puppeteer 实现爬虫
puppeteer 实现爬虫(windows)
因为puppeteer中大量api都是异步函数,所以首先需要对异步函数async/await有一定的了解,await会暂停当前async函数的执行,等待后面的Promise的计算结果返回以后再继续执行,也就是说程序会在这停止,直到到await后面的函数有返回才继续执行,但是前提是返回必须是一个Promise对象,也就是await只对函数有返回Promise对象时才进行等待,其他情况不进行等待。
①首先安装一下puppeteer
因为安装Chromium十分的慢浪费时间,所以建议跳过该步骤
npm i --save puppeteer --ignore-scripts
②手动安装Chromium
贴上下载网址:https://www.chrome64bit.com/index.php/chromium-64-bit-for-windows
下载时候安装之后就是一个文件夹。
③安装完成之后启用Chromium,这里headless控制是否弹出浏览器,executablePath,指定Chromium的安装位置
const puppeteer = require('puppeteer');
const browser = await puppeteer.launch({
headless: false,
executablePath: 'C:\\Users\\lenovo\\AppData\\Local\\Chromium\\Application\\chrome.exe', //指定chromium浏览器位置;
});
④启用Chromium之后,访问百度图片网址,模拟搜索关键字并查询的操作,查询的时候起初使用的,page.click(‘selector’),模拟点击,但是发现click函数总是报Error: Node is either not visible or not an HTMLElement。
await page.click('.s_btn');

检查网页元素发现,按钮的display属性是none,因此获取不到
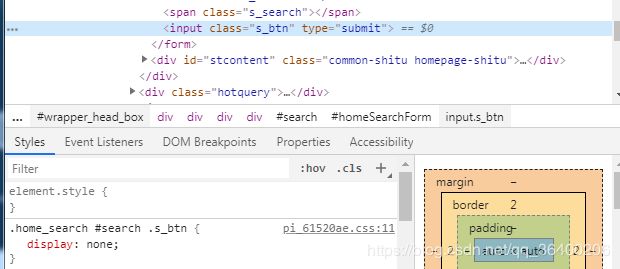
因此最后使用DOM的方法获取,利用的page.evaluate()方法。
await page.evaluate(()=> {
document.querySelector('.s_btn').click()
});
⑤查询关键字之后,将网页中所有的img标签匹配,并获取图片的src地址,并交由srcToImg函数进行处理。代码如下所示。
const puppeteer = require('puppeteer');
const { mn } = require('../config/defualt');
const srcToImg = require('../helper/srcToImg');
(async () => {
const browser = await puppeteer.launch({
headless: false,
executablePath: 'C:\\Users\\lenovo\\AppData\\Local\\Chromium\\Application\\chrome.exe', //指定chromium浏览器位置;
});
const page = await browser.newPage();
await page.setViewport({
width: 1000,
height: 1000,
deviceScaleFactor: 1,
});
console.log('reset viewPort');
await page.goto('http://image.baidu.com/');
console.log("go to https://image.baidu.com/");
await page.focus('#kw');
await page.keyboard.sendCharacter("狗");
await page.evaluate(()=> {
document.querySelector('.s_btn').click()
});
console.log('go to search list');
page.on('load', async ()=>{
console.log('page loading done, start fetch...');
const srcs = await page.evaluate(()=>{
const image = document.querySelectorAll('img.main_img');
return Array.prototype.map.call(image, img => img.src)
});
srcs.forEach( src => {
srcToImg(src, mn);
});
console.log("finish");
await browser.close();
})
})()
⑥srcToImg函数具体实现
const fs = require('fs');
const { promisify } = require('util');
const http = require('http');
const https = require('https');
const path = require('path');
const writeFile = promisify(fs.writeFile);
module.exports = async ( src , dir) => {
if(/\.(jpg|png|git)$/.test(src)){
await urlToImg(src, dir);
}
else{
await base64ToImg(src, dir);
}
}
// url -> img
const urlToImg = promisify((url, dir, callback) => {
const mod = /^https:/.test(url) ? https : http;
const ext = path.extname(url);
const file = path.join(dir,`${Date.now()}${ext}`);
mod.get(url, res => {
res.pipe(fs.createWriteStream(file))
.on('finish', ()=>{
callback();
console.log(file);
})
})
})
//base64 -> img
const base64ToImg =async function (base64Str, dir) {
//data:image/jpeg:base64,/sssss
const matches = base64Str.match(/^data:(.+?);base64,(.+)/);
try {
const ext = matches[1].split('/')[1]
.replace('jpeg', 'jpg');
const file = path.join(dir, `${Date.now()}.${ext}`);
await writeFile(file, matches[2], 'base64');
console.log(file);
} catch (error) {
console.log(error);
console.log('非法 base64字符串')
}
}