phantomjs.exe和刚刚编写的js脚本保存在你的某个目录。
- 你也可以先用cmd命令行测试一下脚本,这里以win10为例
格式为:[phantomjs.exe路径] [脚本.js路径] [网站url] [截图保存路径](截图可选)
例如:D:\phantomjs\phantomjs.exe D:\phantomjs\code.js https://bcy.net/u/12345678 - 进入Java,编写执行代码。如下:
/**
* 获取ajax页面内容
*/
public String getAjaxCotnent(String url, String path) {
String exec = phantom + " " + codejs + " " + url + " " + path; //执行命令,替换成你自己的文件路径
try {
Runtime rt = Runtime.getRuntime();
Process p = rt.exec(exec);
InputStream is = p.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
StringBuffer sbf = new StringBuffer();
String tmp = "";
while((tmp =br.readLine()) != null){
sbf.append(tmp);
}
System.out.println(sbf.toString());
return sbf.toString();
} catch (IOException e) {
e.printStackTrace();
}
return "";
}
- **注意:**这里是调用命令行执行脚本,你的phantomjs.exe、脚本文件及截图文件的存储目录请不要带有空格,否则命令行会将某段目录文字当做执行程序,当然也就不能正常执行脚本了。
以上,我们就能在Java中调用PhantomJs脚本,得到浏览器进行Ajax请求后的html了
PhantomJs携带cookie,登录状态访问网站
本来以为大功告成了,却又发现,有些小姐姐的作品限制了访问权限。
比如登录或者关注才可查看:

也 许 可 以 用 P h a n t o m J s 模 拟 浏 览 器 进 行 写 操 作 , 但 那 样 无 疑 涉 及 到 大 量 j s 脚 本 编 写 , 我 又 不 是 专 门 学 这 个 的 。 。 。 \color{gray}{也许可以用PhantomJs模拟浏览器进行写操作,但那样无疑涉及到大量js脚本编写,我又不是专门学这个的。。。} 也许可以用PhantomJs模拟浏览器进行写操作,但那样无疑涉及到大量js脚本编写,我又不是专门学这个的。。。
所以呢,现在的网站都采用cookie保存用户信息,方便自动登录等操作。如果你要在登录状态下访问网站,只需要给phantom加上cookie就好了。
1. 找到你的cookie
- 使用chrome内核的浏览器,打开你要访问的网站并登录。
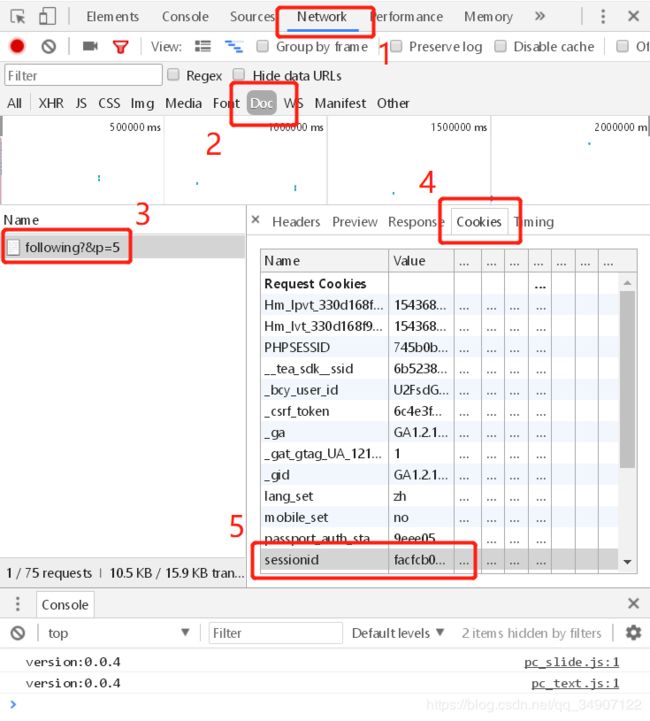
注意:如果像上图一样,也请先手动关注作者后再进行如下操作。 - 登录后(一定登录后,否则哪来的cookie),按F12或右键 > 审查元素,进入后选择Network > Doc > 选择文件 > Cookies,选择你需要的cookie。
以半次元为例,这里我们需要的是sessionid的value值。(如无文件请刷新页面 )
2. phantom添加cookie
- 这里有官网addCookie()方法API
- 修改我们的js脚本代码,添加cookie的代码如下:
system = require('system')
address = system.args[1];
path = system.args[2]
var page = require('webpage').create();
var url = address;
var savePath = path;
//添加cookie,添加成功返回true,否则返回false
var flag = phantom.addCookie({
'name' : 'sessionid', //cookie的name
'value' : '换成你自己的value', //cookie的value
'domain' : '.bcy.net',
'path' : '/',
'httponly' : false,
'secure' : false,
'expires' : 'Fri, 01 Jan 2038 00:00:00 GMT'
});
console.log(flag);
if(flag) {
page.open(url, function (status) {
console.log("Status: " + status);
if (status === 'success') {
window.setTimeout(function () {
page.render(savePath + "webscreenshot.png");
console.log(page.content);
phantom.exit();
}, 5000);
} else {
console.log('Failed to post!');
phantom.exit();
}
});
} else {
console.log('cookies error')
}
这样,我们就能携带cookie以登录状态访问网站了
源码地址:https://github.com/JohnnyJYWu/bcy-webcrawler-Java/tree/master/phantomjs
(包含phantomjs.exe)
结语
这篇文章是为了下一篇文章做的准备。
项目 | Java+PhantomJs爬虫实战——半次元 下载高清原图
第一次写博,有不足之处欢迎各位大佬批评指正。
我的GitHub:https://github.com/JohnnyJYWu