机器学习习题(9)
1. 前言
前事不忘后事之师。
2. 习题
2.1 习题1(判别式模型)
以下几种模型方法属于判别式模型的有:
1)混合高斯模型
2)条件随机场模型
3)区分度训练
4)隐马尔科夫模型A.1,4
B.3,4
C.2,3
D.1,2
正确答案:C
解析:这题是做过一遍的,可能印象不深,我们这里再讲一遍。
判别式模型与生成式模型的区别
产生式模型(Generative Model)与判别式模型(Discrimitive Model)是分类器常遇到的概念,它们的区别在于:
对于输入x,类别标签y:
产生式模型估计它们的联合概率分布P(x,y)
判别式模型估计条件概率分布P(y|x)
产生式模型可以根据贝叶斯公式得到判别式模型,但反过来不行。
对于1,混合高斯模型来说,首先是要知道单高斯模型,它主要用来处理图像的,因此它就如同聚类一般,只不过它的形状在二维中是椭圆形,在三维中是椭球型。而混合高斯模型,则是使用多个单高斯模型混合而成,有点类似聚类的感觉。我说的这个意思应该懂的。
具体的,可以参考《混合高斯模型介绍》与百度百科——混合高斯模型。
而区分度训练就是逻辑斯特回归。条件随机场和隐马尔可夫模型就不用我多讲了吧。隐马尔可夫模型是生成模型,条件随机场是判别模型。这些在李航的《统计学习方法》中也讲得很明白,在第12章中,对主要介绍的10种统计学习方法有了详尽的总结。
当然有一点要注意的是,为什么这几个名词比较生疏,是因为这些题目都比较陈旧,当时机器学习还没有像现在这样火热,因此有很多名词也堙没在历史之中了。
2.2 习题2(降维)
下列哪些方法可以用来对高维数据进行降维:
A.LASSO
B.主成分分析法
C.聚类分析
D.小波分析法
E. 线性判别法
F.拉普拉斯特征映射
正确答案:ABCDEF
解析:
这个在之前的博客中讲过,首先线性的PCA(主成分分析法)和LDA(线性判别法)是肯定要知道的。
Lasso(Least absolute shrinkage and selection operator, Tibshirani(1996)) 方法是一种压缩估计,它通过构造一个罚函数得到一个较为精炼的模型,使得它压缩一些系数,同时设定一些系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。Lasso 的基本思想是在回归系数的绝对值之和小于一个常数的约束条件下,使残差平方和最小化,从而能够产生某些严格等于 0 的回归系数,得到可以解释的模型。
聚类分析:将个体(样品)或者对象(变量)按相似程度(距离远近)划分类别,使得同一类中的元素之间的相似性比其他类的元素的相似性更强。目的在于使类间元素的同质性最大化和类与类间元素的异质性最大化。其主要依据是聚到同一个数据集中的样本应该彼此相似,而属于不同组的样本应该足够不相似。
聚类分析本来就是一种降维技术,只不过我们通常会把它与分类平起平坐,但实际上他也是可以进行降维的。
小波分析和拉普拉斯特征映射都比较不太常见。下图可以表示出降维方法的总结:
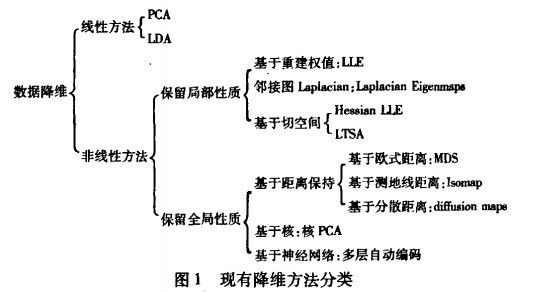
更细节的部分,可以查阅《降维方法总结》。
2.3 习题3(数据不平衡)
在分类问题中,我们经常会遇到正负样本数据量不等的情况,比如正样本为10w条数据,负样本只有1w条数据,以下最合适的处理方法是()
A.将负样本重复10次,生成10w样本量,打乱顺序参与分类
B.直接进行分类,可以最大限度利用数据
C.从10w正样本中随机抽取1w参与分类
D.将负样本每个权重设置为10,正样本权重为1,参与训练过程
正确答案:ACD
解析:对于这一块我想还是有一些了解的
1. 重采样。
A可视作重采样的变形。改变数据分布消除不平衡,可能导致过拟合。
2. 欠采样。
C的方案 提高少数类的分类性能,可能丢失多数类的重要信息。
如果1:10算是均匀的话,可以将多数类分割成为1000份。然后将每一份跟少数类的样本组合进行训练得到分类器。而后将这1000个分类器用assemble的方法组合位一个分类器。A选项可以看作此方式,因而相对比较合理。
另:如果目标是 预测的分布 跟训练的分布一致,那就加大对分布不一致的惩罚系数。
3. 权值调整。
D方案也是其中一种方式。
当然,这只是在数据集上进行相应的处理,在算法上也有相应的处理方法。
2.4 习题4(先验概率)
在统计模式识分类问题中,当先验概率未知时,可以使用()?
A.最小损失准则
B.N-P判决
C.最小最大损失准则
D.最小误判概率准则
正确答案:BC
解析:
选项 A
最小损失准则中需要用到先验概率
选项B
在贝叶斯决策中,对于先验概率p(y),分为已知和未知两种情况。
1. p(y)已知,直接使用贝叶斯公式求后验概率即可;
2. p(y)未知,可以使用聂曼-皮尔逊决策(N-P决策)来计算决策面。
聂曼-皮尔逊决策(N-P判决)可以归结为找阈值a,即:
如果 p(x|w1)/p(x|w2)>a ,则 x属于w1;
如果 p(x|w1)/p(x|w2)<a ,则 x属于w 2;
选项C
而最大最小损失规则主要就是使用解决最小损失规则时先验概率未知或难以计算的问题的。
2.5 习题5(excel)
excel工作簿a中有两列id、age,工作簿b中有一列id,需要找到工作薄b中id对应的age,可用的函数包括
A.index+match
B.vlookup
C.hlookup
D.find
E.if
F.like
正确答案:AB
解析:
Excel中MATCH函数可以返回指定内容所在的位置,而INDEX又可以根据指定位置查询到位置所对应的数据,各取其优点,我们可以返回指定位置相关联的数据。
MATCH函数(返回指定内容所在的位置)
MATCH(lookup-value,lookup-array,match-type)
lookup-value:表示要在区域或数组中查找的值,可以是直接输入的数组或单元格引用。
lookup-array:表示可能包含所要查找的数值的连续单元格区域,应为数组或数组引用。
match-type:表示查找方式,用于指定精确查找(查找区域无序排列)或模糊查找(查找区域升序排列)。取值为-1、1、0 。其中0为精确查找。
INDEX(array,row-num,column-num)
array:要返回值的单元格区域或数组。
row-num:返回值所在的行号。
column-num:返回值所在的列号。
excel里根据一个工作簿的一个工作表的A列内容搜索另外一个工作簿对应A列的B列值
在sheet1的B1输入:=vlookup(A1,sheet2!A1:B?,2,1)
其中?指sheet2的最后一行号。
下拖时应该将第二项改为绝对引用,即:$A$1:$B$
3. 小结
本章中,我们主要复习了判别式模型、降维、数据不平衡、先验概率和excel相关知识。