tensorflow高阶API——Estimator
tensorflow在DL社区火热,无论写个什么算法都要搞在tensorflow上面。我喜欢tensorflow的两个地方,一是分布式方便,二是跑GPU方便,然而tensorflow终究是个科学计算库,要在上面进行算法的研发和工程化,还是有点儿裸奔的感觉。
所以,我选择Estimator。
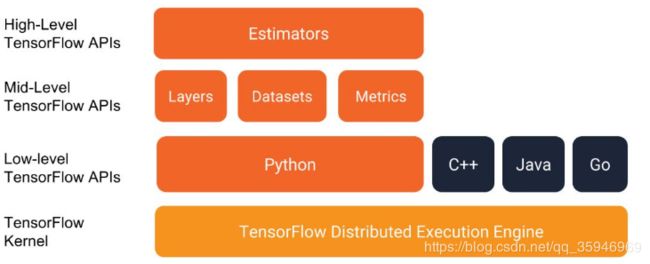
这是某tensorflow内部大佬公开演讲时拿出来的一个架构图,最底层一个分布式tensorflow引擎(选择操作系统的时候,听官方的话,win、mac、unbuntu,用其他的坑实在太多了),然后上面几种语言基础API(语言接口),在上面一些中级API(可以作为搭建网络的辅助),最上面一个Estimators(这里的Estimators就是model)。
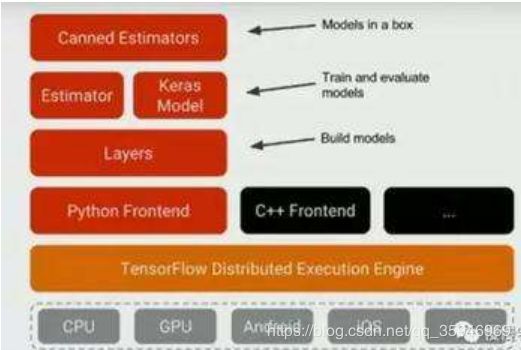
这个图是上面图后来的一次升级(比较模糊,只看最上面两层),在Estimator这一层已经多了Keras,Keras已经融合到了tensorflow里面,作为一个高阶的API。最重要的是顶层的这个东西Canned Estimators(简单理解,就是做了产业链一条龙服务,原先我们做好了一个model,嵌入业务怎么写代码,单机还是分布式怎么写代码等等问题都需要考虑,但是这个Canned Estimators能够做到——研发写好的东西直接交给业务部门,拿来就能用)
已经了解了tensorflow的大体面貌,接下来,回到主题:
1、tensorflow的高阶API——Estimator这个东西怎么用
我们知道Estimator就是model,那么这个model是需要自己写的?还是它里面直接提供了一些子类model(lr、knn之类)可以直接拿来train、predict?
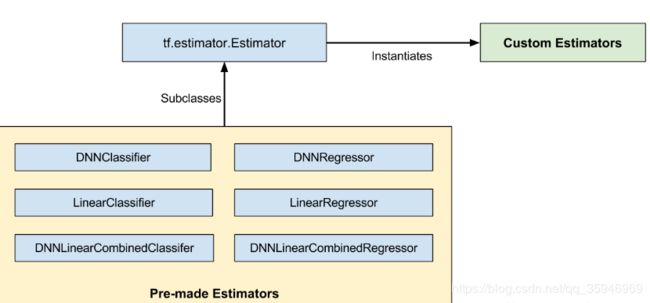
这张图告诉我们,都行。estimator自带一些model,我们可以直接用,只需要自己设置参数。
一般而言,我们会自己根据业务实现算法,这个时候,就需要自定义estimator了。
2、如何自定义estimator?
estimator的init function如下:

model_fn时一个规范了输入参数和返回结果的函数(即我们的算法逻辑)。
params就是算法中需要的超参数,这里给一个字典,算法运行时estimator会将这个params传递给我们的model_fn。
model_dir是model保存的路径,断点续传这个东西,想想就有点儿意思。
定义好一个estimator之后,就可以使用estimator的train、、evalute、predict等方法,这里使用数据的时候涉及到tensorflow的dataset这个对象。
dataset这个东西是一种对原始数据的封装,可以对这个数据集进行map、设置echo、设置batch_size等操作,使用起来也是比较简单的,熟悉一下就好。
https://tensorflow.google.cn/api_docs/python/tf/data/Dataset
Estimator这里的重点应当是model_fn。
3、model_fn(EstimatorSpec)
def model_fn(features, labels, mode, params):
输入参数:如上,model_fn的输入以此为features,labels,mode(tf.estimator.ModeKeys.TRAIN,这里其实只有train、evalute、predict,只是用来确定当前是哪种模式,config),params.
返回值:model_fn的返回值要求 是一个EstimatorSpec类型的对象,这又是个什么东西?看一下它要什么就大概清楚了:

在这一堆参数里面,一般需要用的有这个几个:

mode已经解释了。
predictions是模型的预测值。
eval_metric_ops 是auc、acc之类的预测指标以及预测值的字典。
train_op 是优化函数。
大概就是这样,定义好Estimator,接下来要做的就是train、evalute、predict,笔者对这里的API暂时还不是特别清楚,下次再写。