深度学习(5)--目标检测小总结(目标检测,人脸识别,目标识别与定位,YOLO算法,bounding box,边框回归)
网易云课堂吴恩达深度学习微专业相关感受和总结。因为深度学习较机器学习更深一步,所以记录机器学习中没有学到或者温故知新的内容。从总体架构的角度思路来看待机器学习问题
也做了不少CNN相关的项目内容,结合已知进行思考总结。
本文只是概念性的东西,没有太多细节,如果后续做实际的目标检测,再去学习细节,有个宏观印象,便于管控全局。
上一篇:深度学习(4)--卷积神经网络小总结(Inception及其超好用的百度云链接,CNN,LeNet,AlexNet,vgg,ResNet,1×1卷积核,扩充数据)https://blog.csdn.net/qq_36187544/article/details/92613205
下一篇:深度学习(6)--神经风格迁移与可视化卷积神经网络(tensorflow实现,可视化卷积神经网络,卷积核输出源码)https://blog.csdn.net/qq_36187544/article/details/92992270
目录
目标检测基本概念
YOLO算法(bounding box)
人脸识别
目标检测基本概念
分类定位:一个对象分类并进行定位。目标检测:针对多个对象进行,甚至多个类别。
目标识别与定位:识别即分类任务较简单。对于定位而言,比如需要定位4个点,可以让标签y的形式形同(K,x1,y1,x2,y2,x3,y3,x4,y4)K为是否有该类图像,如果有四个点的数据才有效,否则无效,但是点的意义要讲顺序,比如点1是头顶,点2是脚,顺序不一样容易导致输出结果错误。相当于网络多输出实现定位点输出。
目标检测示例:

YOLO算法(bounding box)
对象检测(目标检测)可采用滑动窗口目标检测法,但是通常的滑动窗口计算成本过大。一般的滑动窗口计算法取离散位置集合进行测试,但是实际上这样很不精准,所以采用YOLO算法
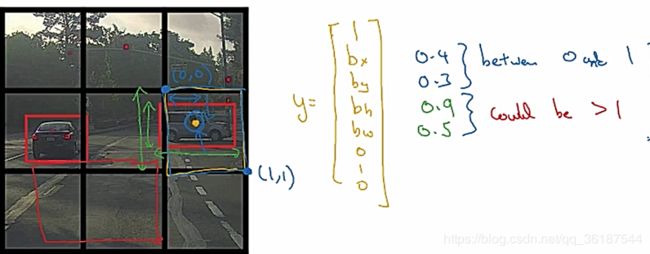
先聊一下bounding box:将图片分为M×N个模块,检测目标中心点在哪个模块(所以不用担心一个目标横跨几个模块),(bx,by,bh,bw)对应(中心点坐标,目标高和宽度)一般表示方式为百分比,表示占格子长宽的比例,y[0]表示这个模块是否包含中心点,如果为0不包含,y[1]、y[2]等就没有意义。y[5]、y[6]、y[7]表示那一种分类(如果单分类,完全可以去掉这几个参数),可以是汽车、行人、交通指示灯。当然,还有其他参数表达方式,需要再细研究(论文会很难==)
优势:可以只用一次卷积神经网络,就能输出3×3×8(以上图为准),执行速度很快。实际上就是把这类问题变成了神经网络回归问题。
写的挺好的边框回归参考文章:https://blog.csdn.net/zijin0802034/article/details/77685438
评价指标:交并比(预测框与实际框的交集大小比并集)
为了排除对同一目标多次检测,因为如果格子划分过细,可能很多格子都包含目标,所以需要非极大值抑制(非最大值抑制):1.去除所有IOU小于一定比例如0.6的结果,2.找到IOU高的边框结果如≥0.9的,寻找与这些高IOU有很高重合度(如IOU>0.5)的的边框,去除
当一个格子采集多个对象时,采用anchor boxes,用的较少,下图可以展示,对于Y是2×8维的变量,为了防止一个格子有多个对象能够采集到各个坐标。
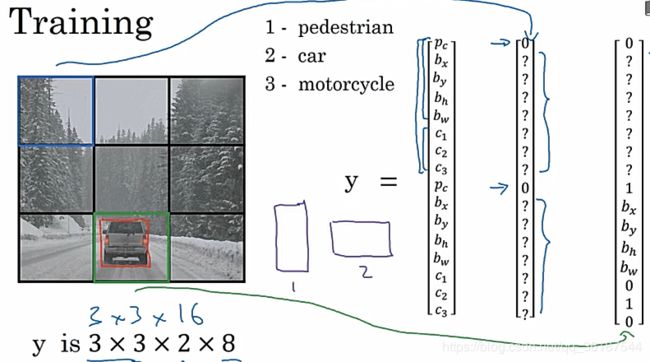
YOLO算法:就是利用标签Y做神经网络输出,得到最终结果。但是注意,最后需要进行一下非极大值抑制得到具体的目标检测边框。被吴恩达誉为最好用的目标检测算法。
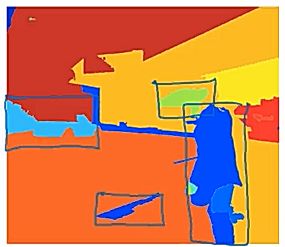
R-CNN:带区域的卷积算法,比如下左图蓝色框是没有意义的。所以运用图像分割算法得到不同色块,在色块边界跑算法。即通过算法划分区域得到候选区域,再在区域上跑卷积。也有改进算法比如fast-RCNN,faster-RCNN

人脸识别
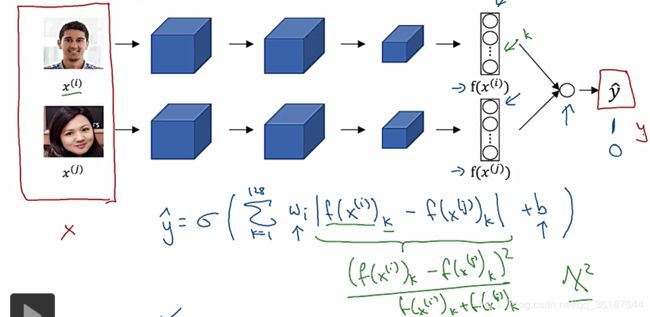
算法情况:没有很多数据进行训练,即一次学习问题,所以采用另外一种方式得到两个人像是否为同一个人,成对问题。
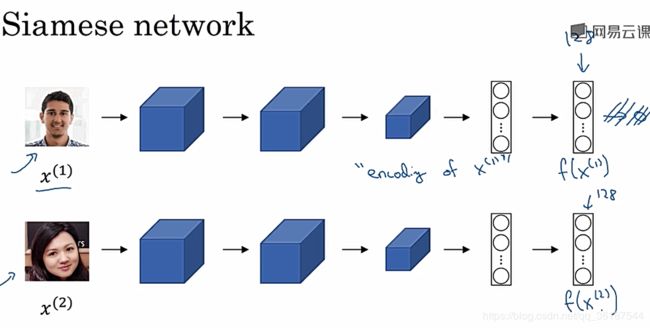
siamese网络
构建函数D,D计算两张图片人物相似度差异(可以就是一个计算两个向量距离范数的函数),分别把两张人像输入进siamese网络,但是不需要输出最后的结果,到达最后一层或某一层时,输出这个128(或者其他数字)的网络输出向量,把这两个人像对应的向量进行相似度比较,得到最后结果,D值很小则认为是同一个人。
triplet损失
在训练网络时采用三元损失训练网络:
Anchor锚图像,positive正确图像(即和锚图像为一个人),negative为错误图像(即和锚图像不为一个人),得到如下公式,A与P的范数与A与N的范数之差+α作为损失,α为间隔即AP与AN需要一定间隔避免AP与AN都近似为0这种情况。(均来自FaceNet论文)。选取合适的三元函数才能得到更好的参数效果。

另一种实现思路:转为二分类
不使用三元损失,可以把网路转为二分类问题,一下就比较熟悉了。输入两人像,之前siamese网络输出编码,这里不输出编码,而是对两张图片的编码再进行逻辑回归等(也可以是更多方式,比如统计学X2类似公式)生成结果: