两个句子之间语义相似度项目
自然语言处理项目文档—内容相似度分析
1.项目内容:
本次项目提供一系列的英文句子对,每个句子对的两个句子,在语义上具有一定的相似性;每个句子对,获得一个在0-5之间的分值来衡量两个句子的语义相似性,打分越高说明两者的语义越相近。
项目提供数据为txt文件,字段之间以tab分割。
训练数据文件,共有1000个数据样本,共有4个字段;第一个字段为样本编号,第二个字段为一个句子,第三个字段为另一个句子,第四个字段为两个句子的语义相似度打分,如下:
10001 two bigbrown dogs running through the snow. A brown dog runningthrough the grass. 2.00000
10002 Awoman is peeling a potato. A woman is slicing a tomato. 1.33300
测试数据文件,共有500个数据样本,字段与训练集类似。
参考论文:
[1]:ECNU atSemEval-2017 Task 1: Leverage Kernel-based Traditional NLP features and NeuralNetworks to Build a Universal Model for Multilingual and Cross-lingual SemanticTextual Similarity[J]
[2]:Task-IndependentFeatures for Automated Essay Grading[J]
[3]:STS-UHHatSemEval-2017Task1: Scoring Semantic TextualSimilarity Using Supervised and Unsupervised Ensemble
2.预处理:
预处理包括两个部分,一个是句子长度的统计,一个是词频统计。这两种统计都是用了nltk库进行了去除stop word和Lemmatizer 处理。统计结束后将训练集分成了800个训练样本和200个验证样本
处理后的句子对,如10001样本:
two big browndogs running through the snow. A brown dog running through the grass
处理后为:
two big brown dog run snow brown dog run grass
训练集长度区间和词云

测试集长度区间和词云
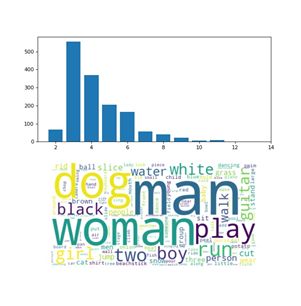
通过句子长度发现大多数语句长度小于12个单词,且大多集中在3个到4个之间由此在初期阶段推断这个相似度应该和词的关系特别大。 通过词频统计发现训练集和测试集的高频词其实差不多。也没有什么太多顾虑了。通过查询字典的方法查询了glove.840B.300d,发现总共有40个词不在这个范围里,仔细研究后发现这几个词是错词,但因为比例很小,也没有在意了。
3.基本思路:
我的模型按照下图展示主要由三部分组成:

传统NLP模型:
通过对每个sentence pair 分别提取匹配特征(即词之间的相关性)和语句特征(即单个句子表征形式)来构建一个相似度计算模型。这些特征都将输入到最后的回归模型中,加以拟合得到我们的最终预测。
深度学习模型:
通过将sentencepair表征为Glove词向量的形式,然后输入到end-to-end的网络中,我计算出最后语句的相似度。
Ensemble模型:
用来求随机森林、GBDT和xgboost模块的平均来得到最后的score,采用了uniform和linear emsemble两种模式。(这里本来想将lstm神经网络加入emsemble中,但是由于该模型效果很差,将其踢出,后面章节会提及。)
下面将具体展示各个特征的意义。
3.1 传统NLP模型
3.1.1 匹配特征
我采用了五种sentence pair 匹配特征来直接计算两个句子之间的相似度。
N-gramOverlap:
我用Si来表示n-grams提取语句后后的集合,它的值通过下式定义:

在这里我对去除了stopwords的文本先进行了word之间n={1,2,3,4}的提取重复部分,但是发现句子长短不一,有的句子只有2个词,这样无法计算3-grams和4-grams的重复部分,所以最后然后针对句子中的字母进行了gram提取,最后我们获得了4个features。
SequenceFeatures(序列特征)
序列特征是另一种捕捉语句内部信息的方法,它通过计算词性标注后语句的最大公共子字符串的长度来计算语句间的相似度。我先求取两个语句的POStags,然后再用公共子字符串的长度除以两个句子的总tags长度。最后我们得到了2个features。
TopicFeatures
为了衡量语句间的相似性,我采用了Latent Dirichlet Allocation (LDA)模型。这里我们简单的设置了topic的数量为6,对训练数据和测试数据进行了转化,得到6个特征。
Syntatic Feature
除了直接从结构化的句子词性list中直接求解公共子字符,我还采用了树形结构的词性分析,通过计算在树形结构下的最大subpath,我获取了一1个特征,此处词性树形结构的获取采用的是nltk库中的tagger函数。
MT based Feature
BLEU方法为机器翻译的评测方法之一,通常利用n-gram的方法计算两个文本之间的相似程度。

其中BP为惩罚因子,针对两个文本相差长度较大有作用,这里n取值为4。
最后我收集了8个sentence pair的特征。
3.1.2
这里我通过直接向量化每个句子,然后再通过向量之间的计算来获得句子之间的相似度分析。
BOW Features
我将每句话都用Bag-of-Word方式转成向量,并用tf-idf进行加权处理。
Word Embedding Features
Word embedding 是一种将词转换成向量的方法。尝试过直接使用测试集,训练集语料训练wordvec模型,但因为数据量小,且是短文本,因而效果极差。后面使用了glove的预训练模型,预训练的模型语料是glove.840B.300d
虽然这些特征能够很好地表征出语句的信息,尤其是对于语句间的相对关系方面,word2vec 一直是佼佼者。但是我也可以发现glove的维数都达到了300,这是我所不能接受的,毕竟前面的提取一共才8个!这与之前提取的特征相比不公平!所以我们通过采用核函数(kernel function)来对句中所有的词向量做一个整合,将它们从高维向低维转化。最后我们cosine distance、word mover distance、IDF加权和调和平均等方法,得到了3个特征。
Unsupervied Score Features
无监督方法主要的计算公式为:

其中,S1,S2指两个句子,wi表示存在于两个句子中的所有词,wj为当前wi所处的句子的另一句中存在的词。match函数表达如下:

词向量使用glove.840B.300d向量,对于未出现的词,赋值为300维均为1的向量。
无监督方法得到的相关系数为0.72,效果不好所以把他加入到特征组合输入进模型中。
3.1.3回归算法
我一共使用了四种回归模型来预测最后的score:SVR,RandomForests(RF),GradientBoosting(GB) 和 XGBoost(XGB)。前面三种都是采用scikit-learn中实现,而XGB是采用xgboost中实现。通过一段时间的实验,由于SVR表现的效果不佳,最终被黯然离场。
3.2 深度学习模型
神经网络方法主要由lstm融合,最后效果不是特别好,最好记录只有0.6的验证集成绩,应该是参数没调整正确,估计是训练集样本量太小,就没有怎么尝试了。用的损失函数为均方误差,优化器为先使用adam ,后使用sgd,但均无比较好的效果。
神经网络结构图如下,词向量,embedding层采用glove.840B.300d.

神经网络方法得到如下的结果图
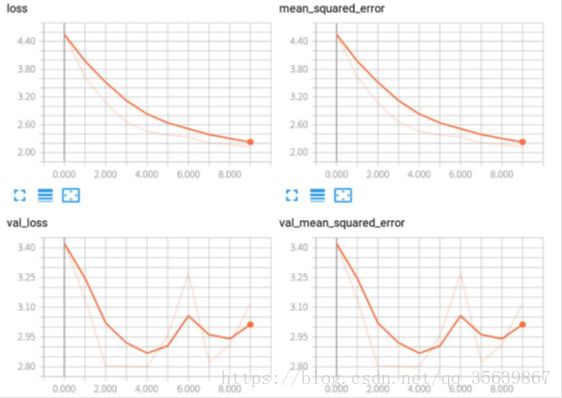
神经网络实验图如图有4组,分别为训练集loss,训练集方差值,验证集loss,验证集方差值。很明显验证集的loss都开始往上走了训练集还没有到达一个较好的点,所以也没使用测试集进行测试。后期对神经网络主要是调这里的参数,数据量小,很容易达到拟合,也很容易过拟合。
3.3Ensemble 模型
由于在最后的评估中,深度学习模型下的score表现较差,所有最后的ensemble中我没有给它的socre赋权重,当前的结果都是基于传统NLP的score。
4实验过程及相关结果
4.1验证标准
采用sklearn中的mean_squared_error函数和scipy 中的pearsonr函数作为我验证的标准。
4.2特征表现
下面我首先对特征集中每一个维度的特征进行单独打分,验证出单个特征对于模型分类的贡献程度,评分标准为 均方差和pearsonr系数:
algorithm |
MSE |
pea |
RF |
0.791437677422 |
0.831331526812 |
GBDT |
0.841775448927 |
0.820219618878 |
Xgboost |
0.832667237473 |
0.821753213223 |
RF+GBDT+Xgboost+uniform |
0.786825574391 |
0.837655422786 |
RF+GBDT+Xgboost+linear |
0.765844358731 |
0.843443157591 |
在此处Random Forest表现出了单个算法最为优异的性能, Ensemble算法可以稍微提高一点相关系数,其中一个模型一票的uniform提高较少,而把3个算法的结果输入到线性模型上的Ensemble可以提高0.012,但是线性模型中GBDT的权重为负数,并不好解释,所以不考虑使用。