GGUF 大模型文件格式
1. 基础原理
GGUF 简介
当前的大模型的参数规模较大,数以千亿的参数导致了它们的预训练结果文件都在几十GB甚至是几百GB,这不仅导致其使用成本很高,在不同平台进行交换也非常困难。因此,大模型预训练结果文件的保存格式对于模型的使用和生态的发展来说极其重要。
大语言模型的开发通常使用PyTorch等框架,其预训练结果通常也会保存为相应的二进制格式,如pt后缀的文件通常就是PyTorch框架保存的二进制预训练结果。
但是,大模型的存储一个很重要的问题是它的模型文件巨大,而模型的结构、参数等也会影响模型的推理效果和性能。为了让大模型更加高效的存储和交换,就有了不同格式的大模型文件。其中,GGUF就是非常重要的一种大模型文件格式。
GGUF文件全称是GPT-Generated Unified Format,是由Georgi Gerganov定义发布的一种大模型文件格式。Georgi Gerganov是著名开源项目llama.cpp的创始人。
GGUF就是一种二进制格式文件的规范,原始的大模型预训练结果经过转换后变成GGUF格式可以更快地被载入使用,也会消耗更低的资源。原因在于GGUF采用了多种技术来保存大模型预训练结果,包括采用紧凑的二进制编码格式、优化的数据结构、内存映射等。
注意:llama.cpp官方提供了转换脚本,可以将pt格式的预训练结果以及safetensors模型文件转换成GGUF格式的文件。转换的时候也可以选择量化参数,降低模型的资源消耗。
GGUF格式的前身是GGML,也是同一个作者开发的,但是GGML格式因为种种限制目前被放弃。
GGUF 与 Safetensors 的区别
safetensors是一种由Hugging Face推出的新型的安全的模型存储格式。它特别关注模型的安全性和隐私保护,同时保证了加载速度。safetensors文件仅包含模型的权重参数,不包括执行代码,这有助于减少模型文件的大小并提高加载速度。此外,safetensors支持零拷贝(zero-copy)和懒加载(lazy loading),没有文件大小限制,并且支持bfloat16/fp8数据类型。但safetensors没有重点关注性能和跨平台交换。在大模型高效序列化、数据压缩、量化等方面存在不足,并且它只保存了张量数据,没有任何关于模型的元数据信息。
而gguf格式是一种针对大模型的二进制文件格式。专为GGML及其执行器快速加载和保存模型而设计。它是GGML格式的替代者,旨在解决GGML在灵活性和扩展性方面的限制。它包含加载模型所需的所有信息,无需依赖外部文件,这简化了模型部署和共享的过程,同时有助于跨平台操作。此外,GGUF还支持量化技术,可以降低模型的资源消耗,并且设计为可扩展的,以便在不破坏兼容性的情况下添加新信息。
总的来说,safetensors更侧重于安全性和效率,适合快速部署和对安全性有较高要求的场景,特别是在HuggingFace生态中。而gguf格式则是一种为大模型设计的二进制文件格式,优化了模型的加载速度和资源消耗,适合需要频繁加载不同模型的场景。
GGUF 特性
GGUF 是一种基于现有 GGJT 的格式(这种格式对张量进行对齐,以便能够使用内存映射(mmap)),但对该格式进行了一些更改,使其更具可扩展性且更易于使用。GGUF 具有如下特性:
- 单文件部署:它们可以轻松分发和加载,并且不需要任何外部文件来获取附加信息。
- 可扩展性:可以将新特征添加到基于 GGML 的执行器中/可以将新信息添加到 GGUF 模型中,而不会破坏与现有模型的兼容性。
-
mmap兼容性:可以使用mmap加载模型,以实现快速地加载和保存。 - 易于使用:无论使用何种语言,都可以使用少量代码轻松加载和保存模型,无需外部库。
- 信息完整:加载模型所需的所有信息都包含在模型文件中,用户不需要提供任何额外的信息。这大大简化了模型部署和共享的流程。
GGJT 和 GGUF 之间的主要区别在于:超参数(现称为元数据)使用键值结构,而不是非类型化的值列表。这允许在不破坏与现有模型的兼容性的情况下添加新的元数据,这使得可以添加对推理或识别模型有用的附加信息来注释模型。
2. GGUF文件组成与格式

- 文件头 (Header)
- 包含用于识别文件类型和版本的基本信息
- 内容:
-
Magic Number:一个特定的数字或字符序列,用于标识文件格式 -
Version:文件格式的版本号,指明了文件遵循的具体规范或标准
-
- 元数据键值对 (Metadata Key-Value Pairs)
- 存储关于模型的额外信息,如作者、训练信息、模型描述等
- 内容:
-
Key:一个字符串,标识元数据的名称 -
Value Type:数据类型,指明值的格式(如整数、浮点数、字符串等) -
Value:具体的元数据内容
-
- 张量计数 (Tensor Count)
- 作用:标识文件中包含的张量(Tensor)数量
- 内容:
-
Count:一个整数,表示文件中张量的总数
- 张量信息 (Tensor Info)
- 作用:描述每个张量的具体信息,包括形状、类型和数据位置
- 内容:
-
Name:张量的名称 -
Dimensions:张量的维度信息 -
Type:张量数据的类型(如浮点数、整数等) -
Offset:指明张量数据在文件中的位置
- 对齐填充 (Alignment Padding)
- 作用:确保数据块在内存中正确对齐,有助于提高访问效率
- 内容:通常是一些填充字节,用于保证后续数据的内存对齐
- 张量数据 (Tensor Data)
- 作用:存储模型的实际权重和参数
- 内容:
Binary Data:模型的权重和参数的二进制表示
- 端序标识 (Endianness)
- 作用:指示文件中数值数据的字节顺序(大端或小端)
- 内容:通常是一个标记,表明文件遵循的端序
- 扩展信息 (Extension Information)
- 作用:允许文件格式未来扩展,以包含新的数据类型或结构
- 内容:可以是新加入的任何额外信息,为将来的格式升级预留空间
在张量信息部分,GGUF定义了模型的量化级别。量化级别取决于模型根据质量和准确性定义的值(ggml_type)。在 GGUF 规范中,值列表如下:
| 类型 |
描述 |
| F64 |
64 位标准 IEEE 754 双精度浮点数 |
| I64 |
64 位定长整数 |
| F32 |
32 位标准 IEEE 754 单精度浮点数 |
| I32 |
32 位定长整数 |
| F16 |
16 位标准 IEEE 754 半精度浮点数 |
| BF16 |
32 位 IEEE 754 单精度浮点数的 16 位缩短版本 |
| I16 |
16 位定长整数 |
| Q8_0 |
8 位 RTN (四舍五入)量化 (q),每个块有 32 个权重。权重公式: w = q * block_scale. 传统的量化方法 |
| Q8_1 |
8 位 RTN 量化 (q),每个块有 32 个权重。权重公式: w = q * block_scale + block_minimum. 传统的量化方法 |
| Q8_K |
8 位量化(q),每个块有 256 个权重。 仅用于量化中间结果。所有 2-6 位点积都是为此量化类型实现的。权重公式: w = q * block_scale |
| I8 |
8 位定长整数 |
| Q6_K |
6 位量化 (q),超级块有 16 个块,每个块有 16 个权重。权重公式: w = q * block_scale(8-bit),得出每个权重 6.5625 位 |
| Q5_0 |
5 位 RTN 量化 (q),每个块有 32 个权重。权重公式: w = q * block_scale. 传统的量化方法 |
| Q5_1 |
5 位 RTN 量化 (q),每个块有 32 个权重。权重公式: w = q * block_scale + block_minimum. 传统的量化方法 |
| Q5_K |
5 位量化 (q),超级块有8个块,每个块有32个权重。权重公式: w = q * block_scale(6-bit) + block_min(6-bit),得出每个权重 5.5 位 |
| Q4_0 |
4 位 RTN 量化 (q),每个块有 32 个权重。权重公式: w = q * block_scale. 传统的量化方法 |
| Q4_1 |
4 位 RTN 量化 (q),每个块有 32 个权重。权重公式:w = q * block_scale + block_minimum. 传统的量化方法 |
| Q4_K |
4 位量化 (q),超级块有8个块,每个块有32个权重。权重公式: w = q * block_scale(6-bit) + block_min(6-bit) ,得出每个权重 4.5 位 |
| Q3_K |
3 位量化 (q),超级块有 16 个块,每个块有 16 个权重。权重公式: w = q * block_scale(6-bit), 得出每个权重3.4375 位 |
| Q2_K |
2 位量化 (q),超级块有 16 个块,每个块有 16 个权重。权重公式: w = q * block_scale(4-bit) + block_min(4-bit),得出每个权重 2.5625 位 |
| IQ4_NL |
4 位量化 (q),超级块有 256 个权重。权重w是使用super_block_scale和importance matrix获得的。 |
| IQ4_XS |
4 位量化 (q),超级块有 256 个权重。 权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 4.25 位 |
| IQ3_S |
3 位量化 (q),超级块有 256 个权重。 权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 3.44 位 |
| IQ3_XXS |
3 位量化 (q),超级块有 256 个权重。 权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 3.06 位 |
| IQ2_XXS |
2 位量化 (q),超级块有 256 个权重。 权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 2.06 位 |
| IQ2_S |
2 位量化 (q),超级块有 256 个权重。 权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 2.5 位 |
| IQ2_XS |
2 位量化 (q),超级块有 256 个权重。 权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 2.31 位 |
| IQ1_S |
1 位量化 (q),超级块有 256 个权重。 权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 1.56 位 |
| IQ1_M |
1 位量化 (q),超级块有 256 个权重。 权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 1.75 位 |
GGUF 自身又有多种格式,主要区别在于浮点数的位数和量化的方式。
不同的格式会影响模型的大小、性能和精度,一般来说,位数越少,量化越多,模型越小,速度越快,但是精度也越低。
在HuggingFace中可以看到如下格式:
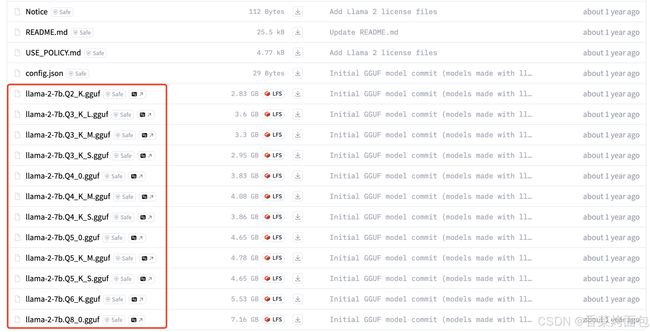
命名解释:“Q”+用于存储权重(精度)的位数+特定变体
- Q(Quantization)
- Q2、Q3、Q4、Q5、Q6 分别表示模型的量化位数。例如,Q2 表示 2 位量化,Q3 表示 3 位量化,以此类推
- 量化位数越高,模型的精度损失就越小,但同时模型的大小和计算需求也会增加
- 特定变体:量化方案的类型,采用了不同的量化方案来处理 attention.wv、attention.wo 和 feed_forward.w2 张量,量化方案见上表
- q2_k: Uses Q4_K for the attention.vw and feed_forward.w2 tensors, Q2_K for the other tensors
- q3_k_l: Uses Q5_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else Q3_K
- q3_k_m: Uses Q4_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else Q3_K
- q3_k_s: Uses Q3_K for all tensors
- q4_0: Original quant method, 4-bit
- q4_1: Higher accuracy than q4_0 but not as high as q5_0. However has quicker inference than q5 models
- q4_k_m: Uses Q6_K for half of the attention.wv and feed_forward.w2 tensors, else Q4_K
- q4_k_s: Uses Q4_K for all tensors
-
q5_0: Higher accuracy, higher resource usage and slower inference
- q5_1: Even higher accuracy, resource usage and slower inference
- q5_k_m: Uses Q6_K for half of the attention.wv and feed_forward.w2 tensors, else Q5_K
- q5_k_s: Uses Q5_K for all tensors
- q6_k: Uses Q8_K for all tensors
- q8_0: Almost indistinguishable from float16. High resource use and slow. Not recommended for most users
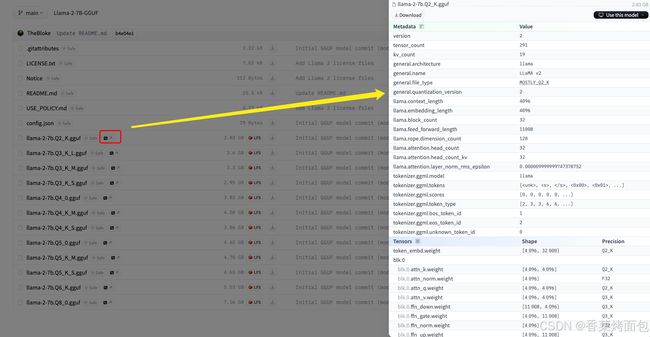
HuggingFace 已经对 GGUF 格式提供了支持。同时,HuggingFace 开发了一个脚本(huggingface.js/packages/gguf at main · huggingface/huggingface.js · GitHub)可以用来解析 HuggingFace Hub 上 GGUF 格式的模型的信息。并且可以直接在HF平台上对GGUF的元数据进行预览,包括模型的架构、具体参数等:
3. 转换与量化方法
如何将模型转换为 GGUF 格式?
方法1: Huggingface工具
Huggingface 上可以通过 GGUF 标签浏览所有带有 GGUF 文件的模型:https://huggingface.co/models?library=gguf
Huggingface Hub上面提供了将模型转化或者量化为 GGUF 格式的工具:https://huggingface.co/spaces/ggml-org/gguf-my-repo
方法2: Llama.cpp
- llama.cpp 是一个轻量级、高效的开源推理引擎,用于运行 LLaMA(Large Language Model Meta AI)模型
- llama.cpp 使用 C++ 编写,能够在没有 GPU 的情况下,在普通 CPU 上高效运行大型语言模型
- llama.cpp 原生不支持直接加载或推理 .safetensors 格式的模型,它主要支持基于 LLaMA 模型的 GGML/GGUF 格式(通过量化和优化后的模型格式)
以Qwen1.5-1.8B模型为例:
下载模型
下载:Qwen1.5-1.8B
下载 Llama.cpp
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
make
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simpleSafetensors2GGUF
转换模型至未量化的版本,后续可以转成不同的量化模式:
python convert_hf_to_gguf.py /workspace/Qwen/Qwen1___5-1___8B/ --outfile /workspace/Qwen/Qwen1_5-1_8B.gguf注意⚠️:convert_hf_to_gguf.py 也可以指定--outtype (choose from 'f32', 'f16', 'bf16', 'q8_0', 'tq1_0', 'tq2_0', 'auto')
量化
make 编译完后有一个 llama-quantize 可执行文件
对生成的GGUF模型按照指定精度量化(例:Q4_K_M):
./llama-quantize /workspace/Qwen/Qwen1_5-1_8B.gguf /workspace/Qwen/Qwen1_5-1_8B-Q4_K_M.gguf Q4_K_M注意⚠️:--outtype是输出类型:
- q2_k:特定张量 (Tensor) 采用较高的精度设置,而其他的则保持基础级别
- q3_k_l、q3_k_m、q3_k_s:在不同张量上使用不同级别的精度,从而达到性能和效率的平衡
- q4_0:最初的量化方案,使用 4 位精度
- q4_1和q4_k_m、q4_k_s:提供了不同程度的准确性和推理速度,适合需要平衡资源使用的场景
- q5_0、q5_1、q5_k_m、q5_k_s:在保证更高准确度的同时,会使用更多的资源并且推理速度较慢
- q6_k和q8_0:提供了最高的精度,资源消耗高、速度慢
- fp16 和 f32:不量化,保留原始精度
可以查看:
./llama-quantize -h
# 输出
Allowed quantization types:
2 or Q4_0 : 4.34G, +0.4685 ppl @ Llama-3-8B
3 or Q4_1 : 4.78G, +0.4511 ppl @ Llama-3-8B
8 or Q5_0 : 5.21G, +0.1316 ppl @ Llama-3-8B
9 or Q5_1 : 5.65G, +0.1062 ppl @ Llama-3-8B
19 or IQ2_XXS : 2.06 bpw quantization
20 or IQ2_XS : 2.31 bpw quantization
28 or IQ2_S : 2.5 bpw quantization
29 or IQ2_M : 2.7 bpw quantization
24 or IQ1_S : 1.56 bpw quantization
31 or IQ1_M : 1.75 bpw quantization
36 or TQ1_0 : 1.69 bpw ternarization
37 or TQ2_0 : 2.06 bpw ternarization
10 or Q2_K : 2.96G, +3.5199 ppl @ Llama-3-8B
21 or Q2_K_S : 2.96G, +3.1836 ppl @ Llama-3-8B
23 or IQ3_XXS : 3.06 bpw quantization
26 or IQ3_S : 3.44 bpw quantization
27 or IQ3_M : 3.66 bpw quantization mix
12 or Q3_K : alias for Q3_K_M
22 or IQ3_XS : 3.3 bpw quantization
11 or Q3_K_S : 3.41G, +1.6321 ppl @ Llama-3-8B
12 or Q3_K_M : 3.74G, +0.6569 ppl @ Llama-3-8B
13 or Q3_K_L : 4.03G, +0.5562 ppl @ Llama-3-8B
25 or IQ4_NL : 4.50 bpw non-linear quantization
30 or IQ4_XS : 4.25 bpw non-linear quantization
15 or Q4_K : alias for Q4_K_M
14 or Q4_K_S : 4.37G, +0.2689 ppl @ Llama-3-8B
15 or Q4_K_M : 4.58G, +0.1754 ppl @ Llama-3-8B
17 or Q5_K : alias for Q5_K_M
16 or Q5_K_S : 5.21G, +0.1049 ppl @ Llama-3-8B
17 or Q5_K_M : 5.33G, +0.0569 ppl @ Llama-3-8B
18 or Q6_K : 6.14G, +0.0217 ppl @ Llama-3-8B
7 or Q8_0 : 7.96G, +0.0026 ppl @ Llama-3-8B
33 or Q4_0_4_4 : 4.34G, +0.4685 ppl @ Llama-3-8B
34 or Q4_0_4_8 : 4.34G, +0.4685 ppl @ Llama-3-8B
35 or Q4_0_8_8 : 4.34G, +0.4685 ppl @ Llama-3-8B
1 or F16 : 14.00G, +0.0020 ppl @ Mistral-7B
32 or BF16 : 14.00G, -0.0050 ppl @ Mistral-7B
0 or F32 : 26.00G @ 7B
COPY : only copy tensors, no quantizing4. 量化后 GGUF 模型部署
Llama.cpp
使用 Llama.cpp 运行 GGUF 模型,llama-cli 提供多种“模式”来与模型进行“交互”
对话模式
# 参数解释:
# -m 或 –model:模型路径
# -co 或 –color:为输出着色以区分提示词、用户输入和生成的文本
# -cnv 或 –conversation:在对话模式下运行
# -p 或 –prompt:在对话模式下的提示词
# -fa 或 –flash-attn:支持 GPU,则启用Flash Attention注意力
# -ngl 或 –n-gpu-layers:支持 GPU,则将这么多层分配给 GPU 进行计算
# -n 或 –predict:要预测的token数量
# ./llama-cli -h 可以查看其他选项
./llama-cli -m /workspace/Qwen/Qwen1_5-1_8B-Q4_K_M.gguf \
-co -cnv -p "You are Qwen, created by Alibaba Cloud. You are a helpful assistant." \
-fa -ngl 80 -n 512首先会在屏幕上打印元数据,然后就可以输入prompt与模型进行对话(Ctrl+C退出)
互动模式
流程如下:
- 给模型一个初始提示,模型会生成续写文本
- 随时中断模型生成,或者等到模型生成反向提示(reverse prompt)或结束token(eos token)
- 添加新文本(可选前缀和后缀),然后让模型继续生成
- 重复步骤2和步骤3
# 参数解释:
# -sp 或 –special:显示特殊token
# -i 或 –interactive:进入互动模式,可以中断模型生成并添加新文本
# -if 或 –interactive-first:立即等待用户输入,否则,模型将立即运行并根据提示生成文本
# -p 或 –prompt:模型续写用的上文
# --in-prefix:用户输入附加的前缀字符串
# --in-suffix:用户输入附加的后缀字符串
./llama-cli -m /workspace/Qwen/Qwen1_5-1_8B-Q4_K_M.gguf \
-co -sp -i -if -p "<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n" \
--in-prefix "<|im_start|>user\n" --in-suffix "<|im_end|>\n<|im_start|>assistant\n" \
-fa -ngl 80 -n 512非交互模式
需要正确格式化输入,并且只能生成一次回应:
./llama-cli -m /workspace/Qwen/Qwen1_5-1_8B-Q4_K_M.gguf \
-co -sp -p "<|im_start|>system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\n<|im_start|>user\ngive me a short introduction to LLMs.<|im_end|>\n<|im_start|>assistant\n" \
-fa -ngl 80 -n 512llama-cpp-python
使用 llama-cpp-python(GitHub - abetlen/llama-cpp-python: Python bindings for llama.cpp):
from llama_cpp import Llama
llm = Llama(
model_path="/workspace/Qwen/Qwen1_5-1_8B-Q4_K_M.gguf",
n_gpu_layers=-1, # Use GPU acceleration
)
output = llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are an assistant who perfectly describes images."},
{
"role": "user",
"content": "give me a short introduction to LLMs."
}
]
)
print(output)