sklearn包中决策树算法的使用
资料链接:https://scikit-learn.org/dev/modules/tree.html
决策树Decision Trees是一种用于分类和回归( classification and regression)的无监督学习方法。目标是创建一个模型,从数据特征中学习简单的决策规则来预测目标变量的值。
例如,在下面的示例中,决策树通过if-then-else的决策规则来学习数据从而估测到一个正弦曲线。树越深,决策规则越复杂,模型对数据的拟合效果就越好。

关于决策树的一些优点:
- 便于理解和解释。树可以可视化。
- 训练需要的数据少,其他的模型方法通常需要数据规范化 ,比如创建虚拟变量并且删除缺失值(注意,这个模型不支持缺失值)。
- 训练模型的时间复杂度是参与训练数据点的对数值(训练决策树的数据点的数据量导致了)。
- 使用白盒模型。如果某种给定的情况在模型中是可以观测的,那么就可以通过布尔逻辑解释这种情况。相比之下,在黑盒模型中(比如,人的神经网络)的结果就难以解释。
- 可以用数值统计测试来验证模型。使解释验证该模型的可靠性成为可能。
- 即使该模型假设的结果与真实模型所提供的数据有出入,但模型的效果仍旧很好。
决策树的一些缺点:
- 容易过拟合
- 决策树可能不稳定,数据中微小的变化都可能导致生成完全不同的树。在集成中使用决策树可以缓解这个问题。
- 学习最优决策树的问题通常是一个NP难问题。因此,实际的决策树学习算法是基于启发式算法。
- 有些概念难以学习,决策树不容易表达。例如XOR,奇偶或者复用器的问题
分类
与其他分类器一样, DecisionTreeClassifier将两个数组作为输入:一个数组X,用[n_samples, n_features]存放训练样本;Y数组用[n_samples]来存放训练样本的类标签。
#导入sklearn包
>>> from sklearn import tree
>>> X = [[0, 0], [1, 1]]
>>> Y = [0, 1]
>>> clf = tree.DecisionTreeClassifier()
>>> clf = clf.fit(X, Y)
接下来,模型可以预测样本的类别。
>>> clf.predict([[2., 2.]])
array([1])或者,可以预测每个类的概率,这个概率是叶子中同类训练样本的比例.predict_proba返回的是一个 n 行 k 列的数组, 第 i 行 第 j 列上的数值是模型预测 第 i 个预测样本为某个标签的概率,并且每一行的概率和为1。
>>> clf.predict_proba([[2., 2.]])
array([[0., 1.]])所以结果表示预测[2.,2.]的标签是0的概率是0,是1的概率是1。
DecisionTreeClassifier既支持二分类(其标签为[-1,1]),也支持多分类([0, …, K-1])。
利用Iris数据集,我们可以构建如下树:
>>> from sklearn.datasets import load_iris
>>> from sklearn import tree
>>> X, y = load_iris(return_X_y=True)
>>> clf = tree.DecisionTreeClassifier()
>>> clf = clf.fit(X, y)一旦经过训练,可以用plot_tree 函数绘制树,也可以通过graphviz将树可视化。首先要安装一下这个包,如果用conda管理包可以用指令 conda install python-graphviz安装,我是先用系统安装了一下再用python安装。指令:brew install graphviz // pip3 install graphviz
>>> import graphviz
>>> dot_data = tree.export_graphviz(clf, out_file=None)
>>> graph = graphviz.Source(dot_data)
>>> graph.render("iris")这样就已经生成一个pdf文件
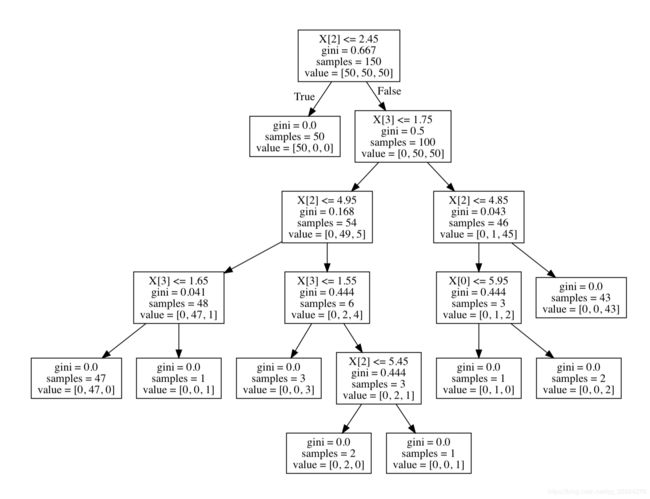
export_graphviz也支持各种美化图形。加入各种参数
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True)
graph=graphviz.Source(dot_data)
graph.render("iris")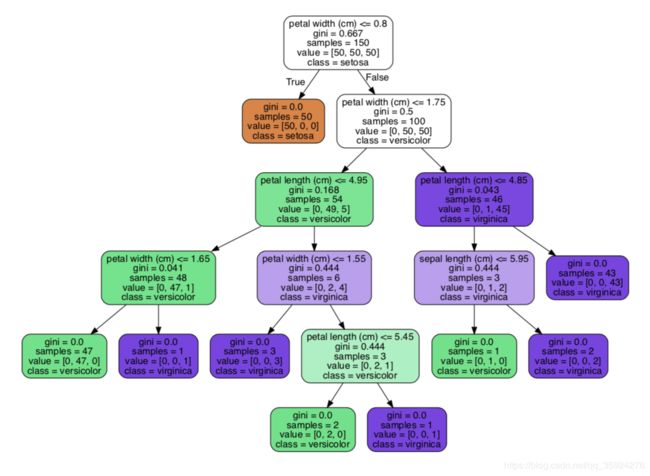
接下来的示例用的是iris数据集。Iris 鸢尾花数据集是一个经典数据集,在统计学习和机器学习领域都经常被用作示例。数据集内包含 3 类(Iris Setosa,Iris Versicolour,Iris Virginica)共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于哪一品种。
基于iris数据集绘制决策树
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
# Parameters
n_classes = 3
plot_colors = "ryb"
plot_step = 0.02
# Load data
iris = load_iris()
for pairidx, pair in enumerate([[0, 1], [0, 2], [0, 3],
[1, 2], [1, 3], [2, 3]]):
# We only take the two corresponding features
#从四列数据中选取两个特征进行训练
X = iris.data[:, pair]
y = iris.target
# Train
clf = DecisionTreeClassifier().fit(X, y)
# Plot the decision boundary
plt.subplot(2, 3, pairidx + 1)
#subplot直接指定划分方式和位置进行绘图,2行3列排列图片
#绘制决策边界,选择最大值,最小值
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
# numpy.meshgrid()——生成网格点坐标矩阵。numpy.arange()分割数
xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),
np.arange(y_min, y_max, plot_step))
# tight_layout() 进行自动控制图像布局,通过参数pad, w_pad, h_pad设置布局细节
plt.tight_layout(h_pad=0.5, w_pad=0.5, pad=2.5)
# 按照第一个循环,把第一列花萼长度数据按h取等分,作为行,然后复制多行,得到xx网格矩阵
#把第二列的花萼宽度数据按h取等分,作为列,复制多列,得到网格矩阵
#np.c_是按列连接两个矩阵,就是把两矩阵左右相加,要求行数相等,类似于pandas中的merge()
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
#绘制等高线的,contour和contourf都是画三维等高线图的
#不同点在于contour() 是绘制轮廓线,contourf()会填充轮廓。
#matplotlib.cm是色彩映射函数。
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.RdYlBu)
#横纵坐标label特征名称
plt.xlabel(iris.feature_names[pair[0]])
plt.ylabel(iris.feature_names[pair[1]])
# Plot the training points 绘制每个类别的鸢尾花数据的散点图
for i, color in zip(range(n_classes), plot_colors):
# 这里的numpy.where()只有一个参数,返回条件为True的索引
#所以这里会依次返回每种鸢尾花的样本索引。
idx = np.where(y == i)
#取出样本的第0列,第1列
plt.scatter(X[idx, 0], X[idx, 1], c=color, label=iris.target_names[i],
cmap=plt.cm.RdYlBu, edgecolor='black', s=15)
plt.suptitle("Decision surface of a decision tree using paired features")
plt.legend(loc='lower right', borderpad=0, handletextpad=0)
plt.axis("tight")
plt.figure()
clf = DecisionTreeClassifier().fit(iris.data, iris.target)
plot_tree(clf, filled=True)
plt.show()得到两个图

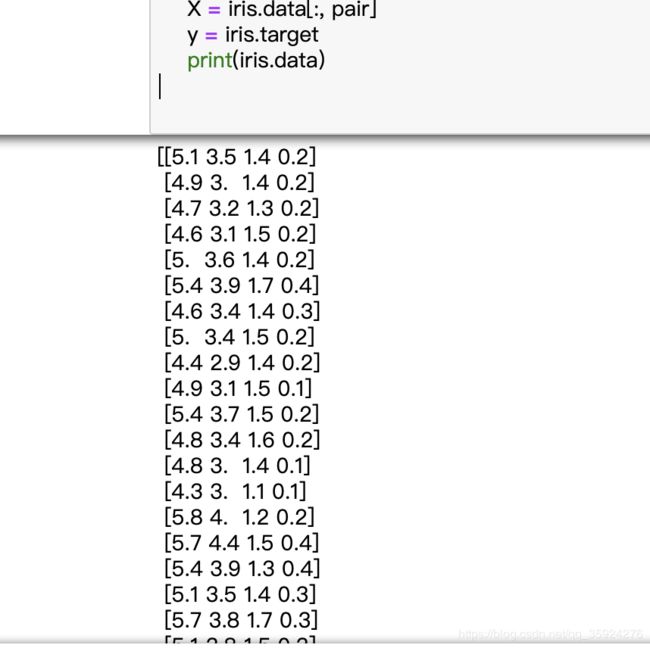
上述代码中其中,iris.data数据如下
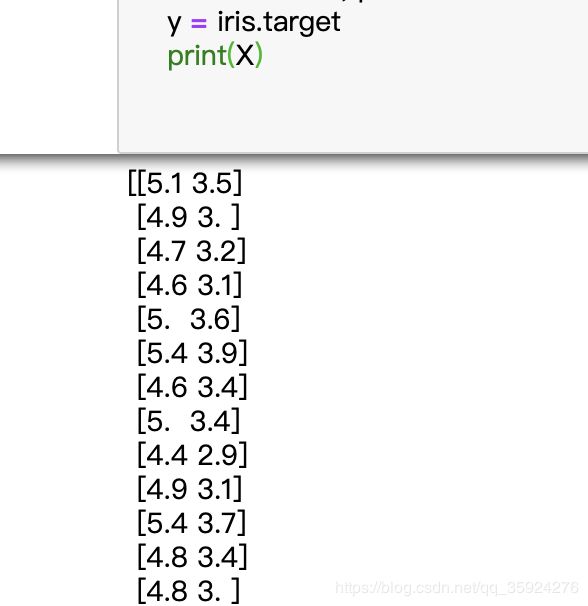
此时X= iris.data[:,pair],第一个循环中取iris.data数据中的第0列和第1列即iris.data[: , [0,1] ]
代码中numpy.where(condition[,x,y])
| 参数: | condition : 数组,bool值 如果为True, 则产生 x, 否则产生 y. x, y : array_like, 可选 x与y的shape要相同,当condition中的值是true时返回x对应位置的值,false是返回y的 |
|---|---|
| 返回值: | out : ndarray 或ndarray 原组 ①如果参数有condition,x和y,它们三个参数的shape是相同的。那么,当condition中的值是true时返回x对应位置的值,false是返回y的。 ②如果参数只有condition的话,返回值是condition中元素值为true的位置索引,切是以元组形式返回,元组的元素是ndarray数组,表示位置的索引 |