前言
因近期要做 hadoop 有关的项目,需配置 hadoop 环境,简单起见就准备进行单机部署,方便开发调试。顺便记录下采坑步骤,方便碰到同样问题的朋友们。
安装步骤
一、下载 hadoop-XXX.tar.gz
下载地址:http://archive.apache.org/dist/hadoop/core/
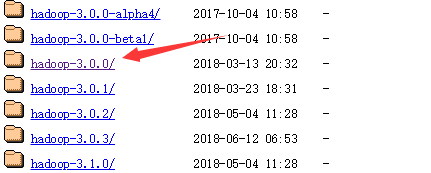
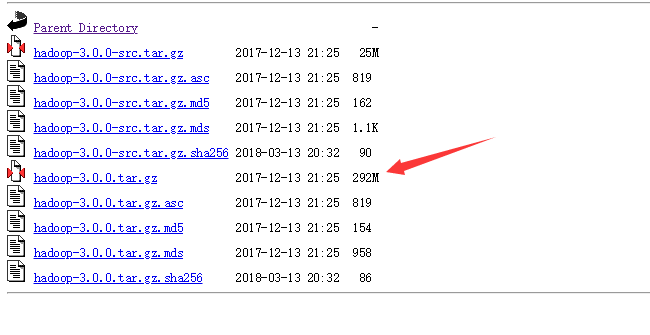
将文件解压至无空格目录下,好像时间有那么点点久。。。。。
注:解压需管理员权限!!!
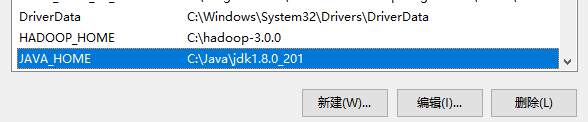
添加环境变量
添加HADOOP_HOME配置

在 path 中添加 bin 目录 C:\hadoop-3.0.0\bin
JAVA_HOME
二、hadoop配置
1、修改C:/hadoop-3.0.0/etc/hadoop/core-site.xml配置:
fs.default.name
hdfs://localhost:9000
hadoop.tmp.dir
/C:/hadoop-3.0.0/data/tmp
2、修改C:/hadoop-3.0.0/etc/hadoop/mapred-site.xml配置:
mapreduce.framework.name yarn
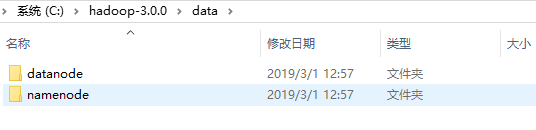
3、在C:/hadoop-3.0.0目录下创建data目录,作为数据存储路径:
- 在D:/hadoop-3.0.0/data目录下创建datanode目录;
- 在D:/hadoop-3.0.0/data目录下创建namenode目录;
4、修改C:/hadoop-3.0.0/etc/hadoop/hdfs-site.xml配置:
dfs.replication 1 dfs.permissions false dfs.namenode.name.dir /C:/hadoop-3.0.0/data/namenode fs.checkpoint.dir /C:/hadoop-3.0.0/data/snn fs.checkpoint.edits.dir /C:/hadoop-3.0.0/data/snn dfs.datanode.data.dir /C:/hadoop-3.0.0/data/datanode
5、修改C:/hadoop-3.0.0/etc/hadoop/yarn-site.xml配置:
yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.auxservices.mapreduce.shuffle.class org.apache.hadoop.mapred.ShuffleHandler
6、修改C:/hadoop-3.0.0/etc/hadoop/hadoop-env.cmd配置,添加
set JAVA_HOME=%JAVA_HOME%
set HADOOP_PREFIX=%HADOOP_HOME% set HADOOP_CONF_DIR=%HADOOP_PREFIX%\etc\hadoop set YARN_CONF_DIR=%HADOOP_CONF_DIR% set PATH=%PATH%;%HADOOP_PREFIX%\bin
7、bin目录替换
至https://github.com/steveloughran/winutils下载解压,然后找到对应的版本后完整替换bin目录即可
至此,我们的配置就完成了
三、启动服务
1、打开cmd
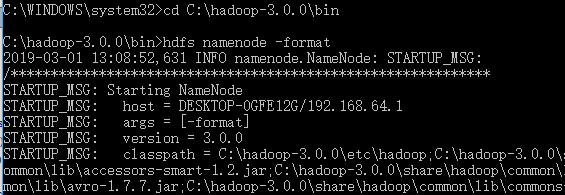
cd C:\hadoop-3.0.0\bin hdfs namenode -format
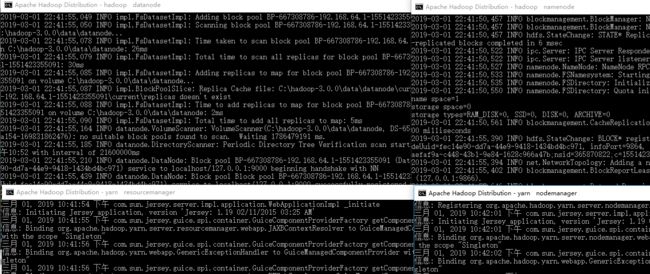
2、通过start-all.cmd启动服务:
C:\hadoop-3.0.0\sbin\start-all.cmd
然后可以看到同时打开了4个cmd窗口
- Hadoop Namenode
- Hadoop datanode
- YARN Resourc Manager
- YARN Node Manager
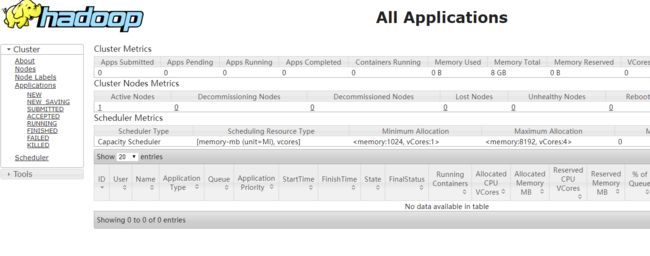
通过http://127.0.0.1:8088/即可查看集群所有节点状态:
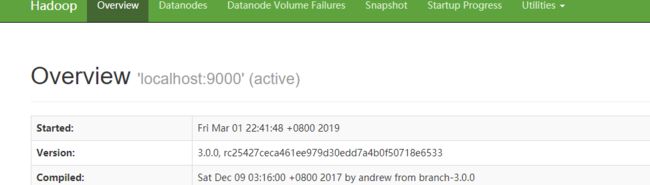
 访问http://localhost:9870/即可查看文件管理页面:
访问http://localhost:9870/即可查看文件管理页面:
总结
一次还算比较顺利的采坑,后面准备开始肝项目了 orz。。。