分布式计算框架Mapreduce
概念:
Mapreduce是一种编程模型,编程方法,采用“分而自治”思想
优点:海量数据离线处理,易开发,易运行。
缺点:实时流式计算
MapReduce编程模型之执行步骤:
输入一个大文件,通过Split之后,将其分为多个片
每个文件分片由单独的机器去处理,这就是map方法
将各个机器计算的结果进行汇总并得到最终的结果,这就是reduce方法
MapReduce的四个阶段:
Spilt
Map(需要编码)
Shuffle:可以理解为从Map输出到reduce输入的过程,而且设计网络传输
Reduce(需要编码)
节点Map任务的个数:
在实例情况下,map任务的个数是受多个条件的制约,一般一个DataNode的map任务数量控制在10到100比较合适。
准则1:增加map任务的个数,可真大mapred.map.tasks
准则2:减少map任务的个数,可增大mapred.min.split.size
如果减少map个数,但有很多个小文件,可将小文件合并成大文件,再使用准则2
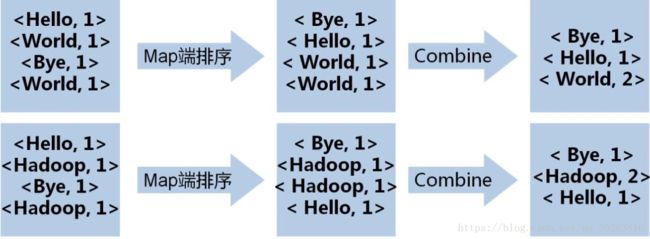
本地优化---Combine:
ComBine本质上是在Mapper缓存区溢写文件的合并
数据经过map端输出后,会进行网络混洗,经过shuffle后进入Reduce,在大数据量的情况下可能会造成巨大的网络开销。
故可以在本地先按照key进行一轮排序与合并,再进行网络混洗,这个过程就是Combine
在多数情况下,Combine的逻辑和Reduce的逻辑一致的,即都是按照key合并数据,故可认为Combine是对本地数据的Reduce操作、这里复用Reducer的逻辑,也可以自己实现Combiner类。
job.setCombinerClass(MyReduce.class)//设置ComBine
job.setReducerClass(MyReduce.class)//设置Reducer。
节点Reduce任务的个数:
在大数据量的情况下,如果只设置一个reduce任务,那么在reduce阶段,整个集群中只有该节点运行reduce任务,其他的节点都将被闲置,效率十分低下。故将reduce任务数量设置为一个较大的值(最大值为72)
一个节点上的reduce任务数并不像map任务那样受多个因素制约。
准则1:可以通过调节参数:mapred.reduce.tasks
准则2:可以在代码中调用job.setNumReduceTasks(int n)
Partition是在Reduce输入发生之前,相同的key值一定会进入同一个Partitioner,Reduce过程会按照key排序
一个MapReduce作业中,Partitioner的数量,Reducer数量,最终输出文件(如:part-r-00000)三者数量一样
在一个Reducer中,所有的数据都会被按照key值升序排序,故如果part输出文件中包含key值,则这个文件一定是有序

WordCount统计分析过程:

MapReduce核心概念:
Spilt:交由MapReduce作业来处理的数据块,是MapReduce中的最小单元
HDFS:blocksize是HDFS中最小的存储单元 128MB
默认情况下:他们是一对一对应的,当然也可以手工设置他们之间的关系(不建议)
InputFormat:将我们的输入数据进行分片(spilt):InputSpilt[] getSpilts()
TextInputFormat:处理文本格式数据
OutPutFormat:
Combiner:
Partitioner:

MapReduce1.x的架构:
JobTracker:
作业的管理者
将作业分解成一堆的任务:Task(MapTask和ReduceTask)
将任务分派给TaskTracker运行
作业的监控,容错处理(task作业挂了,重启task的机制)
在一定时间间隔内,JT没有收到TT的心跳信息,TT可能是挂了,TT上运行的任务会被指派到其他TT上去执行
TaskTracker:
任务执行者
在TT上执行我们的Task(MapTask和ReduceTask)
会与JT进行交互:执行/启动/停止作业,发送心跳信息给JT
MapTask:
自己开发的map任务交由该Task出来
解析每条记录的数据,交给自己的map方法处理
将map的输出结果写到本地磁盘(有些作业仅有map没有reduce==》HDFS)
ReduceTask:
将Map Task输出的数据进行读取
按照数据进行分组后,传给我们自己编写的reduce方法处理
输出结果到HDFS
MapReduce2.x的架构
在MapReduce中,输出文件是不能事先存在的
1.先通过shell的方式将输出文件夹删除
2.在代码中完成自动删除功能(推荐使用)
MapReduce编程之Combiner(本地reducer)
减少MapTasks输出的数据量及网络传输量
使用场景:求和,不能求平均数
MapReduce编程之Partitioner
Partitioner决定MapTask输出的数据交由那个Reduce处理。
默认实现:分发的key的hash值对Reduce Task个数取模
Jobhistory
记录已运行完的MapReduce信息到指定的HDFS目录下,默认不开启
mr-jobhistory-daemon.sh start historyserver