Pytorch可视化工具之TensorBoardX
1. 引言
我们都知道tensorflow框架可以使用tensorboard这一高级的可视化的工具,为了使用tensorboard这一套完美的可视化工具,未免可以将其应用到Pytorch中,用于Pytorch的可视化。这里特别感谢Github上的解决方案: https://github.com/lanpa/tensorboardX。
本文主要是针对该解决方案提供一些介绍。
TensorboardX支持scalar, image, figure, histogram, audio, text, graph, onnx_graph, embedding, pr_curve and videosummaries等不同的可视化展示方式,具体介绍移步至项目Github 观看详情
2. 环境依赖:
- python 3.6+
- Pytorch 0.4.0+
- tensorboardX: pip install tensorboardX、pip install tensorflow
3. 代码教程
TensorboardX可以提供中很多的可视化方式,本文主要介绍scalar 和 graph,其他类型相似。
3.1 可视化scalar
代码
import numpy as np
from tensorboardX import SummaryWriter
writer = SummaryWriter(log_dir='scalar')
for epoch in range(100):
writer.add_scalar('scalar/test', np.random.rand(), epoch)
writer.add_scalars('scalar/scalars_test', {'xsinx': epoch * np.sin(epoch), 'xcosx': epoch * np.cos(epoch)}, epoch)
writer.close()
对上述代码进行解释,首先导入:from tensorboardX import SummaryWriter,然后定义一个SummaryWriter()实例。在SummaryWriter()上鼠标ctrl+b我们可以看到SummaryWriter()的参数为:def __init__(self, log_dir=None, comment='', **kwargs): 其中log_dir为生成的文件所放的目录,comment为文件名称。默认目录为生成runs文件夹目录。我们运行上述代码:生成结果为:
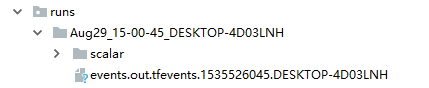
当我们为SummaryWriter(comment='base_scalar')。生成结果为:

当我们为SummaryWriter(log_dir='scalar') 添加log_dir参数,可以看到第二条数据的文件名称包括了base_scalar值。生成结果目录为:
接着解释writer.add_scalar('scalar/test', np.random.rand(), epoch),这句代码的作用就是,将我们所需要的数据保存在文件里面供可视化使用。 这里是Scalar类型,所以使用writer.add_scalar(),其他的队形使用对应的函数。第一个参数可以简单理解为保存图的名称,第二个参数是可以理解为Y轴数据,第三个参数可以理解为X轴数据。当Y轴数据不止一个时,可以使用writer.add_scalars().运行代码之后生成文件之后,我们在runs同级目录下使用命令行:tensorboard --logdir runs. 当SummaryWriter(log_dir='scalar')的log_dir的参数值 存在时,将tensorboard --logdir runs改为tensorboard --logdir 参数值。

最后调用writer.close()。
点击链接即可看到我们的最终需要的可视化结果。
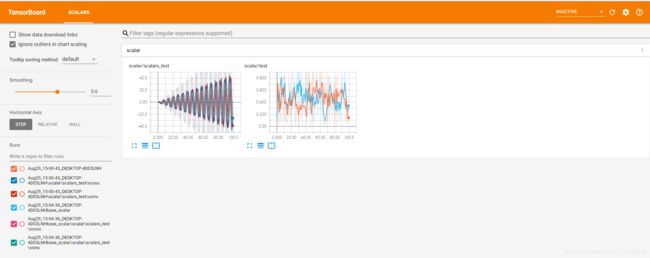
可以分别点击对应的图片查看详情。可以看到生成的Scalar名称为'scalar/test'与'scalar/test'一致。注:可以使用左下角的文件选择你想显示的某个或者全部图片。
3.2 可视化网络结构
代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from tensorboardX import SummaryWriter
class Net1(nn.Module):
def __init__(self):
super(Net1, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
self.bn = nn.BatchNorm2d(20)
def forward(self, x):
x = F.max_pool2d(self.conv1(x), 2)
x = F.relu(x) + F.relu(-x)
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = self.bn(x)
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
x = F.softmax(x, dim=1)
return x
dummy_input = torch.rand(13, 1, 28, 28)
model = Net1()
with SummaryWriter(comment='Net1') as w:
w.add_graph(model, (dummy_input,))
首先我们定义一个神经网络取名为Net1。然后将其添加到tensorboard可是可视化中。
with SummaryWriter(comment='Net1') as w:
w.add_graph(model, (dummy_input,))
我们重点关注最后两句话,其中使用了python的上下文管理,with 语句,可以避免因w.close()未写造成的问题。推荐使用此方式。
因为这是一个神经网络架构,所以使用 w.add_graph(model, (dummy_input,)),其中第一个参数为需要保存的模型,第二个参数为输入值,元祖类型(必须要有,只是需要给一个形式上的输入)。打开tensorvboard控制台,可得到如下结果。

点击Net1部分可以将其网络展开,查看网络内部构造。
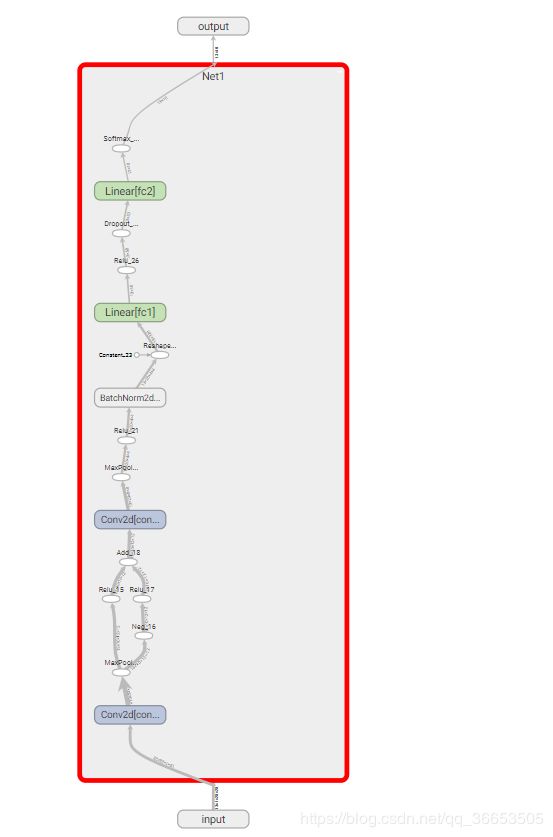
其他部分可以继续一次展开查看详情。
3.3 网络训练综合教程
解释完上述两部分知识之后,我们可以综合运用上述两部分内容,实现线性拟合的训练过程中的loss可视化和模型的保存。
import torch
import torch.nn as nn
from tensorboardX import SummaryWriter
import matplotlib.pyplot as plt
import numpy as np
input_size = 1
output_size = 1
num_epoches = 60
learning_rate = 0.01
writer = SummaryWriter(comment='Linear')
x_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168],
[9.779], [6.182], [7.59], [2.167], [7.042],
[10.791], [5.313], [7.997], [3.1]], dtype=np.float32)
y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573],
[3.366], [2.596], [2.53], [1.221], [2.827],
[3.465], [1.65], [2.904], [1.3]], dtype=np.float32)
model = nn.Linear(input_size, output_size)
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(num_epoches):
inputs = torch.from_numpy(x_train)
targets = torch.from_numpy(y_train)
output = model(inputs)
loss = criterion(output, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 保存loss的数据与epoch数值
writer.add_scalar('Train', loss, epoch)
if (epoch + 1) % 5 == 0:
print('Epoch {}/{},loss:{:.4f}'.format(epoch + 1, num_epoches, loss.item()))
# 将model保存为graph
writer.add_graph(model, (inputs,))
predicted = model(torch.from_numpy(x_train)).detach().numpy()
plt.plot(x_train, y_train, 'ro', label='Original data')
plt.plot(x_train, predicted, label='Fitted line')
plt.legend()
plt.show()
writer.close()
我们将运行过程中loss和model分别保存,最后打开tensorboard控制台,可以得到模型结果和loss的结果为下图。
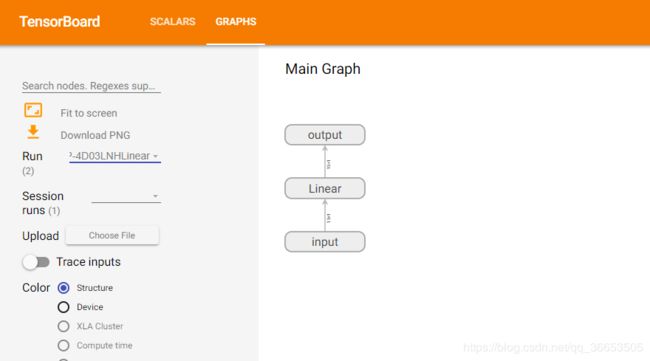
** 注:**不同的graph的可视化可以使用上图Run旁边的下拉框选择。
3.4 Tensorboard综合Demo
import torch
import torchvision.utils as vutils
import numpy as np
import torchvision.models as models
from torchvision import datasets
from tensorboardX import SummaryWriter
resnet18 = models.resnet18(False)
writer = SummaryWriter()
sample_rate = 44100
freqs = [262, 294, 330, 349, 392, 440, 440, 440, 440, 440, 440]
for n_iter in range(100):
dummy_s1 = torch.rand(1)
dummy_s2 = torch.rand(1)
# data grouping by `slash`
writer.add_scalar('data/scalar1', dummy_s1[0], n_iter)
writer.add_scalar('data/scalar2', dummy_s2[0], n_iter)
writer.add_scalars('data/scalar_group', {'xsinx': n_iter * np.sin(n_iter),
'xcosx': n_iter * np.cos(n_iter),
'arctanx': np.arctan(n_iter)}, n_iter)
dummy_img = torch.rand(32, 3, 64, 64) # output from network
if n_iter % 10 == 0:
x = vutils.make_grid(dummy_img, normalize=True, scale_each=True)
writer.add_image('Image', x, n_iter)
dummy_audio = torch.zeros(sample_rate * 2)
for i in range(x.size(0)):
# amplitude of sound should in [-1, 1]
dummy_audio[i] = np.cos(freqs[n_iter // 10] * np.pi * float(i) / float(sample_rate))
writer.add_audio('myAudio', dummy_audio, n_iter, sample_rate=sample_rate)
writer.add_text('Text', 'text logged at step:' + str(n_iter), n_iter)
for name, param in resnet18.named_parameters():
writer.add_histogram(name, param.clone().cpu().data.numpy(), n_iter)
# needs tensorboard 0.4RC or later
writer.add_pr_curve('xoxo', np.random.randint(2, size=100), np.random.rand(100), n_iter)
dataset = datasets.MNIST('mnist', train=False, download=True)
images = dataset.test_data[:100].float()
label = dataset.test_labels[:100]
features = images.view(100, 784)
writer.add_embedding(features, metadata=label, label_img=images.unsqueeze(1))
# export scalar data to JSON for external processing
writer.export_scalars_to_json("./all_scalars.json")
writer.close()
最终运行的所有可视化结果为:
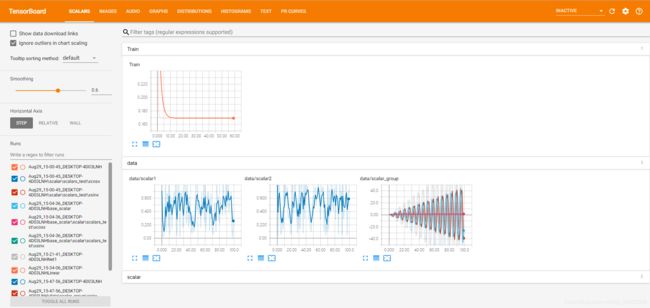
参考
https://www.jianshu.com/p/46eb3004beca