yolov3 训练自己的数据(coco数据制作篇)
在GPU版本配置ok之后下面就要看制作自己的数据了。
我们的dataset是coco格式的,如果是voc格式的其他教程大多都是voc的吧。记录下coco格式的数据制作。
因为yolov3最终要将图片位置信息与图片的label信息保存在txt文件里的,所以现在首先要做的就是解析coco格式的json文件啦。(coco目标检测数据集标注目标信息采用的是数据格式是json,其内容本质是一种字典结构,字典堆栈和列表信息内容维护。coco里面的id和类名字对应:总共80类,但id号到90)
目录
一 check原数据集的class信息跟bbox信息
二 json解析
三 生成图片对应的绝对路径的train.txt与 val.txt
四 更改darknet目录下的.data与.names文件
五 修改yolov3.cfg文件
六 train
一 check原数据集的class信息跟bbox信息
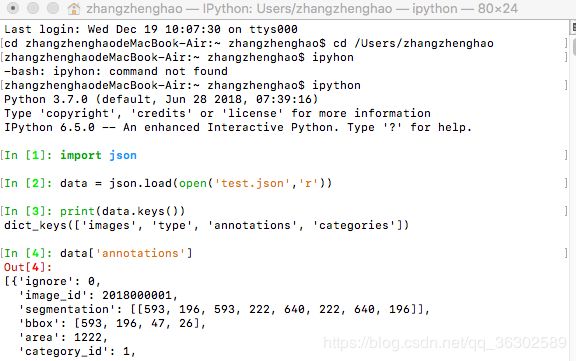
see一下coco json里面的形式,因为只做ob,所以只需要提取bbox就可以了,下面要看一下bbox对应的4个值到底是什么意思啊。验证后即为左上角的坐标+w,h

以这张图片的4个bbox计算中心点100*100的矩形,如下:(我的本本没有装cv2,用plt画的,代码如下)

import json
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
data = json.load(open('instances_train2018.json','r')) #json文件
image = mpimg.imread('/Users/zhangzhenghao/Desktop/000001.jpg')
img_id =2018006000001 #我用来测试的id
for ann in data['annotations']:
if ann['image_id'] == img_id:
x = ann['bbox'][0]
y = ann['bbox'][1]
w = ann['bbox'][2]
h = ann['bbox'][3]
x,y,w,h = int(x),int(y),int(w),int(h)
print(x,y,w,h)
fig = plt.figure()
ax = fig.add_subplot(111)
rect = plt.Rectangle((x,y),w,h)
ax.add_patch(rect)
plt.imshow(image)
plt.show()确定了bbox代表的信息,那么下一步就是要将annotation的信息转化为txt文件啦。
二 json解析
最终的label信息要跟图片的名字一样的,以txt结尾,里面包含五个数据。
类别id,中心化的x,y(中心点的坐标),w,h
下面是我的coco解析json并生成相应的txt文件的py代码:
from __future__ import print_function
import os, sys, zipfile
import json
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = box[0] + box[2] / 2.0
y = box[1] + box[3] / 2.0
w = box[2]
h = box[3]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
json_file='pascal_train2012_cococate.json' # # Object Instance 类型的标注
data=json.load(open(json_file,'r'))
ana_txt_save_path = "/Users/zhangzhenghao/Desktop/dataset/new" #保存的路径
if not os.path.exists(ana_txt_save_path):
os.makedirs(ana_txt_save_path)
for img in data['images']:
#print(img["file_name"])
filename = img["file_name"]
img_width = img["width"]
img_height = img["height"]
#print(img["height"])
#print(img["width"])
img_id = img["id"]
ana_txt_name = filename.split(".")[0] + ".txt"#对应的txt名字,与jpg一致
print(ana_txt_name)
f_txt = open(os.path.join(ana_txt_save_path, ana_txt_name), 'w')
for ann in data['annotations']:
if ann['image_id']==img_id:
#annotation.append(ann)
#print(ann["category_id"], ann["bbox"])
box = convert((img_width,img_height), ann["bbox"])
f_txt.write("%s %s %s %s %s\n"%(ann["category_id"], box[0], box[1], box[2], box[3]))
f_txt.close()结果如下:

三 生成图片对应的绝对路径的train.txt与 val.txt
yolo要求将所有的图片的绝对路径放在一个txt文件中,所以下一步就需要将训练集图片的绝对路径转换到一个txt文件中。
我们有一部分数据是.tiff格式的,我不知道能不能用因为官方提供的demo都是jpg文件格式的,于是进行了一波convert,代码如下:
import os
from PIL import Image
yourpath = '/media/pengjk/30213d25-fae8-4100-9d8b-9aed2bb5a8df/myimages'
for root, dirs, files in os.walk(yourpath, topdown=False):
for name in files:
print(os.path.join(root, name))
if os.path.splitext(os.path.join(root, name))[1].lower() == ".tiff":
if os.path.isfile(os.path.splitext(os.path.join(root, name))[0] + ".jpg"):
print "A jpeg file already exists for %s" % name
# If a jpeg is *NOT* present, create one from the tiff.
else:
outfile = os.path.splitext(os.path.join(root, name))[0] + ".jpg"
try:
im = Image.open(os.path.join(root, name))
print "Generating jpeg for %s" % name
im.thumbnail(im.size)
im.save(outfile, "JPEG", quality=100)
except Exception, e:
print e然后下面是生成绝对路径的代码:
# -*- coding: utf-8 -*-
import time
import os
import shutil
import string
def readFilename(path, allfile):
filelist = os.listdir(path)
for filename in filelist:
filepath = os.path.join(path, filename)
if os.path.isdir(filepath):
readFilename(filepath, allfile)
else:
allfile.append(filepath)
return allfile
if __name__ == '__main__':
path1 = "/Users/zhangzhenghao/Desktop/test/val_coco" //图片的文件夹
allfile1 = []
allfile1 = readFilename(path1, allfile1)
allname1 = []
txtpath = "/Users/zhangzhenghao/Desktop/test/val_coco" + "test.txt"//放入的txt文件
for name in allfile1:
file_cls = name.split("/")[-1].split(".")[-1]
if file_cls == 'txt':
with open(txtpath, 'a+') as fp:
fp.write("".join(name) + "\n")
这样就ok啦。
然后在这个过程中又有一点小波折,就是我发现我们的数据集大概有18万张图片来train,但是实际生成的.txt文件只有89000多条,于是只能将多余的筛出去啦。。 用的比较笨的方法,筛了1个多小时,勿喷代码:(这里用到了python中的shutil包,可以直接执行命令啦,为了方便将这89000万张图片重新建了个文件夹复制过来了。)
# -*- coding: utf-8 -*-
import time
import os
import shutil
import string
def readFilename(path, allfile):
filelist = os.listdir(path)
for filename in filelist:
filepath = os.path.join(path, filename)
if os.path.isdir(filepath):
readFilename(filepath, allfile)
else:
allfile.append(filepath)
return allfile
if __name__ == '__main__':
path1 = "/Users/zhangzhenghao/Desktop/test/val_data"
new_path ="/Users/zhangzhenghao/Desktop/test/new"
allfile1 = []
allfile1 = readFilename(path1, allfile1)
allname1 = []
for name in allfile1:
file_cls = name.split("/")[-1].split(".")[-1]
file_nas = name.split("/")[-1].split(".")[0]
if file_cls == 'jpg':
label = open('/Users/zhangzhenghao/Desktop/test/val_cocotest.txt', 'r')
for line in label:
label_nas = line.split("/")[-1].split(".")[0]
if file_nas == label_nas:
shutil.copy(name,new_path)
然后再生成一遍路径代码就能一一对应了。
然后做的就是将对应的train的jpg和txt val的jpg和txt放在同一个文件夹下面。(有人说可以分开放,但yolov好像有点问题,稳妥起见我们就直接放在一起吧)。
四 更改darknet目录下的.data与.names文件
实际train的时候需要修改这两个配置文件。
cfg/xx.data文件要改成如下的样子: (我直接用的coco的)
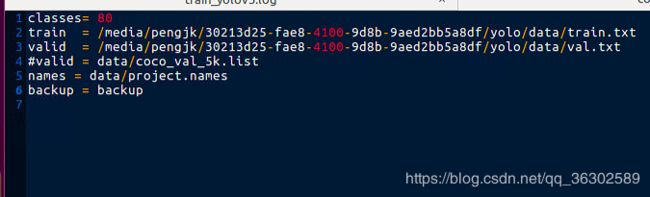
其中 train与valid指向自己上面对应所有train和val图片绝对路径的txt文件。
names指向下面的names所在的位置,(下面说怎么写),然后backup对应放模型的位置。
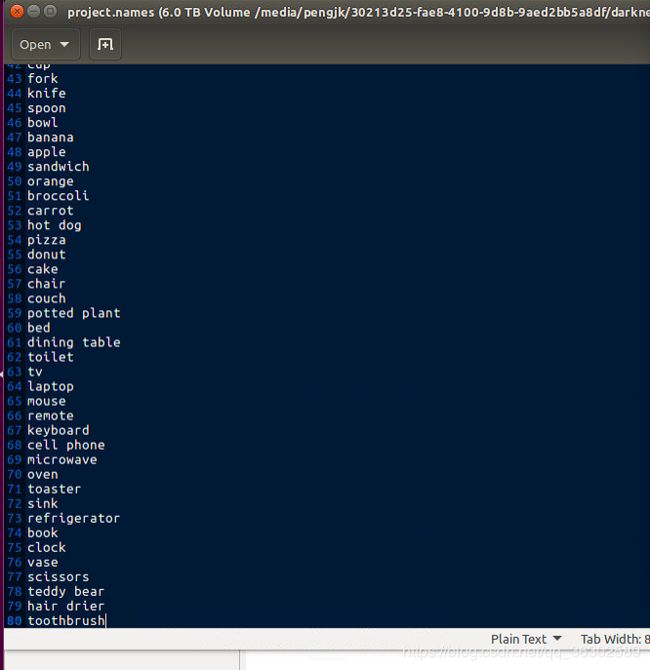
data/xx.names文件要按自己的类别信息填写,每个一行,查看一下json中的annotations中的类别信息,直接打下来就行啦。
五 修改yolov3.cfg文件
里面有6处需要修改,也就是yolo层对应的class num 以及 yolo层上面的卷积核的个数,因为yolov3.cfg默认是coco类,我的数据也是80类所以就没有改,在这里标出来吧。

卷积核的个数改为3*(类别数目+1+4) 一共修改3处卷积核的个数和yolo中的classes
六 train
在上面的都搞ok之后,下载一下权重文件就可以开始train了。下篇blog有train的一些细节信息。
./darknet detector train cfg/coco.data cfg/yolov3.cfg darknet53.conv.74 -gpus 0,1,2,3