PairedCycleGAN
PairedCycleGAN: Asymmetric Style Transfer for Applying and Removing Makeup
paper 的 motivation
提出了将素颜照人脸迁移到指定化妆style的美妆照,同时也能将美妆人脸进行卸妆。

创新点 贡献
1.有自己的数据集。通过在YouTube的美妆视频的前四分之一和后四分之一的时段进行 视频帧的采集,中间部分进行舍弃,因为中间部分大部分是在进行上妆的过程。然后进行人为的删除模糊的图片和脸部区域小于400*400的图片。
使用启发式算法对眼睛区域的颜色进行粗分类。然后外包给别人筛选数据集是否强烈的变化,删除闭眼和有遮挡的图片。最后得到了素颜照集合1148张和美妆照集合1044张。数据集包含各种各样的数据面部特征和化妆风格。
2.容易观察到眼部区域和嘴唇与皮肤的差别很大。对于生成网络分别训练了三个网络专注于眼睛部分、嘴唇、皮肤的生成。当给定一张素颜照和参考的美妆照时,先将人脸进行分割出眼睛、眉毛、嘴唇、鼻子、皮肤。设置一个圆,包含了眼睛、嘴唇等部分。然后将提取出来的一对人脸特征进行学习,每个网络只关注人脸的部分。最后将生成的部分进行Poisson blending。

主要思想
网络结构类似cyclegan的网络结构。分别训练了两个网络。G网络用于给人脸上美妆,F网络用于人脸卸妆。不同之处是G网络和F网络是非对称的。对于人脸美妆迁移,除了需要给定Source x x x还需要给定Reference y B y ^ { B } yB .而卸妆只需要给定美妆照片。
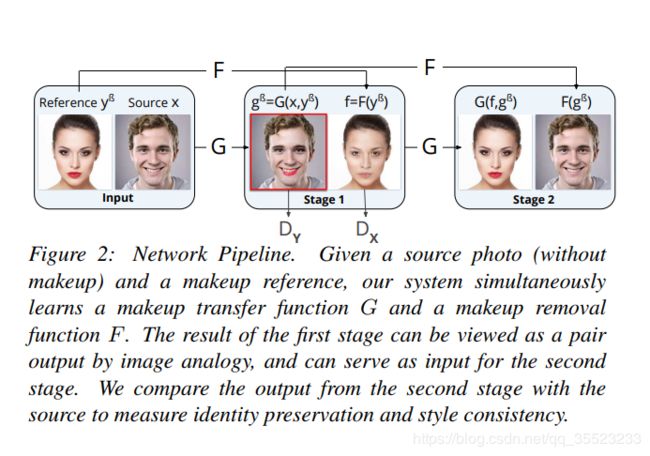
输入给出没有化妆的原图片和参考化妆图,同时学到一个上妆函数G和卸妆函数F。将第一阶段的输出当成第二阶段的输入,通过比较第二阶段的输出和原始输入来保证人脸信息不会丢失。
每个网络使用Dilated ResNet (DRN) architecture for the generators。

对于每个生成网络不是直接生成像素图片,而是输出一张 delta image,然后将delta image和原始素颜照相加得到最终输出图。这样做的好处是希望保存原始素颜照的皮肤颜色,和光照,只对化妆区域进行迁移。
作者的判别网络借鉴了pix2pix的结构,因为人脸需要观察到全局,所以输入时整张图片,没有采用 image patches 。
损失函数

Adversarial loss for G
更新G网络使生成的美妆照像真实的美妆照。
L G ( G , D Y ) = E y ∼ P Y [ log D Y ( y ) ] + E x ∼ P X , y ∼ P Y [ log ( 1 − D Y ( G ( x , y ) ) ) ] ( 1 ) \begin{aligned} L _ { G } \left( G , D _ { Y } \right) & = \mathbb { E } _ { y \sim \mathcal { P } _ { Y } } \left[ \log D _ { Y } ( y ) \right] \\ & + \mathbb { E } _ { x \sim \mathcal { P } _ { X } , y \sim \mathcal { P } _ { Y } } \left[ \log \left( 1 - D _ { Y } ( G ( x , y ) ) \right) \right] ( 1 ) \end{aligned} LG(G,DY)=Ey∼PY[logDY(y)]+Ex∼PX,y∼PY[log(1−DY(G(x,y)))](1)
Adversarial loss for F
更新F网络是生成的素颜照像真实的素颜照
L F ( F , D X ) = E x ∼ P X [ log D X ( x ) ] + E y β ∼ P Y [ log ( 1 − D X ( F ( y β ) ) ) ] (2) \begin{aligned} L _ { F } \left( F , D _ { X } \right) & = \mathbb { E } _ { x \sim \mathcal { P } _ { X } } \left[ \log D _ { X } ( x ) \right] \\ & + \mathbb { E } _ { y ^ { \beta } \sim \mathcal { P } _ { Y } } \left[ \log \left( 1 - D _ { X } \left( F \left( y ^ { \beta } \right) \right) \right) \right] \quad \text { (2) } \end{aligned} LF(F,DX)=Ex∼PX[logDX(x)]+Eyβ∼PY[log(1−DX(F(yβ)))] (2)
Identity loss.
Adversarial loss使输出的结果像美妆图,但是为了保存人脸的身份信息,将生成的美妆图使用F网络卸妆并和原始图计算L1loss。
L I ( G , F ) = E x ∼ P X , y β ∼ P Y [ ∥ F ( G ( x , y β ) ) − x ∥ 1 ] L _ { I } ( G , F ) = \mathbb { E } _ { x \sim \mathcal { P } _ { X } , y ^ { \beta } \sim \mathcal { P } _ { Y } } \left[ \left\| F \left( G \left( x , y ^ { \beta } \right) \right) - x \right\| _ { 1 } \right] LI(G,F)=Ex∼PX,yβ∼PY[∥∥F(G(x,yβ))−x∥∥1]
Style loss
L S ( G , F ) = E x ∼ P X , y β ∼ P Y [ ∥ G ( F ( y β ) , G ( x , y β ) ) − y β ∥ 1 ] L _ { S } ( G , F ) = \mathbb { E } _ { x \sim \mathcal { P } _ { X } , y ^ { \beta } \sim \mathcal { P } _ { Y } } \left[ \left\| G \left( F \left( y ^ { \beta } \right) , G \left( x , y ^ { \beta } \right) \right) - y ^ { \beta } \right\| _ { 1 } \right] LS(G,F)=Ex∼PX,yβ∼PY[∥∥G(F(yβ),G(x,yβ))−yβ∥∥1]
这里作者在像素上使用了L1损失,能够帮助生成脸部的结构和颜色,例如 眉毛的形状和眼影的渐变,但是会使得迁移过去的强烈的边界变得模糊,例如睫毛和眼线。因此作者加了一个辅助判别网络, D S D_S DS,用来判断输入的一对图片是否画着同样的妆容。所以 D S D_S DS需要输入生成的美妆照和ground-truth输入的素颜对应的美妆照,但是我们没有ground-truth。因此作者使用了一个合成的ground-truth。 W ( x , W(x, W(x,y) ,通过warping y化妆图去匹配到x脸部landmarks。
虽然通过warping得到的图像不能作为final result,但是将它作为正样本给 D S D_{S} DS网络,能让网络学会去判断是否画着同样的妆容。

Lp loss
L P ( G , D S ) = E x ∼ P X , y β ∼ P Y [ log D S ( y β , W ( x , y β ) ) ] + E x ∼ P X , y β ∼ P Y [ log ( 1 − D S ( y β , G ( x , y β ) ) ) ] \begin{aligned} L _ { P } \left( G , D _ { S } \right) & = \mathbb { E } _ { x \sim \mathcal { P } _ { X } , y ^ { \beta } \sim \mathcal { P } _ { Y } } \left[ \log D _ { S } \left( y ^ { \beta } , W \left( x , y ^ { \beta } \right) \right) \right] \\ & + \mathbb { E } _ { x \sim \mathcal { P } _ { X } , y ^ { \beta } \sim \mathcal { P } _ { Y } } \left[ \log \left( 1 - D _ { S } \left( y ^ { \beta } , G \left( x , y ^ { \beta } \right) \right) \right) \right] \end{aligned} LP(G,DS)=Ex∼PX,yβ∼PY[logDS(yβ,W(x,yβ))]+Ex∼PX,yβ∼PY[log(1−DS(yβ,G(x,yβ)))]
Total Loss
L = λ G L G + λ F L F + L I + L S + λ P L P L = \lambda _ { G } L _ { G } + \lambda _ { F } L _ { F } + L _ { I } + L _ { S } + \lambda _ { P } L _ { P } L=λGLG+λFLF+LI+LS+λPLP
缺陷

没有开源代码和数据集。