Akka 指南 之「集群规范」
温馨提示:Akka 中文指南的 GitHub 地址为「akka-guide」,欢迎大家
Star、Fork,纠错。
集群规范
注释:本文描述了 Akka 集群的设计概念。
文章目录
- 集群规范
- 简介
- 术语
- Membership
- Gossip
- Vector Clocks
- Gossip Convergence
- Failure Detector
- Leader
- Seed Nodes
- Gossip Protocol
- Membership Lifecycle
- Member States
- User Actions
- Leader Actions
- Failure Detection and Unreachability
简介
Akka 集群(Cluster)提供了一种容错的、分散的、基于点对点(peer-to-peer)的集群成员(membership)服务,不存在单点故障或单点瓶颈。它使用Gossip协议和自动故障检测器(failure detector)来实现这一点。
Akka 集群允许构建分布式应用程序,其中一个应用程序或服务可以跨越多个节点(实际上是多个ActorSystem)。另请参见在「何时何地使用 Akka 集群」中的讨论。
术语
-
节点(
node),集群的逻辑成员。物理计算机上可能有多个节点,由hostname:port:uid元组定义。 -
集群(
cluster),通过成员服务连接在一起的一组节点。 -
领导(
leader),集群中充当领导者的单个节点。管理集群聚合(convergence)和成员(membership)状态转换。
Membership
集群由一组成员节点组成。每个节点的标识符是hostname:port:uid元组。Akka 应用程序可以分布在集群上,每个节点承载应用程序的某些部分。集群成员和运行在应用程序节点上的 Actor 是分离的。节点可以是集群的成员,而不承载任何 Actor。加入集群是通过向集群中要加入的一个节点发出Join命令来启动的。
节点标识符内部还包含一个唯一标识,即该hostname:port处 Actor 系统实例的 UID。Akka 使用 UID 能够可靠地触发远程死亡监视(remote death watch)。这意味着相同的 Actor 系统在从集群中删除后,不能再加入该集群。要将具有相同hostname:port的 Actor 系统重新连接到集群,你必须停止 Actor 系统并使用相同hostname:port启动一个新系统,然后该系统将接收一个不同的 UID。
集群成员状态是一个特殊的「CRDT」,这意味着它具有一个不变的合并函数。当不同节点上发生并发修改时,更新总是可以合并并收敛到相同的最终结果。
Gossip
Akka 中使用的集群成员是基于 Amazon 的「Dynamo」系统,特别是在 Basho 的「Riak」分布式数据库中采用的方法。集群成员是通过「Gossip Protocol」进行通信的,其中集群的当前状态是通过集群随机传播的,优先于没有看到最新版本的成员。
Vector Clocks
「向量时钟」是一种数据结构和算法,用于生成分布式系统中事件的部分排序和检测因果关系冲突。
我们使用向量时钟来协调和合并协议作用期间(during gossiping)集群状态的差异。向量时钟是一组(节点,计数器)对。对集群状态的每次更新都会附带对向量时钟的更新。
Gossip Convergence
有关集群的信息在特定时间点在节点上本地聚合(converges locally)。此时节点可以证明他正在观察的集群状态已被集群中的所有其他节点观察到。通过传递一组在协议期间看到当前状态版本的节点来实现聚合。这些信息被称为“流言概述(gossip overview)”中的“可见集”。当所有节点都包含在可集合中时,就会出现聚合(Convergence)。
当任何节点都无法访问(unreachable)时,不会发生消息聚合(Gossip convergence)。节点需要再次变得可访问(reachable),或者移动到down和removed状态(请参见下面的 Membership Lifecycle 部分)。这只会阻止leader执行其集群成员资格管理,而不会影响集群顶层运行的应用程序。例如,这意味着在网络分裂(network partition)期间,不可能向集群添加更多节点。节点可以连接,但在分裂修复或关闭不可访问的节点之前,它们不会移动到up状态。
Failure Detector
故障检测器(failure detector)负责检测一个节点是否无法从集群的其余部分访问。为此,我们使用了「The Phi Accrual Failure Detector」的实现。
Accrual Failure Detector 将监控和解释分离。这使得它们适用于更广泛的场景领域,并且更适合构建通用的故障检测服务。其思想是,它保存一个故障统计的历史记录,根据从其他节点接收到的心跳进行计算,并试图通过考虑多个因素以及它们如何随着时间累积来进行有根据的猜测,以便更好地猜测特定节点是否关闭。而不仅仅是回答“节点是否关闭?”的“是”或“否”的问题“,它返回一个phi值,表示节点关闭的可能性。
作为计算基础的阙值(threshold)可由用户配置。低阙值容易产生许多错误的怀疑,但可以确保在发生真正的崩溃时快速检测。相反,高阙值产生的错误更少,但需要更多的时间来检测实际的崩溃。默认阈值为8,适用于大多数情况。然而,在云环境中,例如 Amazon EC2,为了解决此类平台上有时出现的网络问题,其值可以增加到12。
在集群中,每个节点都由几个(默认最多 5 个)其他节点监控,当其中任何一个节点检测到无法访问该节点时,信息将通过流言传播到集群的其余部分。换句话说,只要一个节点需要将一个节点标记为不可访问,则集群的其余部分都将该节点标记为不可访问。
要监视的节点是在散列有序节点环中从相邻节点中挑选出来的。这是为了增加跨数据中心监控的可能性,但所有节点上的顺序都相同,这确保了完全覆盖。
心跳每秒发出一次,每一次心跳都在请求/回复握手中执行,回复用于故障检测器的输入。
故障检测器还将检测节点是否可以再次访问。当监视不可访问节点的所有节点再次检测到它是可访问的时,在散播流言之后,集群将认为它是可访问的。
如果系统消息无法传递到节点,那么它将被隔离,然后它将无法从无法访问的状态返回。如果有太多未确认的系统消息(例如监视、终止、远程 Actor 部署、远程父级监控的 Actor 失败),则可能发生这种情况。然后需要将节点移动到down或removed状态(请参见下面的 Membership Lifecycle 部分),并且必须重新启动 Actor 系统,然后才能再次加入集群。
Leader
在消息聚合之后,可以确定集群的leader。没有leader的选举过程,只要有消息聚合,任何一个节点都可以确定地被识别为领导者。leader只是一个角色,任何节点都可以是leader,它可以在消息聚合之间切换角色。leader是能够担任领导角色的第一个按序节点,有关更多成员状态的信息,请参见下面的 Membership Lifecycle 部分。
leader的角色是将成员移入或移出集群,将joining成员更改为up状态,或将exiting成员更改为removed状态。目前,leader的行为只是通过接收一个带有信息聚合的新的集群状态来触发的。
通过配置,leader也有能力“自动关闭(auto-down)”一个节点,根据故障检测器,该节点被认为是不可访问的。这意味着在配置的不可访问时间之后,将unreachable节点状态自动设置为down。
Seed Nodes
种子节点(seed nodes)是为加入集群的新节点配置的联系点。当一个新节点启动时,它会向所有种子节点发送一条消息,然后向首先应答的种子节点发送一个join命令。
种子节点配置值对正在运行的集群本身没有任何影响,它只与加入集群的新节点相关,因为它帮助它们找到要向其发送join命令的联系点;新成员可以将此命令发送到集群的任何当前成员,而不仅仅发送到种子节点。
Gossip Protocol
push-pull gossip的一种变体被用来减少在集群中发送的消息信息量。在push-pull gossip中,发送的摘要表示当前版本,而不是实际值;然后,消息的接收者可以返回其具有较新版本的任何值,也可以请求其具有过时版本的值。Akka 使用一个带有向量时钟的单一共享状态进行版本控制,因此 Akka 中使用的push-pull gossip使用此版本仅在需要时推送实际状态。
周期性地,默认为每 1 秒,每个节点选择另一个随机节点来启动一轮流言。如果可见集合(seen set)中的节点数少于 ½(已看到新状态),那么集群将进行 3 次流言,而不是每秒一次。这种调整后的流言间隔是在状态变化后的早期传播阶段加快聚合过程的一种方法。
选择要传播的节点是随机的,但是偏向于那些可能没有看到当前状态版本的节点。在每一轮的信息交换中,当还未达到聚合时,一个节点使用非常高的概率(可配置)来与另一个不属于所见集的节点(即可能具有较旧版本状态的节点)传播消息。否则,它会与任何随机活动节点闲聊。
这种有偏选择是在状态变化后的后期传播阶段加快聚合过程的一种方法。
对于大于 400 个节点的集群(可配置,根据经验建议),0.8 的概率逐渐降低,以避免出现过多并发消息请求的压倒性单个节点。消息接收者还具有一种机制,通过丢弃在邮箱中排队时间过长的消息,来保护自己免受过多消息的影响。
当集群处于聚合状态(状态一致)时,消息发送者只向所选节点发送包含较小状态的消息。一旦集群发生变化(意味着不聚合),它就会再次回到有偏见的消息传播。
消息状态或消息状态的接收者可以使用消息版本(向量时钟)来确定:
- 它有一个新版本的消息状态,在这种情况下,它会把它发送回消息传播者。
- 它有一个过时的状态版本,在这种情况下,接收者通过发送消息状态的版本来请求消息传播者的当前状态。
- 它有冲突的消息版本,在这种情况下,不同版本的消息被合并,并发送回去。
如果消息接收者和消息的版本相同,则不会发送或请求消息状态。
消息的周期性具有状态更改的良好批处理效果,例如,将几个节点快速地彼此连接到一个节点之后,只会导致一个状态更改传播到集群中的其他成员。
消息用「protobuf」序列化,也用gzip压缩以减小有效负载的大小。
Membership Lifecycle
节点以joining状态开始。一旦所有节点都看到新节点正在加入(通过消息聚合),则leader将会设置成员状态为up。
如果一个节点以一种安全的、预期的方式离开集群,那么它将切换到leaving状态。一旦leader看到节点上的收敛处于leaving状态,leader就会将其移动到exiting状态。一旦所有节点都看到exiting状态,leader将从集群中删除该节点,并将其标记为removed。
如果一个节点是不可访问的,那么消息聚合是不可能的,因此leader的任何行为也是不可能的(例如,允许一个节点成为集群的一部分)。为了能够向前移动,必须更改unreachable节点的状态。它必须可以再次reachable或标记为down。如果节点要再次加入集群,那么必须重新启动 Actor 系统,并再次执行加入过程。集群还可以在配置的不可到达时间之后,通过leader自动关闭节点。如果unreachable节点的新化身(重新启动,生成新的 UID)尝试重新加入集群,则旧的化身将标记为down,并且新的化身可以在无需手动干预的情况下重新加入集群。
- 注释:如果你启用了自动关闭(
auto-down)并触发了故障检测器,那么如果你没有采取措施关闭unreachable的节点,那么随着时间的推移,你可能会得到许多单节点集群。这是因为unreachable节点可能会将集群的其余部分视为不可访问,成为自己的leader并形成自己的集群。
如前所述,如果一个节点是unreachable,那么消息聚合是不可能的,因此leader的任何行为也是不可能的。通过启用akka.cluster.allow-weakly-up-members(默认情况下启用),可以在尚未达到聚合时提升新的连接节点。这些Joining节点将升级为WeaklyUp。一旦达到了消息聚合,leader就会把WeaklyUp的成员状态设置为Up。
请注意,网络分裂另一侧的成员不知道新成员的存在。例如,在quorum decisions时,你不应该把WeaklyUp的成员计算在内。
- State Diagram for the Member States (
akka.cluster.allow-weakly-up-members=off)
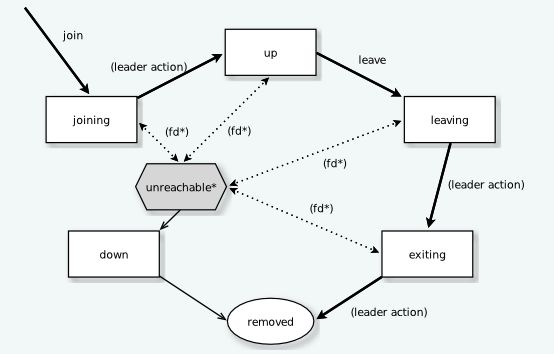
- State Diagram for the Member States (
akka.cluster.allow-weakly-up-members=on)

Member States
joining:联接集群时的瞬态状态weakly up:网络分裂时的瞬时状态,仅当akka.cluster.allow-weakly-up-members=on开启时,才会出现此状态up:正常工作状态leaving / exiting:优雅删除期间的状态down:当节点不再参与集群决策时,会标记为downremoved:逻辑删除的状态,标记该节点不再是集群的成员
User Actions
join:将单个节点联接到集群,如果在配置中指定了要联接的节点,则在启动时可以是显式的或自动的联结节点leave:告诉节点优雅地离开集群down:将节点标记为down
Leader Actions
leader的职责如下:
- 将成员移入或移出集群中
joining -> upweakly up -> up(执行此操作,不需要消息收敛)exiting -> removed
Failure Detection and Unreachability
fd*:某个监控节点的故障检测器被触发,则将被监控节点被标记为unreachable。unreachable*:unreachable不是一个真正的成员状态,而是一个标志,除了表示集群无法与此节点通信的状态之外,在unreachable之后,故障检测器可能会再次检测到它是reachable的,从而删除该标志。
英文原文链接:Cluster Specification.
———— ☆☆☆ —— 返回 -> Akka 中文指南 <- 目录 —— ☆☆☆ ————