NLP进阶之(一)Seq2Seq模型之Chatbot
NLP进阶之(一)Seq2Seq模型之Chatbot
- 1. 编码器—解码器(seq2seq)
- 解释
- 1.1 编码器
- 1.2 解码器
- 1.3 模型训练
- 1.4 参考文献
- 2. 注意力机制(Attention)
- 2.1 注意力机制背景
- 2.2 计算背景变量
- 2.3 矢量化计算
- 2.4 更新隐藏状态
- 3. 小结
- 3.1 参考链接
1. 编码器—解码器(seq2seq)
NLP之前的章节中处理并分析了不定长的输入序列。但在很多应用中,输入和输出都可以是不定长序列。以机器翻译为例,输入可以是一段不定长的问题文本序列,输出可以是一段不定长的回答文本序列,例如
有 , 现在 我 在 努力学习 英文 , 我 想 成为 一名 翻译 。 嗯 , 你 是 大有 前途 的 。 追逐 你 的 梦想 , 永不 放弃 。
问题输入:“现在”、“我”、“在”、“努力学习”、“英文”、“,”、“我”、“想”、“成为”、“一名”、“翻译”、“。”
回输出:“嗯”、“,”、“你”、“是”、“大有”、“前途”、“的”、“。”、“追逐”、“你”、“的”、“梦想”、“,”、“永不”、“放弃”、“。”
解释
当输入输出都是不定长序列时,我们可以使用编码器—解码器(encoder-decoder)[1] 或者 seq2seq 模型 [2]。这两个模型本质上都用到了两个循环神经网络,分别叫做编码器和解码器。编码器用来分析输入序列,解码器用来生成输出序列。在训练数据集中,我们可以在每个句子后附上特殊符号“
我们希望解码器在各个时间步能正确依次输出翻译后的问题单词、标点和特殊符号“
需要注意的是,解码器在最初时间步的输入用到了一个表示序列开始的特殊符号“
接下来我们分别介绍编码器和解码器的定义。
1.1 编码器
编码器的作用是把一个不定长的输入序列变换成一个定长的背景变量 c \boldsymbol{c} c,并在该背景变量中编码输入序列信息。常用的编码器是循环神经网络。
让我们考虑批量大小为 1 的时序数据样本。假设输入序列是 x 1 , … , x T x_1,\ldots,x_T x1,…,xT,例如 x i x_i xi 是输入句子中的第 i i i 个词。在时间步 t t t,循环神经网络将输入 x t x_t xt 的特征向量 x t \boldsymbol{x}_t xt 和上个时间步的隐藏状态 h t − 1 \boldsymbol{h}_{t-1} ht−1 变换为当前时间步的隐藏状态 h t \boldsymbol{h}_t ht。我们可以用函数 f f f 表达循环神经网络隐藏层的变换:
h t = f ( x t , h t − 1 ) . \boldsymbol{h}_t = f(\boldsymbol{x}_t, \boldsymbol{h}_{t-1}). ht=f(xt,ht−1).
接下来编码器通过自定义函数 q q q 将各个时间步的隐藏状态变换为背景变量
c = q ( h 1 , … , h T ) . \boldsymbol{c} = q(\boldsymbol{h}_1, \ldots, \boldsymbol{h}_T). c=q(h1,…,hT).
例如,当选择 q ( h 1 , … , h T ) = h T q(\boldsymbol{h}_1, \ldots, \boldsymbol{h}_T) = \boldsymbol{h}_T q(h1,…,hT)=hT 时,背景变量是输入序列最终时间步的隐藏状态 h T \boldsymbol{h}_T hT。以上描述的编码器是一个单向的循环神经网络,每个时间步的隐藏状态只取决于该时间步及之前的输入子序列。我们也可以使用双向循环神经网络构造编码器。这种情况下,编码器每个时间步的隐藏状态同时取决于该时间步之前和之后的子序列(包括当前时间步的输入),并编码了整个序列的信息。
1.2 解码器
刚刚已经介绍,编码器输出的背景变量 c \boldsymbol{c} c 编码了整个输入序列 x 1 , … , x T x_1, \ldots, x_T x1,…,xT 的信息。给定训练样本中的输出序列 y 1 , y 2 , … , y T ′ y_1, y_2, \ldots, y_{T'} y1,y2,…,yT′,对每个时间步 t ′ t' t′(符号与输入序列或编码器的时间步 t t t 有区别),解码器输出 y t ′ y_{t'} yt′ 的条件概率将基于之前的输出序列 y 1 , … , y t ′ − 1 y_1,\ldots,y_{t'-1} y1,…,yt′−1 和背景变量 c \boldsymbol{c} c,即 P ( y t ′ ∣ y 1 , … , y t ′ − 1 , c ) \mathbb{P}(y_{t'} \mid y_1, \ldots, y_{t'-1}, \boldsymbol{c}) P(yt′∣y1,…,yt′−1,c)。
为此,我们可以使用另一个循环神经网络作为解码器。在输出序列的时间步 t ′ t^\prime t′,解码器将上一时间步的输出 y t ′ − 1 y_{t^\prime-1} yt′−1 以及背景变量 c \boldsymbol{c} c 作为输入,并将它们与上一时间步的隐藏状态 s t ′ − 1 \boldsymbol{s}_{t^\prime-1} st′−1 变换为当前时间步的隐藏状态 s t ′ \boldsymbol{s}_{t^\prime} st′。因此,我们可以用函数 g g g 表达解码器隐藏层的变换:
s t ′ = g ( y t ′ − 1 , c , s t ′ − 1 ) . \boldsymbol{s}_{t^\prime} = g(y_{t^\prime-1}, \boldsymbol{c}, \boldsymbol{s}_{t^\prime-1}). st′=g(yt′−1,c,st′−1).
有了解码器的隐藏状态后,我们可以使用自定义的输出层和softmax运算来计算 P ( y t ′ ∣ y 1 , … , y t ′ − 1 , c ) \mathbb{P}(y_{t^\prime} \mid y_1, \ldots, y_{t^\prime-1}, \boldsymbol{c}) P(yt′∣y1,…,yt′−1,c),例如基于当前时间步的解码器隐藏状态 s t ′ \boldsymbol{s}_{t^\prime} st′、上一时间步的输出 y t ′ − 1 y_{t^\prime-1} yt′−1 以及背景变量 c \boldsymbol{c} c 来计算当前时间步输出 y t ′ y_{t^\prime} yt′ 的概率分布。
1.3 模型训练
根据最大似然估计,我们可以最大化输出序列基于输入序列的条件概率
P ( y 1 , … , y T ′ ∣ x 1 , … , x T ) = ∏ t ′ = 1 T ′ P ( y t ′ ∣ y 1 , … , y t ′ − 1 , x 1 , … , x T ) = ∏ t ′ = 1 T ′ P ( y t ′ ∣ y 1 , … , y t ′ − 1 , c ) , \begin{aligned} \mathbb{P}(y_1, \ldots, y_{T'} \mid x_1, \ldots, x_T) &= \prod_{t'=1}^{T'} \mathbb{P}(y_{t'} \mid y_1, \ldots, y_{t'-1}, x_1, \ldots, x_T)\\ &= \prod_{t'=1}^{T'} \mathbb{P}(y_{t'} \mid y_1, \ldots, y_{t'-1}, \boldsymbol{c}), \end{aligned} P(y1,…,yT′∣x1,…,xT)=t′=1∏T′P(yt′∣y1,…,yt′−1,x1,…,xT)=t′=1∏T′P(yt′∣y1,…,yt′−1,c),
并得到该输出序列的损失
− log P ( y 1 , … , y T ′ ∣ x 1 , … , x T ) = − ∑ t ′ = 1 T ′ log P ( y t ′ ∣ y 1 , … , y t ′ − 1 , c ) , - \log\mathbb{P}(y_1, \ldots, y_{T'} \mid x_1, \ldots, x_T) = -\sum_{t'=1}^{T'} \log \mathbb{P}(y_{t'} \mid y_1, \ldots, y_{t'-1}, \boldsymbol{c}), −logP(y1,…,yT′∣x1,…,xT)=−t′=1∑T′logP(yt′∣y1,…,yt′−1,c),
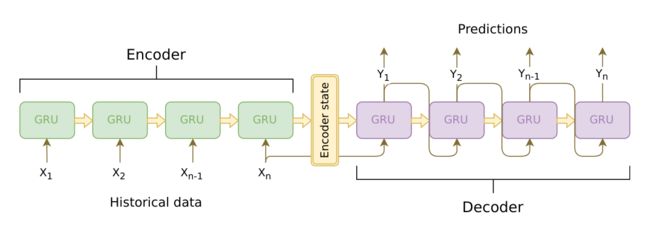
在模型训练中,所有输出序列损失的均值通常作为需要最小化的损失函数。入上图所描述的模型预测中,我们需要将解码器在上一个时间步的输出作为当前时间步的输入。与此不同,在训练中我们也可以将标签序列在上一个时间步的标签作为解码器在当前时间步的输入。这叫做强制教学(teacher forcing)。
1.4 参考文献
引用文本
[1] Cho, K., Van Merri ë nboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078.
[2] Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. In Advances in neural information processing systems (pp. 3104-3112).
2. 注意力机制(Attention)
注意力机制如下图所示:
2.1 注意力机制背景
在编码器—解码器(seq2seq)的应用中,机器翻译是最广为人知的应用。解码器在各个时间步依赖相同的背景变量来获取输入序列信息。当编码器为循环神经网络时,背景变量来自它最终时间步的隐藏状态。
以机器翻译为具体例子:输入为英语序列“They”、“are”、“watching”、“.”,输出为法语序列“Ils”、“regardent”、“.”。不难想到,解码器在生成输出序列中的每一个词时可能只需利用输入序列某一部分的信息。例如,在输出序列的时间步 1,解码器可以主要依赖“They”、“are”的信息来生成“Ils”,在时间步 2 则主要使用来自“watching”的编码信息生成“regardent”,最后在时间步 3 则直接映射句号“.”。这看上去就像是在解码器的每一时间步对输入序列中不同时间步的编码信息分配不同的注意力一样。这也是注意力机制的由来 。
仍然以循环神经网络为例,注意力机制通过对编码器所有时间步的隐藏状态做加权平均来得到背景变量。解码器在每一时间步调整这些权重,即注意力权重,从而能够在不同时间步分别关注输入序列中的不同部分并编码进相应时间步的背景变量。本节我们将讨论注意力机制是怎么工作的。
在“编码器—解码器(seq2seq)”上面的说明里我们区分了输入序列或编码器的索引 t t t 与输出序列或解码器的索引 t ′ t' t′ 。该节中,解码器在时间步 t ′ t' t′ 的隐藏状态 s t ′ = g ( y t ′ − 1 , c , s t ′ − 1 ) \boldsymbol{s}_{t'} = g(\boldsymbol{y}_{t'-1}, \boldsymbol{c}, \boldsymbol{s}_{t'-1}) st′=g(yt′−1,c,st′−1) ,其中 y t ′ − 1 \boldsymbol{y}_{t'-1} yt′−1 是上一时间步 t ′ − 1 t'-1 t′−1 的输出 y t ′ − 1 y_{t'-1} yt′−1 的特征表示,且任一时间步 t ′ t' t′ 使用相同的背景变量 c \boldsymbol{c} c 。但在注意力机制中,解码器的每一时间步将使用可变的背景变量。记 c t ′ \boldsymbol{c}_{t'} ct′ 是解码器在时间步 t ′ t' t′ 的背景变量,那么解码器在该时间步的隐藏状态可以改写为
s t ′ = g ( y t ′ − 1 , c t ′ , s t ′ − 1 ) . \boldsymbol{s}_{t'} = g(\boldsymbol{y}_{t'-1}, \boldsymbol{c}_{t'}, \boldsymbol{s}_{t'-1}). st′=g(yt′−1,ct′,st′−1).
这里的关键是如何计算背景变量 c t ′ \boldsymbol{c}_{t'} ct′ 和如何利用它来更新隐藏状态 s t ′ \boldsymbol{s}_{t'} st′ 。以下将分别描述这两个关键点。
2.2 计算背景变量
图2描绘了注意力机制如何为解码器在时间步 2 计算背景变量。首先,函数 a a a 根据解码器在时间步 1 的隐藏状态和编码器在各个时间步的隐藏状态计算softmax运算的输入。Softmax 运算输出概率分布并对编码器各个时间步的隐藏状态做加权平均,从而得到背景变量。
具体来说,令编码器在时间步 t t t 的隐藏状态为 h t \boldsymbol{h}_t ht ,且总时间步数为 T T T。那么解码器在时间步 t ′ t' t′ 的背景变量为所有编码器隐藏状态的加权平均:
c t ′ = ∑ t = 1 T α t ′ t h t , \boldsymbol{c}_{t'} = \sum_{t=1}^T \alpha_{t' t} \boldsymbol{h}_t, ct′=t=1∑Tαt′tht,
其中给定 t ′ t' t′ 时,权重 α t ′ t \alpha_{t' t} αt′t 在 t = 1 , … , T t=1,\ldots,T t=1,…,T 的值是一个概率分布。为了得到概率分布,我们可以使用softmax运算:
α t ′ t = exp ( e t ′ t ) ∑ k = 1 T exp ( e t ′ k ) , t = 1 , … , T . \alpha_{t' t} = \frac{\exp(e_{t' t})}{ \sum_{k=1}^T \exp(e_{t' k}) },\quad t=1,\ldots,T. αt′t=∑k=1Texp(et′k)exp(et′t),t=1,…,T.
现在,我们需要定义如何计算上式中softmax运算的输入 e t ′ t e_{t' t} et′t 。由于 e t ′ t e_{t' t} et′t 同时取决于解码器的时间步 t ′ t' t′ 和编码器的时间步 t t t ,我们不妨以解码器在时间步 t ′ − 1 t'-1 t′−1 的隐藏状态 s t ′ − 1 \boldsymbol{s}_{t' - 1} st′−1 与编码器在时间步 t t t 的隐藏状态 h t \boldsymbol{h}_t ht 为输入,并通过函数 a a a 计算 e t ′ t e_{t' t} et′t :
e t ′ t = a ( s t ′ − 1 , h t ) . e_{t' t} = a(\boldsymbol{s}_{t' - 1}, \boldsymbol{h}_t). et′t=a(st′−1,ht).
这里函数 a a a 有多种选择,如果两个输入向量长度相同,一个简单的选择是计算它们的内积 a ( s , h ) = s ⊤ h a(\boldsymbol{s}, \boldsymbol{h})=\boldsymbol{s}^\top \boldsymbol{h} a(s,h)=s⊤h 。而最早提出注意力机制的论文则将输入连结后通过含单隐藏层的多层感知机变换 :
a ( s , h ) = v ⊤ tanh ( W s s + W h h ) , a(\boldsymbol{s}, \boldsymbol{h}) = \boldsymbol{v}^\top \tanh(\boldsymbol{W}_s \boldsymbol{s} + \boldsymbol{W}_h \boldsymbol{h}), a(s,h)=v⊤tanh(Wss+Whh),
其中 v \boldsymbol{v} v 、 W s \boldsymbol{W}_s Ws 、 W h \boldsymbol{W}_h Wh 都是可以学习的模型参数。
// Attention Model
def attention_model(attention_size):
model = nn.Sequential()
model.add(nn.Dense(attention_size, activation='tanh', use_bias=False,
flatten=False),
nn.Dense(1, use_bias=False, flatten=False))
return model
def attention_forward(model, enc_states, dec_state):
# 将解码器隐藏状态广播到跟编码器隐藏状态形状相同后进行连结。广播的目的是将所有的向量进行结合
dec_states = nd.broadcast_axis(
dec_state.expand_dims(0), axis=0, size=enc_states.shape[0])
enc_and_dec_states = nd.concat(enc_states, dec_states, dim=2)
e = model(enc_and_dec_states) # 形状为(时间步数,批量大小,1)。
alpha = nd.softmax(e, axis=0) # 在时间步维度做 softmax 运算。
return (alpha * enc_states).sum(axis=0) # 返回背景变量。
seq_len, batch_size, num_hiddens = 10, 4, 8
model = attention_model(10)
model.initialize()
enc_states = nd.zeros((seq_len, batch_size, num_hiddens))
dec_state = nd.zeros((batch_size, num_hiddens))
attention_forward(model, enc_states, dec_state).shape
output:(4, 8)
2.3 矢量化计算
我们还可以对注意力机制采用更高效的矢量化计算。广义上,注意力机制模型的输入包括查询项以及一一对应的键项和值项。其中值项是需要加权平均的一组项。在加权平均中,值项的权重来自查询项以及与该值项对应的键项的计算。
在上面的例子中,查询项为解码器的隐藏状态,键项和值项均为编码器的隐藏状态。
让我们考虑一个常见的简单情形,即编码器和解码器的隐藏单元个数均为 h h h,且函数 a ( s , h ) = s ⊤ h a(\boldsymbol{s}, \boldsymbol{h})=\boldsymbol{s}^\top \boldsymbol{h} a(s,h)=s⊤h。假设我们希望根据解码器单个隐藏状态 s t ′ − 1 ∈ R h \boldsymbol{s}_{t' - 1} \in \mathbb{R}^{h} st′−1∈Rh 和编码器所有隐藏状态 h t ∈ R h , t = 1 , … , T \boldsymbol{h}_t \in \mathbb{R}^{h}, t = 1,\ldots,T ht∈Rh,t=1,…,T 计算背景向量 c t ′ ∈ R h \boldsymbol{c}_{t'}\in \mathbb{R}^{h} ct′∈Rh 。
我们可以将查询项矩阵 Q ∈ R 1 × h \boldsymbol{Q} \in \mathbb{R}^{1 \times h} Q∈R1×h 设为 s t ′ − 1 ⊤ \boldsymbol{s}_{t' - 1}^\top st′−1⊤ ,并令键项矩阵 K ∈ R T × h \boldsymbol{K} \in \mathbb{R}^{T \times h} K∈RT×h 和值项矩阵 V ∈ R T × h \boldsymbol{V} \in \mathbb{R}^{T \times h} V∈RT×h 相同且第 t t t 行均为 h t ⊤ \boldsymbol{h}_t^\top ht⊤。此时,我们只需要通过矢量化计算
softmax ( Q K ⊤ ) V \text{softmax}(\boldsymbol{Q}\boldsymbol{K}^\top)\boldsymbol{V} softmax(QK⊤)V
即可算出转置后的背景向量 c t ′ ⊤ \boldsymbol{c}_{t'}^\top ct′⊤。当查询项矩阵 Q \boldsymbol{Q} Q 的行数为 n n n 时,上式将得到 n n n 行的输出矩阵。输出矩阵与查询项矩阵在相同行上一一对应。
2.4 更新隐藏状态
以门控循环单元为例,在解码器中我们可以对门控循环单元的设计稍作修改 [1]。解码器在时间步 t ′ t' t′ 的隐藏状态为
s t ′ = z t ′ ⊙ s t ′ − 1 + ( 1 − z t ′ ) ⊙ s ~ t ′ , \boldsymbol{s}_{t'} = \boldsymbol{z}_{t'} \odot \boldsymbol{s}_{t'-1} + (1 - \boldsymbol{z}_{t'}) \odot \tilde{\boldsymbol{s}}_{t'}, st′=zt′⊙st′−1+(1−zt′)⊙s~t′,
其中的重置门、更新门和候选隐含状态分别为
r t ′ = σ ( W y r y t ′ − 1 + W s r s t ′ − 1 + W c r c t ′ + b r ) , z t ′ = σ ( W y z y t ′ − 1 + W s z s t ′ − 1 + W c z c t ′ + b z ) , s ~ t ′ = tanh ( W y s y t ′ − 1 + W s s ( s t ′ − 1 ⊙ r t ′ ) + W c s c t ′ + b s ) , \begin{aligned} \boldsymbol{r}_{t'} &= \sigma(\boldsymbol{W}_{yr} \boldsymbol{y}_{t'-1} + \boldsymbol{W}_{sr} \boldsymbol{s}_{t' - 1} + \boldsymbol{W}_{cr} \boldsymbol{c}_{t'} + \boldsymbol{b}_r),\\ \boldsymbol{z}_{t'} &= \sigma(\boldsymbol{W}_{yz} \boldsymbol{y}_{t'-1} + \boldsymbol{W}_{sz} \boldsymbol{s}_{t' - 1} + \boldsymbol{W}_{cz} \boldsymbol{c}_{t'} + \boldsymbol{b}_z),\\ \tilde{\boldsymbol{s}}_{t'} &= \text{tanh}(\boldsymbol{W}_{ys} \boldsymbol{y}_{t'-1} + \boldsymbol{W}_{ss} (\boldsymbol{s}_{t' - 1} \odot \boldsymbol{r}_{t'}) + \boldsymbol{W}_{cs} \boldsymbol{c}_{t'} + \boldsymbol{b}_s), \end{aligned} rt′zt′s~t′=σ(Wyryt′−1+Wsrst′−1+Wcrct′+br),=σ(Wyzyt′−1+Wszst′−1+Wczct′+bz),=tanh(Wysyt′−1+Wss(st′−1⊙rt′)+Wcsct′+bs),
其中含下标的 W \boldsymbol{W} W 和 b \boldsymbol{b} b 分别为门控循环单元的权重参数和偏差参数。
3. 小结
- 我们可以在解码器的每个时间步使用不同的背景变量,并对输入序列中不同时间步编码的信息分配不同的注意力。
- 广义上,注意力机制模型的输入包括查询项以及一一对应的键项和值项。
- 注意力机制可以采用更为高效的矢量化计算。
3.1 参考链接
[1]: Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.