spark-hadoop集群搭建与测试(2019.02.20) 完全分布式
电脑配置 内存最少8G
如果你的电脑有固态,我们就可以起飞了。。。
使用到的工具:
VMware-workstation-full-14.1.1.exe
ubuntu-18.04.1.0-live-server-amd64.iso
jdk1.8.0_161.tar.gz
hadoop-2.7.7.tar.gz
scala-2.11.12.tgz
spark-2.4.0-bin-hadoop2.7.tgz
别去找了,给你们准备好了:spark-hadoop集群搭建全套工具
下载地址: https://download.csdn.net/download/qq_36405484/10964797
另一个集群搭建文档(网上下载的):建议配合食用
链接:https://pan.baidu.com/s/1YnVN2REn0sPg02Yc3GJBUw
提取码:93uz
我在VMware-workstation中搭建了三台虚拟机
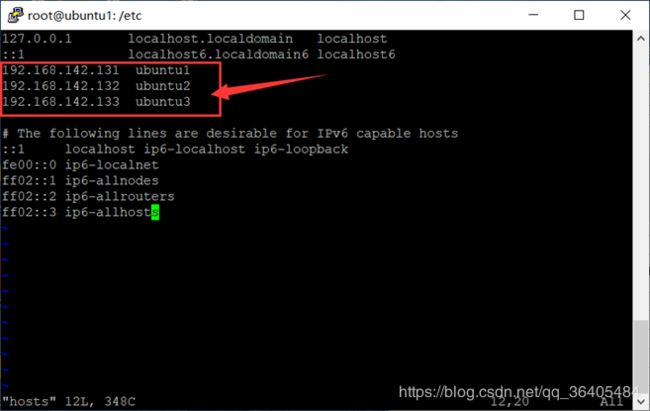
ubuntu1 192.168.142.131
ubuntu2 192.168.142.132
ubuntu3 192.168.142.133
ubuntu1安装:jdk、hadoop、scala、spark
ubuntu2安装:jdk、hadoop、scala、spark
ubuntu3安装:jdk、hadoop、scala、spark
因主机名已在其他配置中使用,不方便更改
ubuntu1作为master
ubuntu2、ubuntu3作为worker
windows系统中指定三台虚拟机对应的ip地址,方便后期测试
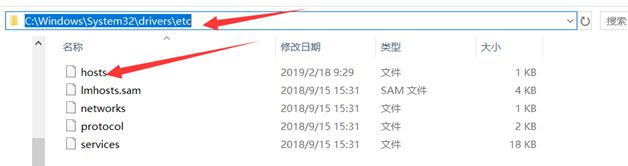
按照下图所示在hosts文件最后添加即可

cmd测试配置是否成功:

避免出现错误,linux中所有操作在root用户下执行
在三台虚拟机修改 /etc/hosts (三台虚拟机都要做这一步)
在各个节点安装ssh并配置免密码登录(此处自行百度,嗯 我懒)
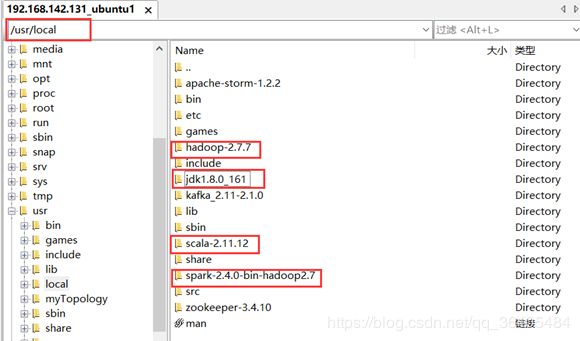
jdk、hadoop、scala、spark解压位置 /usr/local
先对一台虚拟机进行配置,配置完成后再使用scp命令拷贝到其他两台虚拟机(切记不要直接用SecureFX类似的工具直接把文件夹复制过去,这样很不友好)
scp命令详细表述:https://www.cnblogs.com/webnote/p/5877920.html
jdk配置:
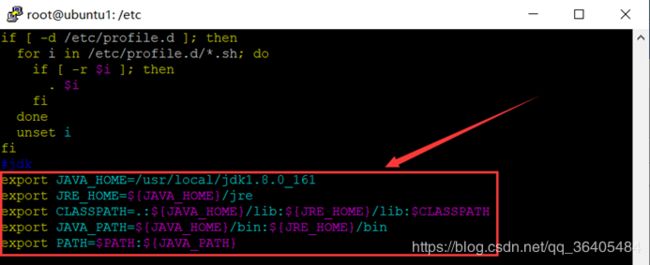
修改 /etc/profile 在最后添加如图所示(注意点和冒号,不要写错了)
export JAVA_HOME=/usr/local/jdk1.8.0_161
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}
使用命令使更改生效:source /etc/profile
测试jdk是否安装成功:
java javac java -version
三个命令都执行一遍,有信息反馈就成功了。
搭建hadoop集群
修改/etc/profile文件
文件最后添加
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH

使用命令使更改生效:source /etc/profile
验证是否成功:
执行命令 hadoop version
如图所示则成功

配置hadoop
配置前首先在hadoop安装目录下创建以下文件夹:
mkdir tmp
mkdir dfs
mkdir dfs/data
mkdir dfs/name
修改hadoop-env.sh
![]()
指定jdk安装目录

修改yarn-env.sh
![]()
指定java安装目录
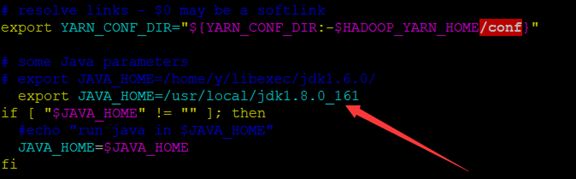
修改mapred-env.sh
![]()
指定java安装目录

修改slaves,将各个worker节点的hostname加进去
vim slaves
![]()
ubuntu2
ubuntu3

修改core-site.xml
![]()
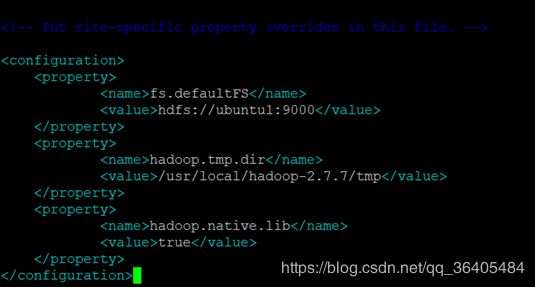
修改hdfs-site.xml
![]()

修改mapred-site.xml
![]()

修改yarn-site.xml
![]()

启动并验证hadoop集群
格式化hdfs系统
hadoop namenode –format
![]()
该命令会启动,格式化,然后关闭namenode
启动hdfs: sbin/start-dfs.sh

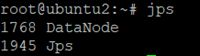
使用jps验证hdfs是否启动成功:
ubuntu1

ubuntu2
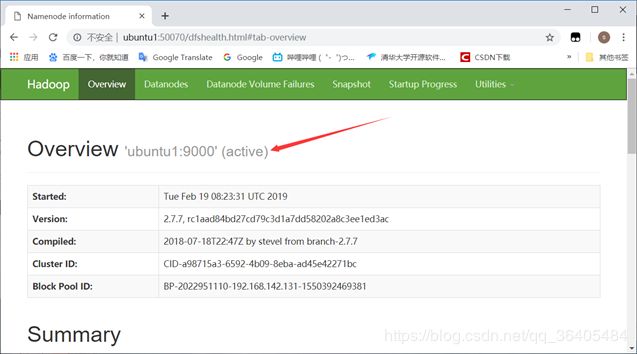
通过地址检查hdfs是否启动成功
http://ubuntu1:50070

启动yarn: sbin/start-yarn.sh

使用jps验证yarn是否启动成功
ubuntu1
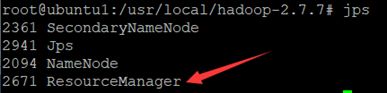
ubuntu2

通过地址检查yarn是否启动成功:
http://ubuntu1:8088
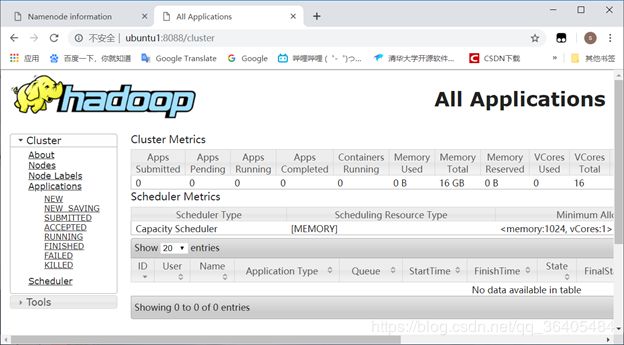
http://ubuntu2:8042
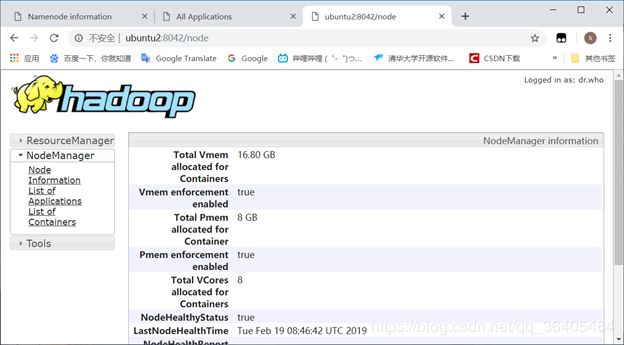
启动jobhistory server:
![]()
使用jps验证jobhistory
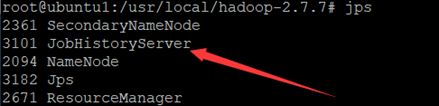
通过地址检查jobhistory server是否启动成功
http://ubuntu1:19888

安装scala
修改文件/etc/profile
在文件最后添加
export SCALA_HOME=/usr/local/scala-2.11.12
export PATH=$PATH:$SCALA_HOME/bin

执行命令使文件生效 source /etc/profile
验证scala是否安装成功:scala -version
![]()
spark集群搭建
修改文件 /etc/profile
在文件最后添加
export SPARK_HOME=/usr/local/spark-2.4.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin

执行命令使文件生效 source /etc/profile
配置spark:
1.修改slaves文件,若没有slaves文件可以cp slaves.template slaves创建
在文件最后添加worker节点的hostname
ubuntu2
ubuntu3

2. 配置spark-env.sh,若没有该文件可以cp spark-env.sh.template spark-env.sh创建,添加如下内容
export JAVA_HOME=/usr/local/jdk1.8.0_161
export SCALA_HOME=/usr/local/scala-2.11.12
export HADOOP_HOME=/usr/local/hadoop-2.7.7
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.7/etc/hadoop
export SPARK_MASTER_IP=ubuntu1
export SPARK_WORKER_MEMORY=1g

3. 配置spark-defaults.conf,若没有该文件可以cp spark-defaults.conf.template spark-defaults.conf创建,添加如下内容
spark.eventLog.enabled true
spark.eventLog.dir hdfs://ubuntu1:9000/historyserverforspark
spark.yarn.historyServer.address ubuntu1:18080
spark.history.fs.logDirectory hdfs://ubuntu1:9000/historyserverforspark

4.启动并验证spark集群
Spark只是一个计算框架,并不提供文件系统功能,故我们需要首先启动文件系统hadoop
注:此时hadoop集群已经处于启动状态,所以现在只需要启动spark集群,启动spark集群,常见的做法是在master节点上执行start-all.sh

使用jps在master和worker节点上验证spark集群是否正确启动:
ubuntu1
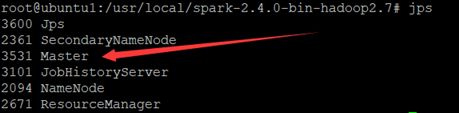
ubuntu2
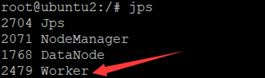
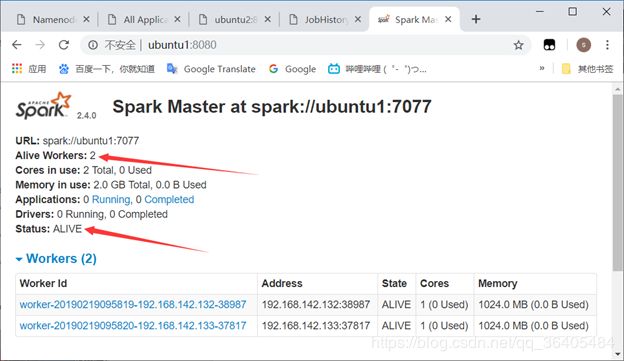
通过地址查看spark集群是否启动成功:
http://ubuntu1:8080
在spark安装目录下执行命令 hdfs dfs -mkdir -p /historyserverforspark
![]()
执行命令sbin/start-history-server.sh
![]()
执行命令jps

通过地址栏查看 http://ubuntu1:50070

通过地址栏查看 http://ubuntu1:18080

声明:这篇集群搭建文档是依照同行编写的文档做了一下更新,文档开头已提供下载地址(原作者地址找不到了)
大家可以对比着这两篇文档进行集群搭建。
至此,spark-hadoop集群基础搭建全部完成,文档中肯定有考虑不足的地方,望同学们见谅,文档中未涉及到的部分,或者和其他同行有不同的地方,还望同学们对比一下,找到最佳方案。
有问题,问度娘,大家一起努力。