HBase最佳实践-CMS GC调优
原文地址:http://hbasefly.com/2016/08/09/hbase-cms-gc/
HBase发展到当下,对其进行的各种优化从未停止,而GC优化更是其中的重中之重。从0.94版本提出MemStoreLAB策略,Memstore Chuck Pool策略对写缓存Memstore进行优化开始,到0.96版本提出BucketCache以及堆外内存方案对读缓存BlockCache进行优化,再到后续2.0版本宣称会引入更多堆外内存,可见的HBase会将堆外内存的使用作为优化GC的一个战略方向。然而无论引入多少堆外内存,都无法避免读写全路径使用JVM内存,就拿BucketCache中offheap模式来讲,即使HBase的数据块是缓存在堆外内存的,但是在读取的时候还是会首先将堆外内存中的块加载到JVM内存中,再返回给用户。可见,无论使用多少堆外内存,对JVM内存的使用终究是绕不过去,既然绕不过去,就还是需要落脚于GC本身,对GC本身进行优化。本文就将会介绍HBase应用场景下CMS GC策略的调优技巧,后续还会针对另一业界开始 使用的GC策略-G1GC策略在HBase的应用场景下进行调优介绍。
CMS GC工作原理
如果看官已经对CMS GC工作原理比较熟悉,完全可以跳过本节内容,直接进入下节。如果看官还对CMS GC不是很了解,可以参考笔者之前的另一篇文章“HBase GC的前生今生 - 身世篇“,文中对JVM的内存结构以及CMS GC进行了相当详细的介绍。为了下文介绍方便,在此还是对其中的一些重要知识点进行提炼:
1.整个JVM内存由Young District,Tenured区和Perm区三部分组成,其中Young区又分为一个Eden区和两个幸存者区
2.整个对象生命周期简要说明(一定要烂熟于心,下文会一直用到):
(1)Young区:一个对象初始化之后,首先会进入Eden区,当Eden区满之后会触发一次Minor GC,Minor GC会检查Eden区所有对象是否依旧存活(是否有其他对象引用),如果存活,会将其从伊甸区拷贝到幸存者区,并将这些存活对象的年龄加一,而死亡的对象会被作为垃圾回收。此时伊甸园区又空闲出来,等新对象填充,填充满之后再会触发小GC,如此往复。需要注意的是,每执行一次Minor GC,存活对象的age就会加一。
(2)终身区:一旦存活对象的年龄超多一定阈值就会晋升到终身区,因此可以理解为终身区一般存放长寿对象很显然,随着时间流逝,终身区也会被填充满,此时就会触发CMS GC(old gc),这种GC相对比较复杂,由5个步骤组成,详见参考文章。
3.无论是Minor GC还是CMS GC,都会'Stop-The-World',即停止用户的一切线程,只留下gc线程回收垃圾对象。其中Minor GC的STW时间主要耗费在复制阶段,CMS GC的STW时间主要耗费在标示垃圾对象阶段。
GC调优目标
上节简单介绍了Java虚拟机的内存结构以及Java GC的基本知识,接下来会在此基础上介绍HBase集群中GC的几种参数调优技巧。在介绍具体的调优技巧之前,有必要先来看看GC调优的最终目标和基本原则:
1.平均轻微GC时间尽可能短。因为整个轻微的GC都处于STW,因此短时间轻微的GC会使用户读写更加平稳,延迟可控。
2. CMS GC次数越少越好。时间越短越好。一方面是因为一次CMS GC一般都会引起至少秒级的应用暂停,对用户读写影响较大;另一方面频繁的CMS GC会产生大量的内存碎片,严重的时候会引起Full GC,导致RegionServer宕机。
下面对参数的调优技巧都谨遵以上原则,尤其对于HBase的这类延迟敏感性项目而言,在尽量避免严重影响用户读写的情况下使得GC更加平稳,暂停时间更短!
CMS GC优化技巧
本节会针对HBase的这一应用场景对JVM的各种GC参数进行分析,主要分三个阶段进行。第一阶段会介绍适用于所有场景下的GC参数配置,这些参数不需要太多解释读者就可以轻松理解;第二阶段和第三阶段分别就两组参数进行调优讲解,这两组参数一般会根据不同的应用场景进行设置才能使得GC效果最好,鉴于这两组参数的复杂性,我们会通过理论+实验的方式一一进行说明;
阶段一:默认推荐配置
在介绍具体的调优技巧之前,先来看看CMS GC涉及到的所有相关参数及其对应的意义,下面是最常见的参数:
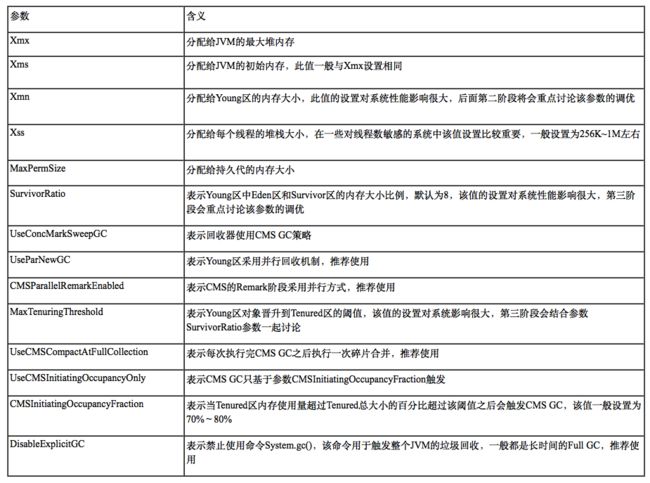
通过上文对各个GC参数的说明,可以轻松得出第一阶段推荐的参数设置如下,这样的设置基本适用于所有的场景:
调优预准备
上文通过解释各个GC参数意义给出了基本的推荐设置,同时也提到几个对性能影响重大的参数:到厦门,SurvivorRatio以及MaxTenuringThreshold,下面会通过理论推理+实验验证的方式对这几个参数在HBase的系统的设置进行调优在深入介绍调优技巧之前,需要额外针对三个相关部分预先做下讲解,这样可以更好地理解下文的实验数据分析这三部分分别是:。测试环境+测试基本条件,GC日志解释,HBase的场景内存分析;
测试环境
首先就下文中实验测试的硬件拓扑,软件配置以及相关测试数据情况进行说明:

需要强调的是HBase的全部配置为BucketCache模式,而不是LruBlockCache使用了大量堆外内存作为读缓存,在很大程度上优化了GC,如下图:

上图是在两种缓存策略下GC表现情况,可见BucketCache模式比LruBlockCache模式GC表现好很多,强烈建议线上配置BucketCache模式。可能很多童鞋都测试过这两种模式下的GC,吞吐量,读写延迟等指标,看到测试结果都会很疑惑,BucketCache模式下的各项性能指标都比LruBlockCache差了好多,笔者也疑惑过,后来才明白:测试肯定是在基本全内存场景下进行的,这种情况下确实会是如此。读者可以想想为什么会如此,实在不明白可以参考之前一篇博文“ BlockCache方案性能对比测试报告 ”。但是话又说回来,在大数据场景下又有多少业务会是全内存操作呢?
GC日志分析
介绍完实验基本条件后,再对GC日志进行简单的解释,方便下文对日志进行分析需要注意只有在添加参数-XX:+ PrintTenuringDistribution才能打印对应日志,强烈建议线上集群开启该参数,日志片段如下:
上述日志片段分三部分进行解释:
第一部分:基本信息区,主要有两点需要重点关注,其一是希望的幸存者大小268435456个字节,该值通过SurvivorSize * TargetSurvivorRatio计算而来,默认TargetSurvivorRatio为50%,如果XMN为5克,SurvivorRatio为8的话,期望的幸存者尺寸就等于256M;其二是新的阈值5(最多15),括号中最多15表示对象晋级老生代的最大阈值为15,新的阈值5表示调整后的阈值为5,可见,阈值在整个过程中会不断调整,调整后的阈值表示不大于该值的所有年龄的对象大小总和刚好大于所需的幸存者大小,否则为最大阈值(15)。
第二部分:不同年龄对象分布区,第一列表示该杨区共分布有年龄在1〜6的对象;第二列表示所在年龄含有的对象集所占内存大小,比如年龄为2的所有对象总大小为80236520个字节;第三列表示小于对应年龄的所有对象占用内存的累加值,比如AGE2岁对应第二列137759704总表示年龄为1和年龄为2的所有对象总大小;
第三部分:内存回收信息区,第一列表示杨区的内存回收情况,1268903K-> 305311K表示杨区回收前内存为1268903K,回收后变为305311K;第二列表示JVM堆的内存回收情况, 26598675K-> 25635082K(66584576K)表示当前jvm的总分配内存为66584576K,回收前对象占用内存为26598675K,回收后对象占用内存为25635082K;第三列表示回收时间,其中真正表示本次GC所消耗的STW时间,即用户业务暂停时间。
HBase的场景内存分析
通常来讲,每种应用都会有自己的内存对象特性,分类来说无非就两种:一种是短寿对象(指存活对象较短的对象,比如临时变量等)居多工程,比如大多数纯HTTP请求处理工程,短寿对象可能占到所有对象的70%左右;另一种是长寿对象(指存活对象较长的对象,比如TTL设置较长的缓存对象)居多工程,比如类似于HBase的,星火等这类大内存工程具体以HBase的为例,来看看具体的内存对象:
1. RPC请求对象,比如请求对象和响应对象,一般这些对象会随着短连接RPC的销毁而消亡,这些对象可以认为是短寿对象;
2. Memstore对象,HBase中Memstore中对象一般会持续存活较长时间,用户写入数据到Memstore中之后对象就一直存在,直至Memstore写满之后flush到HDFS。一般在写入QPS较高的情况下写满的memstore也通常需要一个小时左右,可见的memstore对象肯定是长寿对象。另外,那种MEMSTORE对象默认比较大,2M大小。
3. BlockCache对象,和Memstore对象一样,BlockCache对象一般也会在内存存活较长时间,属于长寿对象。这种对象默认64K大小。
因此可以看出,HBase的系统属于长寿对象居多的工程,因此GC的时候只需要将RPC这类短寿对象在年轻的区淘汰掉就可以达到最好的GC效果。
阶段二:NewParSize调优
理论分析
NewParSize表示young区大小,而young区大小直接决定minor gc的频率.minor gc频率一方面决定单次minor gc的时间长短,gc越频繁,gc时间就越短;一方面决定对象晋升到老年代的量,GC越频繁,晋升到老年代的对象量就越大解释起来就是:
1.增大年轻区大小,次要gc频率降低,单次gc时间会较长(young区设置更大,一次gc就需要复制更多对象,耗时必然比较长),业务读写操作延迟抖动大。反之,业务读写操作延迟抖动较小,比较平稳。
2.减小年轻区大小,轻小gc频率增快,但会加快晋升到老年代的对象总量(每gc一次,对象年龄就会加一,当年超过阈值就会晋升到老年代,因此gc频率越高,年龄就增加越快),潜在增加老gc风险。
因此设置NewParSize需要进行一定的平衡,不能设置太大,也不能设置太小。
实验结果
实验条件:分为独立对照试验,三台RegionServer的分别设置XMN为512M,2G,5G中,XMN越大,分配的杨区越大; SurvivorRatio和MaxTenuringThreshold取默认值;
实验结果曲线图:


结果分析
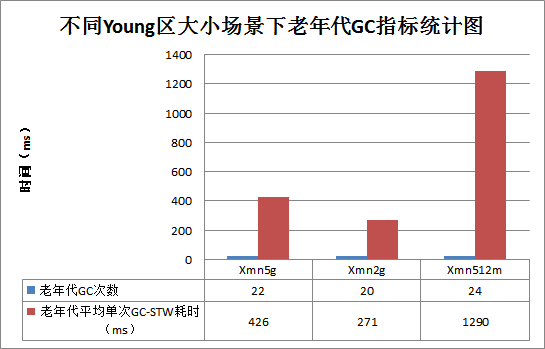
1.图一是Xmn不同场景下总体的GC耗时曲线图,其中横坐标表示GC次数,纵坐标表示GC耗时(STW),单位ms。需要特别说明的是,这3条曲线是在相同时间段统计的,也就是说在这段时间内XMN为512米的情况下GC次数最多,而相应的XMN为5的情况下GC次数最少。
2.图一整体上来看绿线尖峰很多而且很高,表示CMS GC较频繁,但绿线主体部分处于红线与蓝线之下,表示平均Minor GC耗时更短;蓝线GC次数最少,尖峰也比较突出,另外Minor GC相比红线和绿线耗时更长;红线的Minor GC耗时介于蓝线和绿线之间,尖峰比较平稳,表示CMS GC相对比较短暂;因此总体来看,红线代表的Xmn为2的场景下CMS GC更加合理,平均Minor GC相对不高,而相比之下,另外两种场景都有特别明显的缺陷,Xmn = 2是一个最优的选择;图一只能直观上看出这么多,更加精确结果需要接着看图二和图三。
3.图二主要统计Minor GC的主要指标:总GC次数以及平均单次Minor GC耗时。两个来看,更关注后者,因为后者决定了业务读写的延迟以及稳定度;由图中可以看出,Xmn512m的平均单次Minor GC耗时最少,其次是Xmn2g,最差是Xmn5g,达到了130ms左右,意味着在其小GC过程中所有业务读写延迟至少为130ms;这个也很很好理解,Young区越小,Minor GC频率越高,单次Minor GC需要复制的对象数就越少,耗时越少;
4.图三主要统计CMS GC(老年代GC)的主要指标:CMS GC次数以及平均单次老年代GC耗时(只算STW耗时);由图中可以看出,Xmn2g无论是GC次数还是GC耗时都更加优秀,相比之下Xmn512m就是最差的选择;解释起来也很简单,因为年轻区设置太小,次要GC频率高,对象年龄增加很快,很多对象就有可能因为年超过阈值(默认6)晋升到老年代,相对而言会更有可能引入大量短寿对象晋升老年代。而短寿对象相对而言会比较小,比如请求,响应等,大量小对象一旦进入老年代,就会导致CMS GC的时候需要标注更多对象,必然比较耗时;
实验结论
可见,测试结果基本和理论分析一致,Xmn设置过小会导致轻微的GC性能较差,因此建议在JVM Heap为64g以上的情况下设置Xmn在1~3g之间,在32克之下设置为512米〜1克;具体最好经过简单的线上调试;需要特别强调的是,笔者在很多场合都看到很多HBase的线上集群会把XMN设置的很大,比如有些集群Xmx为48g,Xmn为10g,查看日志发现GC性能极差:单次Minor GC基本都在300ms~500ms之间,CMS GC更是很多超过1s。在此强烈建议,将Xmn调大对GC (无论Minor GC还是CMS GC)没有任何好处,不要设置太大。
阶段三:增大Survivor区大小(减小SurvivorRatio)&增大MaxTenuringThreshold
理论分析
上文讲过,一次小GC会将存活对象从Eden区(以及幸存者来自区)复制到Survivor区(到区),因此增大Survivor区可以容纳更多的存活对象。这样就会防止因为幸存者区太小导致很对存活对象还没有到达MaxTenuringThreshold阈值就直接进入老生代,潜在增大老gc的触发频率;但是幸存者区设置太大也会有一定的问题,幸存者设置较大会使得对象可以在Young District '待'的时间很长,但是对于一些长寿对象较多的场景下(比如HBase),大量长寿对象长时间待在Young区做很多'无谓'的复制,一定程度上增加Minor GC开销。
另外,增加MaxTenuringThreshold相当于提高了进入老年代的门槛,可以有效限制进入老年代的对象数。和Survivor设置相似,调整MaxTenuringThreshold也需要做一个取舍,设置太小会增加CMS GC的触发频率以及耗时,而设置太大则会在长寿对象较多场景下增加Minor GC开销。一般情况下,默认MaxTenuringThreshold = 15已经相对比较大,不需要做任何调整。
实验结果
实验条件:分为独立对照试验,三台RegionServer的分别设置SurvivorRatio为2,8,15,SurvivorRatio越大,幸存者区大小越小; MaxTenuringThreshold取默认值;其他:-Xmx64g,-Xmn2g;
实验结果曲线:


结果分析
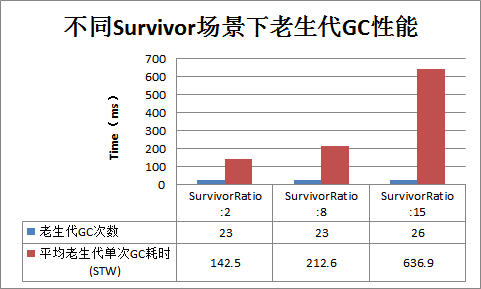
1.图一是SurvivorRatio在三种不同场景下对应的GC性能曲线图,大体可以看出蓝线Minor GC次数最多,绿线尖峰太多,即CMS GC性能最差;具体细节再来看图二和图三。
2.图二主要统计Minor GC主要指标:平均单次Minor GC耗时三者基本相当,SurvivorRatio:2场景下稍微较高,这是因为SurvivorRatio = 2对应的Survivor区较大,可以使得对象在Young区'待'的时间很长,在HBase这种长寿对象较多的情况下,可能会增加一些无谓的'复制'开销(下文会通过日志分析详细解释)。另外,SurvivorRatio = 2场景下Minor GC Survalivor越大,Eden自然越小,Minor GC频率就会增大。可见,SurvivorRatio = 2场景下Minor GC性能相对稍微较差,可能的原因是因为在总年轻大小确定的情况下。
3.图三主要统计CMS GC主要指标:三者CMS GC次数基本相当,SurvivorRatio = 2场景下单次CMS GC耗时最少,相比SurvivorRatio = 8的场景耗时减少30%左右,性能最好;而相比之下SurvivorRatio = 15场景下耗时最长,性能相当差;这是因为SurvivorRatio = 2场景下存活对象可以长时间待在杨区,可以得到充分的淘汰,晋升到老生代的短寿小对象会比较少,因而CMS GC性能较好;相比SurvivorRatio = 15会因为Survivor区设置太小,很多短寿小对象因为得不到充分的淘汰就会'溢出'到老生代,导致CMS性能很差。
实验结论
可见,测试结果基本和理论分析也基本一致,对于Minor GC来说,SurvivorRatio设置对其影响不是很大。而对于CMS GC来说,将SurvivorRatio设置过大简直就是灾难,性能极其差。而和默认值SurvivorRatio = 8相比,将SurvivorRatio调小有利于短寿小对象更充分地淘汰,因此建议将SurvivorRatio = 2
CMS调优结论
1.缓存模式采用BucketCache策略Offheap模式
2.对于大内存(大于64G),采用如下配置:
其中XMN可以随着爪哇分配堆内存增大而适度增大,但是不能大于4g的取值范围在1〜3克范围; SurvivorRatio一般建议选择为2; MaxTenuringThreshold设置为15;
3对于小内存(小于64G),只需要将上述配置中Xmn改为512m-1g即可
总结
CMS GC的相关知识,之后分三个阶段层层推进对HBase集群中相关重要参数的调优进行了详细说明,尤其后面两阶段通过理论推理以及实验验证的方式对两组核心参数进行了针对性调整,最终得出一个较为完整的CMS GC参数配置。读者可以参考该参数配置对集群进行调整,再通过日志查看调整效果〜
cms gc HBase 调优
范欣欣
就职于网易杭州研究院后台技术中心数据库技术组,从事HBase的开发,运维,对HBase的相关技术有浓厚的兴趣邮箱:[email protected]
在“HBase最佳实践-CMS GC调优”上有31条评论
-
章鑫
2016年9月23日上午9:25
范老师你这里说的hbase_heapsize在我的配置里默认为1000MB,这个hbase_heapsize和我分配给读写缓存的regionserver_heapsize是啥关系?
回复
-
范欣欣
2016年9月23日上午9:33
不好意思这篇文章没有看到hbase_heapsize的表述哎〜
回复
-
章鑫
2016年9月27日上午9:08
是的我的hadoop环境是有ambari搭的,hbase相关的内存分配只有hbase_heapsize(默认1000),另外就是regionserver_heapsize了,regionserver_heapsize的内存用来作为写缓冲区(hbase.regionserver.global.memstore)和读缓冲区( hfile.blockcahe.size)请问我这种环境下如何进行内存的gc调优?
回复
-
范欣欣
2016年9月28日上午9:29
嗨,
1。gc调优一方面主要看readbuffer的策略,建议使用bucketblockcache替代当前的lrublockcache
2.另一方面需要关注jvm的gc参数,比如xmn参数以及suvivorratio参数两个,可以参考文章GC调优本身和hbase_heapsize以及regionserver_heapsize的大小没有太大关系,也和write_buffer以及的read_buffer关系不大
回复
-
-
-
-
张侃
2016年10月16日下午3:32
阶段三的第三幅图貌似贴错了
回复
-
范欣欣
2016年10月20日上午9:05
谢谢已经修改
回复
-
-
蒋挺
2016年10月21日上午10:31
博主您好,想请教一下,GC的日志,在/ var /日志/ HBase的/ gc.regionserver.log每次重启就会覆盖,能够配置成追加写吗。有时HBase的报错,想去查GC的问题时,一旦重启就没了之前的GC日志信息了。
回复
-
范欣欣
2016年10月21日下午12:31
可以看看你的jvm配置将GC日志设为3或者更多-Xloggc:$ HBASE_LOG_DIR / gc-regionserver -`date +%Y%m%d-%H-%M`.log -XX:+ UseGCLogFileRotation - XX:NumberOfGCLogFiles = 3
回复
-
-
JC
2016年11月1日下午7:57
博主你好,我也是做了好多测试,发现不同读写比情况下的LRU的性能(吞吐,延时)都要强于CBC,看到文章中也提到了这一点,但还是想不懂为什么CBC要差一些,所以很想请教博主?
回复
-
范欣欣
2016年11月1日下午9:59
因为CBC模式下bucketcache(offheap模式)使用堆外内存,堆外内存读取会比JVM内存读取复杂,流程更多,所以在全内存场景喜爱LRU完全好于CBC,在缓存基本不命中场景下两者吞吐量延迟基本相当
回复
-
JC
2016年11月2日上午9:44
全内存场景是指?
回复
-
范欣欣
2016年11月2日上午11:02
数据量比较小或者有大量热点读的场景大多数读都落在BlockCache场景
回复
-
JC
2016年11月2日上午11:07
谢谢啦
-
-
-
-
-
顾汉杰
2017年4月21日下午5:43
勘误:
文章“阶段三:增大Survivor区大小(减小SurvivorRatio)&增大MaxTenuringThreshold”一节的实验结论中,原文“而和默认值SurvivorRatio = 8相比,将SurvivorRatio调大有利于短寿小对象更充分地淘汰,因此建议将SurvivorRatio = 2”有误,应该是‘将SurvivorRatio调小’。回复
-
范欣欣
2017年4月24日上午11:51
谢谢已修正
回复
-
-
陈伟
2017年5月12日下午2:23
范大神,能问下你们hbase集群zookeeper.session.timeout这个参数设置多大么,能否通过调大这个参数来降低因为GC导致的RS连接zk超时挂掉问题呢?假如我调整到比如180秒会对hbase造成什么影响吗?万分感谢!!
回复
-
范欣欣
2017年5月12日下午4:11
离线集群的话设置大点没啥问题实时在线对延迟敏感的集群就不能设置太大
回复
-
-
陈伟
2017年5月12日下午4:12
发现个小错误,-XX:+ MaxTenuringThreshold = 15应该是没有” +”符号,刚试了下,带上” +”号报错。
回复
-
范欣欣
2017年5月12日下午6:21
谢谢已修复
回复
-
-
R1SOFT
2017年6月13日下午9:54
博主你好,请问这些图是用什么工具画的?
回复
-
范欣欣
2017年6月14日上午10:22
在线画图工具processon,好像最近收钱了......
回复
-
-
AUSTIN
2017年11月3日上午11:35
很好的文章,感谢博主。可惜图挂了啊
回复
-
范欣欣
2017年11月6日上午9:07
我这边看起来是好的哎如果需要的话可以回复我我发你邮箱
回复
-
-
左眼皮跳跳
2017年11月12日下午10:02
博主方便用jmap -heap PID显示出博主的配置,然后解释这些参数吗?这样可能更加方便大家看学习博主的配置。
回复
-
范欣欣
2018年7月12日上午9:16
好吧因为垃圾评论太多有些评论看漏了....
回复
-
-
达里安
2018年5月28日下午4:54
您好,请问您为什么没有使用G1 GC机制呢?
回复
-
范欣欣
2018年5月29日上午11:05
没有用G1GC一方面是因为我们这边内存使用量没有那么大,另一方面G1GC要用好需要关注太多参数配置。不过以后是一个大的方向
回复
-
SHAWGUO
2018年8月20日下午6:21
我们的服务器都是190G左右的大内存机器,如果G1GC使用得当,是否可以用LruCache取代BucketCache?
感觉BucketCache是CMS GC下的一种解决方案方案。回复
-
范欣欣
2018年8月22日上午9:14
可以实际测试一把看看两者的GC效果对比
回复
-
-
-
-
EASON
2018年8月15日下午8:41
请问你有用到哪些工具来方便统计GC吗
回复
-
范欣欣
2018年8月16日上午9:18
并没有用到什么工具都是体力活
-