KMeans+DBSCAN小试
这是我的第一篇文章,同时也记录着我在读研时候的点点滴滴,从12月17日开始~
KMeans+DBSCAN算法
Kmeans
KMeans算法是一种聚类算法,而聚类问题在机器学习中主要是是一类无监督问题:简单理解是手中无标签,我们要去分出标签。这类问题的难点是:如何去评估,也就是怎么来评估我们算法的好坏。如何调参?也就是到底有多少个聚类中心点。
KMeans最大的问题就是一个先验知识,这个先验知识是让我们知道如何对Kmeans要分出来的区域进行一个判断。DBSCAN
DBSCAN同样是一类聚类算法,其算法要点:阈值+核心对象+密度可达(包含直接密度可达)+边界点,理解了上述的要点,这个算法根本无难点。
KMeans+DBSCAN DemoTime
demo
我这里选用的工具是Jupyter+Python3.6的环境,上述的两类算法是非常简单的,主要是如何去实现这类算法:
#pandas提供了大量能使我们快速便捷地处理数据的函数的方法,对入门小白具体用法参见廖雪峰python
import pandas as pd
beer = pd.read_csv('D:/WorkData/Jupyter/KMeans-DBSCAN/data.txt',sep=' ')
beer.head(3)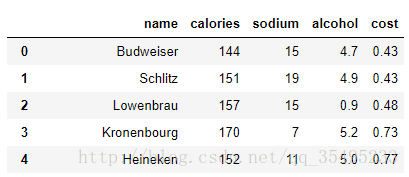
#观察到上述代码是一堆啤酒的数据,那么对啤酒的各个参数进行聚类对比
X = beer[["calories","sodium","alcohol","cost"]]
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3).fit(X)
km2 = KMeans(n_clusters=2).fit(X)
km.labels_ #完成一次分类,将20种啤酒完成分类操作
beer['cluster'] = km.labels_
beer['cluster2'] = km2.labels_
beer.sort_values('cluster') #将每行分类加入啤酒这个表格
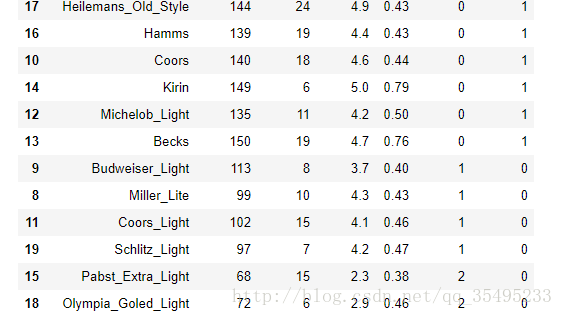
#尝试着画出啤酒与散点之间的关系
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
cluster_centers = km.cluster_centers_
cluster_centers_2 = km2.cluster_centers_
centers = beer.groupby("cluster").mean().reset_index()
colors = np.array(['red','green','blue','yellow'])
plt.scatter(beer["calories"], beer["alcohol"],c=colors[beer["cluster"]])
plt.scatter(centers.calories,centers.alcohol,linewidths=3,marker='+',s=200,c='black')
plt.xlabel("Calories")
plt.ylabel("Alcohol")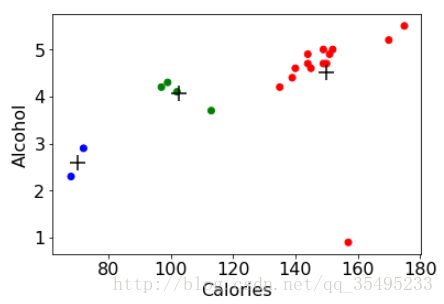
##显然,一幅图是不能满足我们所有的需求的,我们选择将其余的关系图加入
scatter_matrix(beer[["calories","sodium","alcohol","cost"]],s=200, alpha=1, c=colors[beer["cluster"]], figsize=(20,20))
plt.suptitle("With 3 centrois initialized")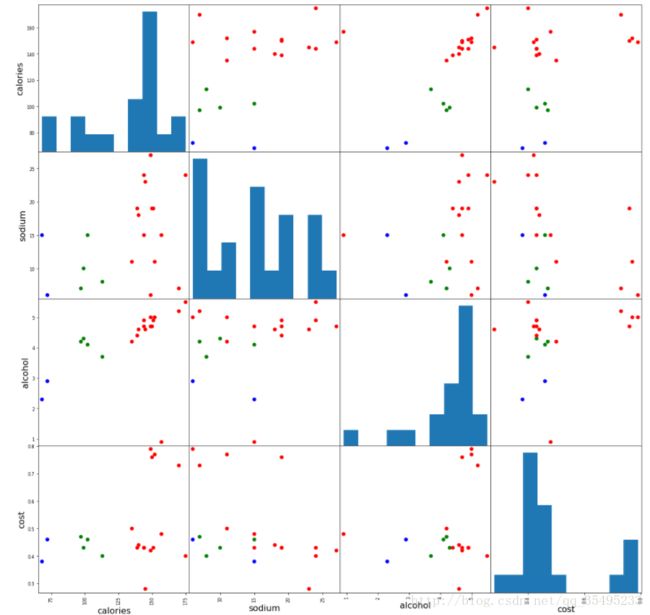
#这时我们发现聚类效果不佳,会选择做一个标准化处理,标准化处理后重复上述步骤,比较这两种方法的好坏
#重点来了?如何评价标准好坏?聚类评估最常用的就是轮廓系数,我们利用轮廓系数的方法来评判
from sklearn import metrics
score_scaled = metrics.silhouette_score(X,beer.scaled_cluster) #原始数据+标准化后数据
score = metrics.silhouette_score(X,beer.cluster) #原始数据+不做标准化后数据
print(score_scaled,score) #震惊!标准化后反而结果差
#0.179780680894 0.673177504646
#同时做一次KMean调参过程的轮廓系数遍历
#[0.69176560340794857,0.67317750464557957,0.58570407211277953,0.42254873351720201,0.4559182167013377,0.43776116697963124,0.38946337473125997,0.36586121827123158,0.40815990138996028,0.32472080133848924,0.34597752371272478,0.31221439248428434,0.30707782144770296,0.31834561839139497,0.28495140011748982,0.23498077333071996,0.15880910174962809,0.084230513801511767]
#另一个算法DBSCAN处理手法一样,需要我们的耐心,主要是简单调用sklearn库来执行
from sklearn.cluster import DBSCAN
db = DBSCAN(eps=10, min_samples=2).fit(X)
labels =db.labels_
beer['cluster_db'] =labels
beer.sort_values('cluster_db')
...
总结Summary
- KMeans与DBSCAN算法初步入门
- 并不是标准化就是一件好事情
- 时候不早,我也是百忙抽出时间来写博客,所以写的内容针对有一定python基础的用户,如果对这篇文章不明白,欢迎留言给我我会做详细解答,代码也会放到github上提供下载