docker搭建深度学习环境
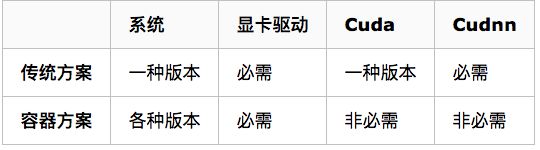
搭建深度学习计算平台,一般需要我们在本机上安装一些必要的环境,安装系统、显卡驱动、cuda、cudnn等。而随着Docker的流行,往往能够帮我们轻松的进行环境搭建、复制与隔离,所以官方也利用容器技术与深度学习相结合,因此也出现了以下方案。
容器方案比传统方案带来更多的随意性,装系统前不需要考虑Ubuntu哪一个版本符合不符合我们的代码运行要求,我们只需要安装一个自己喜欢的(18.04完全可以),再在官网下载一下显卡驱动,或者软件源附加驱动更新一下就行了,剩下都不需要我们继续考虑。这些也非常的轻松,因为Nvidia对Ubuntu的支持越来越友好,我们只需要下载deb包,一行命令即可安装成功。
I. 安装Docker
关于Docker教程,详见:Docker——入门实战
安装指定版本Docker CE
这里的版本由第二部分的Nvidia Docker依赖决定,在写此文时需要的版本是18.09.0,如果在安装Nvidia Docker时依赖的Docker CE版本已经变更,可以卸载重新安装需要的版本。
sudo apt install curl
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
echo "deb [arch=amd64] https://download.docker.com/linux/ubuntu xenial edge" | sudo tee /etc/apt/sources.list.d/docker.list
sudo apt-get update && sudo apt-get install -y docker-ce=18.03.1~ce-0~ubuntu1234执行这个命令后,脚本就会自动的将一切准备工作做好,并且把Docker CE 的Edge版本安装在系统中。
启动Docker CE
sudo systemctl enable docker
sudo systemctl start docker12建立docker 用户组
默认情况下,docker 命令会使用Unix socket 与Docker 引擎通讯。而只有root 用户和docker 组的用户才可以访问Docker 引擎的Unix socket。出于安全考虑,一般Ubuntu系统上不会直接使用root 用户。因此,更好地做法是将需要使用docker 的用户加入docker用户组。
# 建立docker组
sudo groupadd docker
# 将当前用户加入docker组
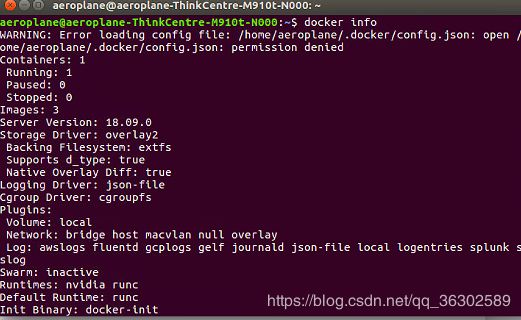
sudo usermod -aG docker $USER1234注销当前用户,重新登录Ubuntu,输入docker info,此时可以直接出现信息。
配置国内镜像加速
在/etc/docker/daemon.json 中写入如下内容(如果文件不存在请新建该文件)
{
"registry-mirrors": [
"https://registry.docker-cn.com"
]
}12345重新启动服务
sudo systemctl daemon-reload
sudo systemctl restart docker12II. 安装Nvidia Docker2
Nvidia Docker2项目的主页:https://github.com/NVIDIA/nvidia-docker
# If you have nvidia-docker 1.0 installed: we need to remove it and all existing GPU containers
ocker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
sudo apt-get purge -y nvidia-docker
# Add the package repositories
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/ubuntu16.04/amd64/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
# Install nvidia-docker2 and reload the Docker daemon configuration
sudo apt-get update && sudo apt-get install -y nvidia-docker2
sudo pkill -SIGHUP dockerd
# Test nvidia-smi with the latest official CUDA image
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi1234567891011121314III. 搭建环境
拉取镜像
Nvidia官网在DockerHub中提供了关于深度学习的各个版本环境,点我…有Ubuntu14.04-18.04,Cuda6.5-10,Cudnn4-7,基本含盖了我们所需要的各种版本的深度学习环境,我们直接拉取镜像,在已有的镜像基础上配置我们的深度学习环境。
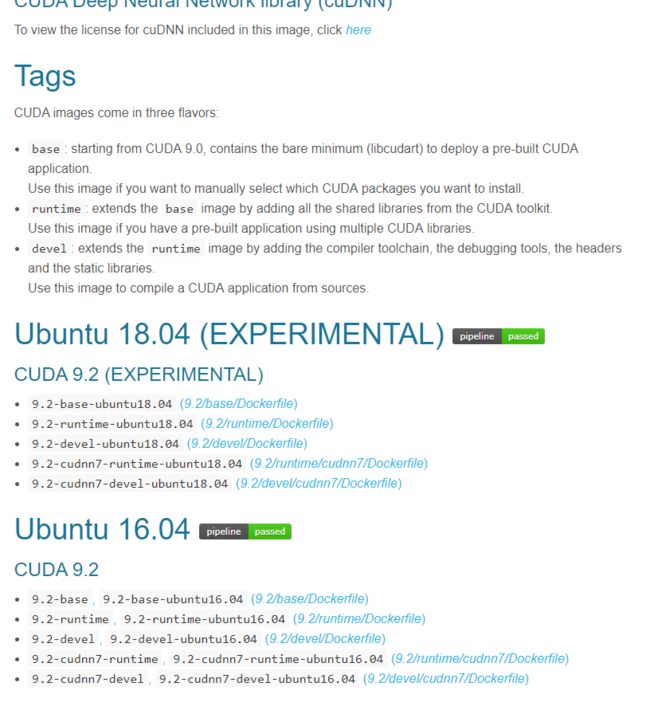
下载镜像,去官网通过dockerfile build方式生成images。
创建启动容器
nvidia-docker run -it {image name} /bin/bash //通过交互式方式开启镜像的一个容器
nvidia-docker run -it {image name} --name 自定义容器名 -v /home/你的用户名/本机目录/:/home/你的用户名/容器目录/ //本机目录和容器目录共享-v参数用于挂载本地目录,冒号前为宿主机目录,冒号后为容器目录,两个可以设置为一样比较方便代码书写。配置目录挂载是为了方便本文下一部分测试Mnist服务。容器启动完毕,此时,可以像正常本机配置的深度学习环境一样,测试各个软件的版本。
nvidia-smi
nvcc -V
# 查看cudnn版本
cd /usr/lib/x86_64-linux-gnu/
ll |grep cudnn12345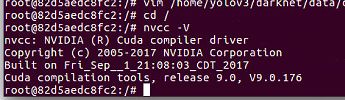

IV. 构建环境
安装环境
在上一部分我们搭建了深度学习计算的必要环境,包括CUDA和CUDNN。然而大多数深度学习环境都是需要执行Python编写的深度学习代码的,甚至需要一些常用的深度学习框架,如TensorFlow、PyTorch等。在上一部分我们拉取的Nvidia官方提供的镜像中并没有包含Python运行环境以及任何的深度学习框架,需要我们自己安装。
附上安装环境的所有命令:
apt-get update
# 安装Python2.7环境 3.+版本自行添加
apt-get install -y --no-install-recommends build-essential curl libfreetype6-dev libpng12-dev libzmq3-dev pkg-config python python-dev python-pip python-qt4 python-tk git vim
apt-get clean
## 安装深度学习框架 自行添加
pip --no-cache-dir install setuptools
pip --no-cache-dir install tensorflow-gpu==1.2 opencv-python Pillow scikit-image matplotlib1234567构建镜像
安装好环境后,其实已经可以开始运行我们的深度学习代码了。
如果此时,项目组另一位小伙伴也想跑深度学习,恰好需要和你一样的环境依赖,我们完全可以“拷贝”一份配好的环境给他,他可以直接上手去使用。Docker的方便之处也体现在这,我们可以将自己定制的容器构建成镜像,可以上传到Docker Hub给别人下载,也可以生成压缩包拷贝给别人。
利用commit命令,生成一个名为的新镜像。
docker commit 容器id 新的镜像名字 之后通过docker images 命令就能看到这个镜像了