CNN图像分类(实际项目,特殊训练集,95%准确率,数据代码百度云)
最近基于VGG-16缩进了网络做了一个CNN模型用于处理图像分类,实际项目,训练对象是448×32的长条试纸图片。
目录
项目源码百度云
tensorboard可视化展示
源代码
项目源码百度云
项目源码百度云链接:https://pan.baidu.com/s/1aWLeh4Kaft7NPlB0GxBZMg
提取码:vjhu
里面项目名字没改,VGG16因为是改造的,名字也没好好取,能用就行。。

| model | 储存模型文件,为了方便下载,已经删除了,可以自己训练 |
| logs | 存放日志文件,已经删除,本文后续有图片展示tensorboard日志 |
| data | 数据文件格式如上右图,test1和train2为原始图片,test和train为处理后图片,统一为448×32大小,用于网络训练。每个下有lh1、lh2等为类别,每个类别下分别存放了图片 注:test/lh1,test1/lh1,train/lh1,train2/lh1下各有一张图片供参考,数据就不大量泄漏了,其余文件为空 |
| VGG16_RAW.py | VGG16模型源文件 |
| VGG16_mini2.py | 改造的小型CNN模型,训练出来模型大概7M左右 |
| tf009_predition.py | 预测文件 |
| tf009.py | 训练文件 |
| image_pre_deal.py | 图像预处理文件,将原始图片转为统一大小格式的图片 |
| calculate_mean.py | 计算图片平均值的文件,用于后续减均值处理 |
tensorboard可视化展示
tensorboard:(不要在意波折的细节,只要看清准确率,损失值数值就行了,采用的Mini-batch的迭代方式,这次训练有点乱)

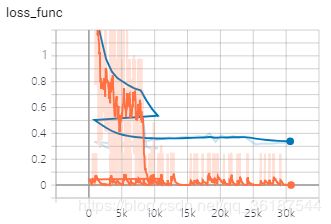
模型:

源代码
tf009.py源码,训练主文件:(写的迁移学习不要介意,懒得改了。。)
'''
VGG16迁移学习训练主函数
tensorboard --logdir=D:\python\vgg16\logs
'''
import tensorflow as tf
import os
os.environ["CUDA_VISIBLE_DEVICES"]="-1" # 由于出现显卡内存不足问题,所以。。。
import numpy as np
from time import time
import vgg16.VGG16_mini2 as model
def get_batch(image_list,label_list,img_width,img_height,batch_size,capacity):#通过读取列表来载入批量图片及标签
image = tf.cast(image_list,tf.string)
label = tf.cast(label_list,tf.int32)
input_queue = tf.train.slice_input_producer([image,label],shuffle=True)
label = input_queue[1]
image_contents = tf.read_file(input_queue[0])
image = tf.image.decode_jpeg(image_contents,channels=3)
image = tf.cast(image,tf.float32)
image -= [42.79902,42.79902,42.79902] # 减均值
# image = preprocess_for_train(image,img_height,img_width)
image.set_shape((img_height,img_width,3))
image_batch,label_batch = tf.train.batch([image,label],batch_size=batch_size,num_threads=64,capacity=capacity)
label_batch = tf.reshape(label_batch,[batch_size])
return image_batch,label_batch
def get_file(file_dir):
images = []
for root,sub_folders,files in os.walk(file_dir):
for name in files:
images.append(os.path.join(root,name))
labels = []
for label_name in images:
letter = label_name.split("\\")[-2]
if letter =="lh1":labels.append(0)
elif letter =="lh2":labels.append(1)
elif letter == "lh3":labels.append(2)
elif letter == "lh4":labels.append(3)
elif letter == "lh5":labels.append(4)
elif letter == "lh6":labels.append(5)
elif letter == "lh7":
labels.append(6)
print("check for get_file:",images[0],"label is ",labels[0])
#shuffle
temp = np.array([images,labels])
temp = temp.transpose()
np.random.shuffle(temp)
image_list = list(temp[:,0])
label_list = list(temp[:,1])
label_list = [int(float(i)) for i in label_list]
return image_list,label_list
#标签格式重构
def onehot(labels):
n_sample = len(labels)
n_class = 7 # max(labels) + 1
onehot_labels = np.zeros((n_sample,n_class))
onehot_labels[np.arange(n_sample),labels] = 1
return onehot_labels
if __name__ == '__main__':
startTime =time()
batch_size = 8
record_epoch = 70000/batch_size
small_loop = int(7000/batch_size)
capacity = 256 # 内存中存储的最大数据容量
pic_height,pic_width = 32,448 # 修改图片大小参数,应当为32的倍数!不然会导致错误
xs,ys = get_file('./data/train')#获取图像列表与标签列表
image_batch,label_batch = get_batch(xs,ys,img_width=pic_width,img_height=pic_height,batch_size=batch_size,capacity=capacity)
# 验证集
xs_val,ys_val = get_file('./data/test')#获取图像列表与标签列表
image_val_batch,label_val_batch = get_batch(xs_val,ys_val,img_width=pic_width,img_height=pic_height,batch_size=455,capacity=capacity)
x = tf.placeholder(tf.float32,[None,pic_height,pic_width,3])
y = tf.placeholder(tf.int32,[None,7])#7分类
vgg = model.vgg16(x)
fc8_fineuining = vgg.probs #即softmax(fc8)
prediction_out = tf.argmax(fc8_fineuining,1)
real_out = tf.argmax(y,1)
correct_prediction = tf.equal(prediction_out,real_out)#检查预测类与实际类别是否匹配
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))#准确率
loss_function = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=fc8_fineuining,labels=y))#损失函数
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.001).minimize(loss_function)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# vgg.load_weights('vgg16_weights.npz',sess)
saver = tf.train.Saver()
# # 断点续训
# ckpt_dir = "./model/"
# ckpt = tf.train.latest_checkpoint(ckpt_dir)
# if ckpt != None:
# saver.restore(sess, ckpt)
# print('saver restore finish')
# else:
# print("training from scratch")
#启动线程
coord = tf.train.Coordinator()#使用协调器管理线程
threads = tf.train.start_queue_runners(coord=coord,sess=sess)
# 日志记录
summary_writer = tf.summary.FileWriter('./logs/', graph=sess.graph, flush_secs=15)
summary_writer2 = tf.summary.FileWriter('./logs/plot2/', flush_secs=15)
tf.summary.scalar(name='loss_func', tensor=loss_function)
tf.summary.scalar(name='accuracy', tensor=accuracy)
merged_summary_op = tf.summary.merge_all()
epoch_start_time = time()
# 采用Mini-batch迭代
step = 0
epoch = 10000
for i in range(epoch):
for j in range(small_loop):
images,labels = sess.run([image_batch,label_batch])
labels = onehot(labels)
# # 可视化
# plt.subplot(221)
# plt.imshow(images[0, :, :, 0])
# plt.show()
# print(1)
sess.run(optimizer,feed_dict={x:images,y:labels})
merged_summary,loss,real_train_out = sess.run([merged_summary_op,loss_function,real_out],feed_dict={x:images,y:labels})
summary_writer.add_summary(merged_summary, global_step=step)
# print(i,j,"to see train data:",real_train_out[:10])
step += 1
images_val, labels_val = sess.run([image_val_batch, label_val_batch])
labels_val = onehot(labels_val)
merged_summary_val, loss_val,accuracy_val,prediction_val_out,real_val_out = sess.run([merged_summary_op, loss_function,accuracy,prediction_out,real_out], feed_dict={x: images_val, y: labels_val})
summary_writer2.add_summary(merged_summary_val, global_step=step)
# 输出每个类别正确率
lh1_right, lh2_right, lh3_right, lh4_right, lh5_right, lh6_right, lh7_right = 0, 0, 0, 0, 0, 0, 0
lh1_wrong, lh2_wrong, lh3_wrong, lh4_wrong, lh5_wrong, lh6_wrong, lh7_wrong = 0, 0, 0, 0, 0, 0, 0
for ii in range(len(prediction_val_out)):
if prediction_val_out[ii] == real_val_out[ii]:
if real_val_out[ii] == 0:lh1_right+=1
elif real_val_out[ii] == 1:lh2_right+=1
elif real_val_out[ii] == 2:lh3_right += 1
elif real_val_out[ii] == 3:lh4_right += 1
elif real_val_out[ii] == 4:lh5_right += 1
elif real_val_out[ii] == 5:lh6_right += 1
elif real_val_out[ii] == 6:lh7_right += 1
else:
if real_val_out[ii] == 0:lh1_wrong+=1
elif real_val_out[ii] == 1:lh2_wrong+=1
elif real_val_out[ii] == 2:lh3_wrong += 1
elif real_val_out[ii] == 3:lh4_wrong += 1
elif real_val_out[ii] == 4:lh5_wrong += 1
elif real_val_out[ii] == 5:lh6_wrong += 1
elif real_val_out[ii] == 6:lh7_wrong += 1
print(i,"correct rate :",((lh1_right)/(lh1_right+lh1_wrong)),((lh2_right)/(lh2_right+lh2_wrong)),((lh3_right)/(lh3_right+lh3_wrong)),((lh4_right)/(lh4_right+lh4_wrong)),((lh5_right)/(lh5_right+lh5_wrong)),((lh6_right)/(lh6_right+lh6_wrong)),((lh7_right)/(lh7_right+lh7_wrong)))
# print(i,"nums:",((lh1_right+lh1_wrong)),(lh2_right+lh2_wrong),((lh3_right+lh3_wrong)),((lh4_right+lh4_wrong)),(lh5_right+lh5_wrong),((lh6_right+lh6_wrong)),((lh7_right+lh7_wrong)))
print(i,"epoch's accuracy:",accuracy_val)
print(i," loss is %f"%loss,"val loss is %f"%loss_val)
epoch_end_time =time()
print(i," epoch takes:",(epoch_end_time-epoch_start_time))
epoch_start_time = epoch_end_time
if i % 1 == 0 and i != 0:
saver.save(sess,os.path.join("./model/",'epoch{:06d}.ckpt'.format(i)))
print("------------model saved")
# print("-------------Epoch %d is finished"%i)
summary_writer.close()
saver.save(sess,"./model/")
print("optimization finished")
duration = time() - startTime
print("train takes:","{:.2f}".format(duration))
coord.request_stop()#通知线程关闭
coord.join(threads)#等其他线程关闭这一函数才返回