ELK学习指南
一、elasticsearch安装配置
1.1、Elasticsearch介绍
ES是一个基于Lucene实现的开源,分布式,Restful全文搜索引擎,此外,它还是一个分布式实时文档存领储,其中每个文档的第个field均是被索引的数据,且可被搜索,也是一个带实时分析功能的分布式搜索引擎,能够扩展至数以百计的节点实时处理PB级的数据。
基本组件:
索引(index):文档容器,换句话说,索引是具有类似属性的文档的集合。类似于表,索引名必须使用小写字母。
类型(type):类型是索引内部的逻辑分区,其意义完全取决于用户需求,一个索引内部可定义一个或多个类型,一般来说,类型就是拥有相同的域的文档的预定义。
文档(document):文档 是Lucence索引和搜索的原子单位,它包含了一个或多个域,是域的容器,基于JSON格式 表示,每个域的组成部分:一个名字,一个或多个值:拥有多个值的域,通常称为多值域。
映射(mapping):原始内容存储为文档之前需要事先进行分析:例如切词、过滤掉某些词等:映射用于定义此分析机制该如何实现;除此之外,ES还为映射提供诸如将域中的内容排序等功能。
ES的集群组件:
Cluster:ES的集群标识为集群名称;默认为“elasticsearch”。节点就是靠此名称来决定加入到哪个集群,一个节点只能属于一个集群
Node: 支行了单个ES实例的主机即为节点,用于存储数据、参与集群索引及搜索操作。节点的标识靠节点名。
ES Cluster工作过程:
启动时,通过多播(默认)或单播方式在9300/tcp查找同一集群中的其它节点,并与之建立通信。
集群中的所有节点会选举出一个主节点负责管理整个集群状态,以及在集群范围内决定各shards的分布方式。站在用户角度而言,每个均可接收并响应用户的各类请求。
集群有状态:green,red,yellow
1.2、ElasticSearch概念与工作流程介
索引(index):文档的容器,是属性类似的文档集合,类似MySQL中的库或者表的概念,强烈建议同一类的数据放一个索引里
分片(shared):Elasticsearch默认将创建的索引分为5个shard(也可以自定义),每一个shard都是一个独立完整的索引,然后分布在不同的节点上
节点:站在用户角度来看并没有主节点概念,每个节点对用户来说都是一样的,都会响应请求,但是对于集群来说,会有一个主节点用于管理节点状态以及决定shard分布方式,还会周期性检查其他节点是否可用并进行修复。各节点是通过集群名称来判断是否属于同一节点
1.3、Elasticsearch安装过程
1.3.1、安装JAVA环境,所以第一步是安装JDK,
这里我采用yum的安装方式
[root@linux-node1 ~]# yum -y install java-1.8.0-openjdk.x86_64
[root@linux-node1 ~]# java -version 这就表示jdk安装成功
openjdk version "1.8.0_201"
OpenJDK Runtime Environment (build 1.8.0_201-b09)
OpenJDK 64-Bit Server VM (build 25.201-b09, mixed mode)
1.3.2、安装elasticsearch
下载软件包:
官网地址:www.elastic.co
https://www.elastic.co/downloads/past-releases/elasticsearch-6-5-4
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.5.4.tar.gz
1.3.3、配置elasticsearch
下载tar包解压,然后进入config目录,该目录下除了有一个主配置文件elasticsearch.yml需要配置外,还有一个jvm.options文件用于JVM的调优
jvm.options配置文件文件主要是JVM优化相关,关于垃圾回收这块使用默认配置就可以了,我们要调整的就是最大内存和最小内存的设置。通常设置为一样大小,具体的值可以设置为系统最大内存的一半或三分之二
elasticsearch.yml配置文件
[root@linux-node1 config]# grep -Ev "^$|^#" elasticsearch.yml
cluster.name: xiongzhx 集群的名称
node.name: linux-node1 节点名称,如果有多个节点,名称不能一样
path.data: /opt/app/es-data 指定数据存放目录
path.logs: /opt/app/es-logs 指定日志存放目录
bootstrap.memory_lock: true 交换内存锁定
network.host: 192.168.159.190 监听的IP地址
http.port: 9200 监听的端口
discovery.zen.ping.unicast.hosts: ["192.168.159.190", "192.168.159.191"] 使用单播的方式发现集群的节点主机
http.cors.enabled: true 以下两行是为了elasticsearch可以打开head插件
http.cors.allow-origin: "*"
可以参考配置文件详细介绍:
https://www.cnblogs.com/xiaochina/p/6855591.html
1.3.4、启动elasticsearch
首先启动elasticsearch不能使用root用户启动,所以需要先创建一个用户els
将数据和日志存放目录所有者和所属组改成els
chown -R els:els /opt/app/es-data/
chown -R els:els /opt/app/es-logs/
后台启动命令
bin/elasticsearch -d (-d 表示后台启动)
启动成功之后检查服务是否正常
[root@linux-node1 config]# curl http://192.168.159.190:9200
{
"name" : "linux-node1",
"cluster_name" : "xiongzhx",
"cluster_uuid" : "VneGCrQlRL-Zk4LfDR1z-Q",
"version" : {
"number" : "6.3.2",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "053779d",
"build_date" : "2018-07-20T05:20:23.451332Z",
"build_snapshot" : false,
"lucene_version" : "7.3.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}
1.3.5、启动报错的总结
报错信息1:
max virtual memory areas vm.max_map_count [65530] is too low
解决方法1:
修改/etc/sysctl.conf,增加一行vm.max_map_count= 262144。然后执行sysctl -p使其生效
报错信息2:
max file descriptors [65535] for elasticsearch process is too low
解决方法2:
解决办法:修改/etc/security/limits.d/20-nproc.conf 加入如下配置
- soft nofile 65536
- hard nofile 131072
- soft memlock unlimited
- hard memlock unlimited
报错信息3:
max number of threads [3812] for user [els] is too low, increase to at least [4096]
解决方法3
修改/etc/security/limits.d/20-nproc.conf,做以下配置
- soft nproc 4096
root soft nproc unlimited
1.3.6、head插件安装和使用
下载head插件
https://github.com/mobz/elasticsearch-head
下载 elasticsearch-head.tar.gz包
克隆下载:git clone git://github.com/mobz/elasticsearch-head.git
安装npm工具来启动head插件
npm下载直接解压就可以配置环境变量就可以了
wget https://nodejs.org/dist/v10.15.3/node-v10.15.3-linux-x64.tar.xz
tar xf node-v10.15.3-linux-x64.tar.xz
vim /etc/profile 加入如下内容
export PATH=$PATH:/data/node-v10.15.3-linux-x64/bin
source /etc/profile 生效
进入elasticsearch-head目录
npm install
npm install grunt -save
npm run start 直接启动
npm run start & 后台启动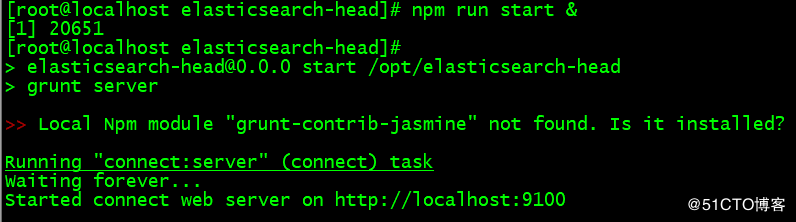
向elasticsearch.yum最后加入如下内容:(启动head插件服务需要)
http.cors.enabled: true
http.cors.allow-origin: "*"
重新启动一下elasticsearch服务
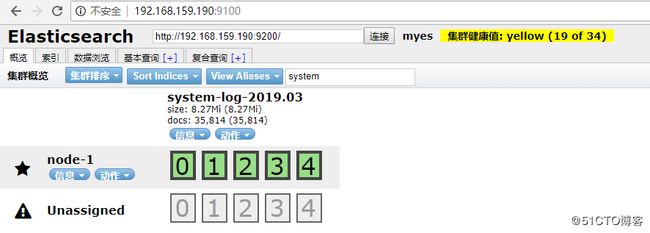
打开浏览器输入:http://192.168.159.190:9100/ 就可以看到创建的索引

二、Logstash安装配置
2.1、安装java环境
这里我采用yum的安装方式
[root@linux-node1 ~]# yum -y install java-1.8.0-openjdk.x86_64
[root@linux-node1 ~]# java -version 这就表示jdk安装成功
openjdk version "1.8.0_201"
OpenJDK Runtime Environment (build 1.8.0_201-b09)
OpenJDK 64-Bit Server VM (build 25.201-b09, mixed mode)
2.2、安装logstash
2.2.1、下载软件包
软件下载地址:https://www.elastic.co/downloads/past-releases/
软件包下载地址:https://artifacts.elastic.co/downloads/logstash/logstash-6.5.4.tar.gz
2.2.2、安装logstash
tar zxf logstash-6.5.4.tar.gz 解压
mv logstash-6.5.4 /usr/local/
cd /opt/app
ln -s /usr/local/logstash-6.5.4 logstash 去版本创建软链接
2.2.3、配置文件修改
1、jvm.options 主要是设置JVM,优化内存
这两个参数尽量配置成一样
2、logstash.yml
3、startup.options
[root@linux-node1 config]# grep -Ev "^$|^#" startup.options
LS_HOME=/usr/share/logstash logstash所在目录
LS_SETTINGS_DIR=/etc/logstash 默认logstash配置文件目录
LS_OPTS="--path.settings ${LS_SETTINGS_DIR}" logstash启动命令参数 指定配置文件目录
LS_JAVA_OPTS="" 指定jdk目录
LS_PIDFILE=/var/run/logstash.pid logstash.pid所在目录
LS_USER=logstash logstash启动用户
LS_GROUP=logstash logstash启动用户组
LS_GC_LOG_FILE=/var/log/logstash/gc.log gc.log文件路径
LS_OPEN_FILES=16384 logstash最多打开监控文件数量
LS_NICE=19
SERVICE_NAME="logstash"
SERVICE_DESCRIPTION="logstash"
2.2.4、启动方法
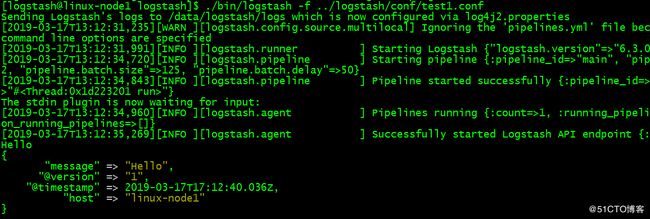
nohup /data/logstash/bin/logstash -f /data/logstash/conf/beat-apache.conf &
验证配置文件语法是否正确:
/data/logstash/bin/logstash -t -f /data/logstash/conf/beat-apache.conf 
简单的验证:
input {
stdin { }
}
filter {
}
output {
stdout {
codec => rubydebug
}
}
2.3、logstash(input、output、filter)学习
2.3.1、input
File用法:
input{
file{
#path属性接受的参数是一个数组,其含义是标明需要读取的文件位置
path => [‘pathA’,‘pathB’]
path => [‘/etc/httpd/logs/’ , ‘/etc/nginx/logs/’]
path => “/var/log/message”表示
#表示多就去path路径下查看是够有新的文件产生。默认是15秒检查一次。
discover_interval => 15
#排除那些文件,也就是不去读取那些文件
exclude => [‘fileName1’,‘fileNmae2’]
exclude => “.gz” 表示不去读取.gz文件
#被监听的文件多久没更新后断开连接不在监听,默认是一个小时。
close_older => 3600
#在每次检查文件列 表的时候, 如果一个文件的最后 修改时间 超过这个值,
就忽略这个文件。 默认一天。
ignore_older => 86400
#logstash 每隔多 久检查一次被监听文件状态( 是否有更新) , 默认是 1 秒。
stat_interval => 1
#sincedb记录数据上一次的读取位置的一个index
sincedb_path => ’$HOME/. sincedb‘
#logstash 从什么 位置开始读取文件数据, 默认是结束位置 也可以设置为:beginning 从头开始
start_position => ‘beginning’
#注意:这里需要提醒大家的是,如果你需要每次都从同开始读取文件的话,关设置start_position => beginning是没有用的,你可以选择sincedb_path 定义为 /dev/null
}
}
举例:收集prtrequest.txt、myes.log、/var/log/
input{
file{
path => ["/var/log/*"]
type => "system-log"
start_position => "beginning"
sincedb_path => "/dev/null"
}
file{
path => "/opt/app/es-logs/myes.log"
type => "es-log"
start_position => "beginning"
sincedb_path => "/dev/null"
codec => multiline{
pattern => "^["
negate => true
what => "previous"
}
}
file{
path => "/tmp/prtRequest.txt"
type => "prtrequest"
start_position => "beginning"
sincedb_path => "/dev/null"
codec => multiline{
pattern => "^%{MONTH}"
negate => true
what => "previous"
}
}
}
filter{
}
output{
if [type] == "system-log" {
elasticsearch {
hosts => ["192.168.159.190:9200"]
index => "system-log-%{+YYYY.MM}"
}
}
if [type] == "es-log" {
elasticsearch {
hosts => ["192.168.159.190:9200"]
index => "es-log-%{+YYYY.MM}"
}
}
if [type] == "prtrequest" {
elasticsearch {
hosts => ["192.168.159.190:9200"]
index => "prtrequest-%{+YYYY.MM}"
}
}
}
自定义正则表达式:
存放目录可以自定义:/opt/app/logstash/pattern/jboss
HMS (?!<[0-9])(?:2[0123]|[01]?[0-9]):(?:[0-5][0-9])(?::(?:(?:[0-5]?[0-9]|60)(?:[:.,][0-9]+)?))(?![0-9])
PTIME %{MONTH} %{MONTHDAY} %{HMS}
IP ((25[0-5]|2[0-4]\d|((1\d{2})|([1-9]?\d))).){3}(25[0-5]|2[0-4]\d|((1\d{2})|([1-9]?\d)))
SESSIONID ([A-Za-z0-9]{32})
URL ([a-zA-z]+://[^\s]*)
filter{
grok{
patterns_dir => ["/opt/app/logstash/pattern/jboss"]
match => { "message" => ".ajp-%{IP:ip}.] [%{SESSIONID:sessionid}.]|%{IP:wanip}|%{URL:url}" }
remove_field => ["beat","tags" ,"_id" ,"host" ,"source","prospector","_type","_score","_source","off
set" ]
}
}
beats用法
input {
beats {
port => 5044
}
}
2.3.2、filter
data用法
filter{
grok{
#只说一个match属性,他的作用是从message 字段中吧时间给抠出来,并且赋值给另个一个字段logdate。
#首先要说明的是,所有文本数据都是在Logstash的message字段中,我们要在过滤器里操作的数据就是message。
#第二点需要明白的是grok插件是一个十分耗费资源的插件,这也是为什么我只打算讲解一个TIMESTAMP_ISO8601正则表达式的原因。
#但是,我还是不建议使用它,因为他完全可以用别的插件代替,当然,对于时间这个属性来说,grok是非常便利的。
match => ['message','%{TIMESTAMP_ISO8601:logdate}']
}}
data {
#将message的时间进行格式华成自己需要的
match => [ "logdate", "MMM dd yyyy HH:mm:ss" ]
target => "@timestamp"
#将匹配的时间戳存储到给定的目标字段中。如果未提供,则默认为更新 @timestamp事件的字段
remove_field => ["logdate"]
#此事件中删除字段logdate
}
grok插件
自定义类型
第一种
直接使用Oniguruma语法来命名捕获,它可以让你匹配一段文本并保存为一个字段:
(?
例如,日志有一个queue_id 为一个长度为10或11个字符的十六进制值。使用下列语法可以获取该片段,并把值赋予queue_id
(?
常用属性有以下几个:
patterns_dir:指定需要匹配的正则表达式文件,一些复杂的正则表达式,不适合直接写到filter中,可以指定一个文件夹,用来专门保存正则表达式的文件,需要注意的是该文件夹中的所有文件中的正则表达式都会被依次加载,包括备份文件
patterns_dir => [“/ opt / logstash / patterns”,“/ opt / logstash / extra_patterns”]
Match
值类型是数组
默认值是 {}
描述:字段⇒值匹配
filter { grok { match => { "message" => "Duration: %{NUMBER:duration}" } } }
mutate插件
常用属性如下:
convert #类型转换
gsub #字符串替换
split/join/merge #字符串切割、数组合并为字符串、数组合并为数组
rename #字段重命名
update/replace #字段内容更新或替换
remove_field #删除字段
filter {
mutate {
split => [ “message” ,“ - ” ]
add_field => { “hostname” => “%{message[0]}” }
}
mutate {
rename => [ “hostname” ,“xiongzhx” ]
}
}
#上面这段话的意思就是使用 “ - ”进行日志切换,message[0]表示第一段内容,message[1]表示第二段内容,依次往下,然后使用字段hostname存放message[0]的内容。
最后再将hostname重名名为xiongzhx
配置文件详细介绍
https://blog.csdn.net/len9596/article/details/82884507
插件详细介绍:
https://blog.csdn.net/xushiyu1996818/article/details/84030000
三、kinaba安装配置
3.1、安装过程
Kianba.yml配置文件修改如下:
[root@localhost config]# grep -Ev "^$|^#" kibana.yml
server.port: 5601
server.host: "192.168.159.180"
elasticsearch.url: "http://192.168.159.180:9200"
后台启动方法
Cd /opt/app/kibana
nohup ./bin/kibana &
3.2、添加索引
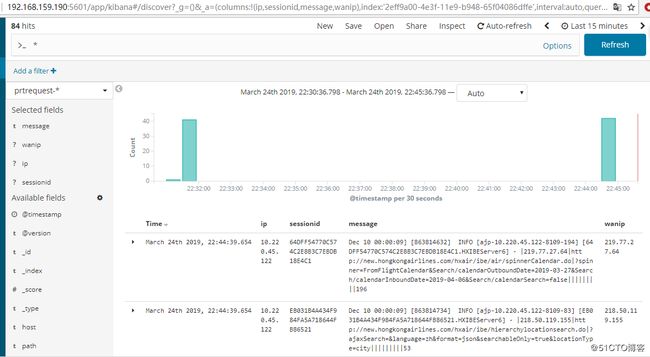
添加prtrequest.log日志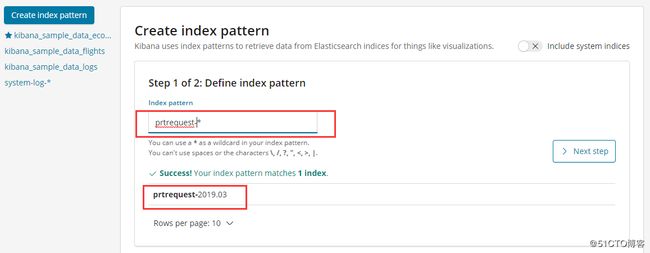
添加完成之后看到的效果:
日志切割之后