【Java集合篇之Map】HashMap、HashTable、TreeMap、LinkedHashMap的区别以及应用场景
今天我向大家介绍Map接口中常用的四个集合类,先看看这几种实现类的类结构:
public class HashMap extends AbstractMap
implements Map, Cloneable, Serializable public class Hashtable
extends Dictionary
implements Map, Cloneable, java.io.Serializable public class LinkedHashMap
extends HashMap
implements Map public class TreeMap
extends AbstractMap
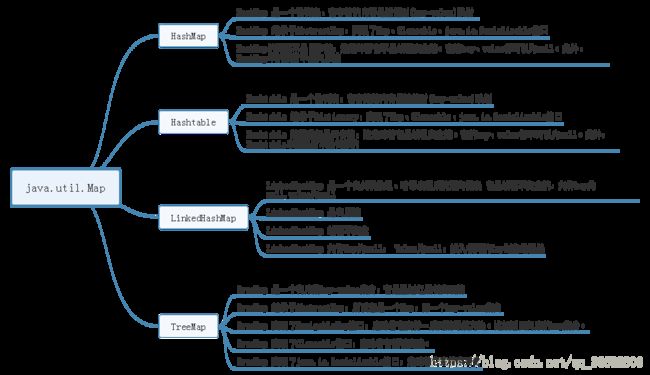
implements NavigableMap, Cloneable, java.io.Serializable 首先可以先看一下Map接口常用实现类的思维导图:
HashMap
HashMap 是一个最常用的Map,它根据键的HashCode 值存储数据,根据键可以直接获取它的值,具有很快的访问速度。遍历时,取得数据的顺序是完全随机的。HashMap最多只允许一条记录的键为Null;允许多条记录的值为 Null。
HashMap不支持线程的同步(即任一时刻可以有多个线程同时写HashMap),可能会导致数据的不一致。如果需要同步,可以用 Collections的synchronizedMap方法使HashMap具有同步的能力,或者使用ConcurrentHashMap。
Map这个相信只要写java的人都用过,无序,线程不安全。要注意的是jdk1.8以后hashMap源码 变了,底层优化了。以后要是面试官问你hashMap怎么存储,你就不能说按照数组存储节点,hash值相同时直接往后排列,相当于数组中对应的元素都是链表。这就错啦!!!jdk1.8之后添加了这个属性:

这个表示当相同hash值相同的元素大于8个时候,存储结构会变成红黑树来存储,方便查找,如下图所示:

测试代码如下:
package com.map.test;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class HashMapTest {
public static void main(String[] args) {
Map map = new HashMap<>();
for (int i = 0; i < 20; i++) {
map.put("test"+i, "test");
}
Iterator it = map.entrySet().iterator();
while (it.hasNext()){
Map.Entry entry = (Map.Entry)it.next();
System.out.println(entry.getKey());
}
}
} 输出结果:
D:\javaTools\jdk\jdk1.8\bin\java "-javaagent:D:\javaTools\IDEA\IDEA\IntelliJ IDEA 2017.3.4\lib\idea_rt.jar=57483:D:\javaTools\IDEA\IDEA\IntelliJ IDEA 2017.3.4\bin" -Dfile.encoding=UTF-8 -classpath D:\javaTools\jdk\jdk1.8\jre\lib\charsets.jar;D:\javaTools\jdk\jdk1.8\jre\lib\deploy.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\access-bridge-64.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\cldrdata.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\dnsns.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\jaccess.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\jfxrt.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\localedata.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\nashorn.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\sunec.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\sunjce_provider.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\sunmscapi.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\sunpkcs11.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\zipfs.jar;D:\javaTools\jdk\jdk1.8\jre\lib\javaws.jar;D:\javaTools\jdk\jdk1.8\jre\lib\jce.jar;D:\javaTools\jdk\jdk1.8\jre\lib\jfr.jar;D:\javaTools\jdk\jdk1.8\jre\lib\jfxswt.jar;D:\javaTools\jdk\jdk1.8\jre\lib\jsse.jar;D:\javaTools\jdk\jdk1.8\jre\lib\management-agent.jar;D:\javaTools\jdk\jdk1.8\jre\lib\plugin.jar;D:\javaTools\jdk\jdk1.8\jre\lib\resources.jar;D:\javaTools\jdk\jdk1.8\jre\lib\rt.jar;D:\workspace\idea_work\Map\out\production\Map com.map.test.HashMapTest
test16
test15
test14
test13
test12
test11
test10
test0
test1
test19
test18
test17
test4
test5
test2
test3
test8
test9
test6
test7
Process finished with exit code 0
从结果上很轻易看的出,HashMap是无序的(关于线程安全问题,以后有时间再写),线程安全这里要多说一点,其实除了HashTable之外,Map家族中还有Vector是线程安全的,并发容器有ConcurrentHashMap、ConcurrentSkipListMap等
HashTable
Hashtable与 HashMap类似,它继承自Dictionary类。不同的是:它不允许记录的键或者值为空;它支持线程的同步(即任一时刻只有一个线程能写Hashtable),因此也导致了 Hashtable在写入时会比较慢。
注:HashTable现在比较少见,我开发了几年从来没用过,但一些老程序员面试的时候经常会问,我们只需了解一些概念性的东西就好,不必深究。
LinkedHashMap
LinkedHashMap保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的。也可以在构造时带参数,按照应用次数排序。在遍历的时候会比HashMap慢,不过有种情况例外:当HashMap容量很大,实际数据较少时,遍历起来可能会比LinkedHashMap慢。因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
LinkedHashMap可以保存输入顺序,这点在key值为中文时候特别方便(虽然key值不建议为中文)。比如你现在要在页面中输出周一,周二,周三分别迟到的人数,测试代码如下:
package com.map.test;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapTest {
public static void main(String[] args) {
Map map = new LinkedHashMap<>();
map.put("星期一", 50);
map.put("星期二", 30);
map.put("星期三", 20);
Iterator it = map.entrySet().iterator();
while (it.hasNext()){
Map.Entry entry = (Map.Entry)it.next();
System.out.println(entry.getKey());
}
}
} 测试结果:
D:\javaTools\jdk\jdk1.8\bin\java "-javaagent:D:\javaTools\IDEA\IDEA\IntelliJ IDEA 2017.3.4\lib\idea_rt.jar=57555:D:\javaTools\IDEA\IDEA\IntelliJ IDEA 2017.3.4\bin" -Dfile.encoding=UTF-8 -classpath D:\javaTools\jdk\jdk1.8\jre\lib\charsets.jar;D:\javaTools\jdk\jdk1.8\jre\lib\deploy.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\access-bridge-64.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\cldrdata.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\dnsns.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\jaccess.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\jfxrt.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\localedata.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\nashorn.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\sunec.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\sunjce_provider.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\sunmscapi.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\sunpkcs11.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\zipfs.jar;D:\javaTools\jdk\jdk1.8\jre\lib\javaws.jar;D:\javaTools\jdk\jdk1.8\jre\lib\jce.jar;D:\javaTools\jdk\jdk1.8\jre\lib\jfr.jar;D:\javaTools\jdk\jdk1.8\jre\lib\jfxswt.jar;D:\javaTools\jdk\jdk1.8\jre\lib\jsse.jar;D:\javaTools\jdk\jdk1.8\jre\lib\management-agent.jar;D:\javaTools\jdk\jdk1.8\jre\lib\plugin.jar;D:\javaTools\jdk\jdk1.8\jre\lib\resources.jar;D:\javaTools\jdk\jdk1.8\jre\lib\rt.jar;D:\workspace\idea_work\Map\out\production\Map com.map.test.LinkedHashMapTest
星期一
星期二
星期三
Process finished with exit code 0
TreeMap
TreeMap实现SortMap接口,能够把它保存的记录根据键排序。默认是按键值的升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。
测试代码如下:
package com.map.test;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.TreeMap;
public class TreeMapTest {
public static void main(String[] args) {
Map map = new TreeMap<>();
for (int i = 0; i < 20; i++) {
map.put("test"+i, "test");
}
Iterator it = map.entrySet().iterator();
while (it.hasNext()){
Map.Entry entry = (Map.Entry)it.next();
System.out.println(entry.getKey());
}
}
} TreeMap会按照key值默认排序,这样会很方便我们操作。假设一个业务场景,你需要在页面输出过去两个月内每天门网站注册人数,这时候你就可以从数据库中取出值放入treeMap中,key用一个String的date,value用注册人数,然后遍历treemap就可以了.
测试结果:
D:\javaTools\jdk\jdk1.8\bin\java "-javaagent:D:\javaTools\IDEA\IDEA\IntelliJ IDEA 2017.3.4\lib\idea_rt.jar=57507:D:\javaTools\IDEA\IDEA\IntelliJ IDEA 2017.3.4\bin" -Dfile.encoding=UTF-8 -classpath D:\javaTools\jdk\jdk1.8\jre\lib\charsets.jar;D:\javaTools\jdk\jdk1.8\jre\lib\deploy.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\access-bridge-64.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\cldrdata.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\dnsns.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\jaccess.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\jfxrt.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\localedata.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\nashorn.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\sunec.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\sunjce_provider.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\sunmscapi.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\sunpkcs11.jar;D:\javaTools\jdk\jdk1.8\jre\lib\ext\zipfs.jar;D:\javaTools\jdk\jdk1.8\jre\lib\javaws.jar;D:\javaTools\jdk\jdk1.8\jre\lib\jce.jar;D:\javaTools\jdk\jdk1.8\jre\lib\jfr.jar;D:\javaTools\jdk\jdk1.8\jre\lib\jfxswt.jar;D:\javaTools\jdk\jdk1.8\jre\lib\jsse.jar;D:\javaTools\jdk\jdk1.8\jre\lib\management-agent.jar;D:\javaTools\jdk\jdk1.8\jre\lib\plugin.jar;D:\javaTools\jdk\jdk1.8\jre\lib\resources.jar;D:\javaTools\jdk\jdk1.8\jre\lib\rt.jar;D:\workspace\idea_work\Map\out\production\Map com.map.test.TreeMapTest
test0
test1
test10
test11
test12
test13
test14
test15
test16
test17
test18
test19
test2
test3
test4
test5
test6
test7
test8
test9
Process finished with exit code 0可以看出按照key值进行排序输出,主要原理是put函数内部使用了Comparator比较器。源码是下面这段代码:
i = comparator1.compare(obj, entry.key);
if (i < 0)
entry = entry.left;
else if (i > 0)
entry = entry.right;
else
return entry.setValue(obj1);