任务(作业)调度框Quartz在SSM中的使用总结
注意,本文不是详解Quartz基础原理,而是Quartz在ssm项目的基础应用,和ssm实战无关的概念直接略过,提到的都是项目中最常见的东西!!!
Quartz可以用来做什么?
Quartz是一个任务调度框架,也可以叫做定时任务。比如你遇到这样的问题
- 想每月25号,信用卡自动还款
- 想每年4月1日自己给当年暗恋女神发一封匿名贺卡
- 想每隔1小时,备份一下自己的爱情动作片 学习笔记到云盘
这些问题总结起来就是:我们希望在某一个有规律的时间点干某件事,但是触发时间非常复杂(比如每月最后一个工作日的17:50),所以出现了一个专门的框架来干这个事。 Quartz就是来干这样的事,你给它一个触发时间,它负责到了时间点,触发相应的Job起来干活。
Quartz最重要的3个基本要素
- Scheduler:调度器。所有的调度都是由它控制。
- Trigger: 定义触发时间。
SimpleTrigger:在给定时间触发,重复N次,且每次执行延迟相同时间的任务。
CronTrigger(一般只用这个):按照Cron表达式触发,例如“每个周五”,每个月10日中午或者10:15分。
- JobDetail & Job: JobDetail 定义的是任务描述,而真正的执行逻辑是在Job中,为什么设计成JobDetail + Job,不直接使用Job?这是因为任务是有可能并发执行,如果Scheduler直接使用Job,就会存在对同一个Job实例并发访问的问题。而JobDetail & Job 方式,sheduler每次执行,都会根据JobDetail创建一个新的Job实例,这样就可以规避并发访问的问题。
三要素的存储方式 (其实就是把三要素的信息都存到数据库的不同表中)
| JDBCJobStore | 支持集群,因为所有的任务信息都会保存到数据库中,如果应用服务器关闭或者重启,任务信息都不会丢失,并且可以恢复因服务器关闭或者重启而导致执行失败的任务 | 运行速度的快慢取决与连接数据库的快慢 |
表关系和解释
-
表关系
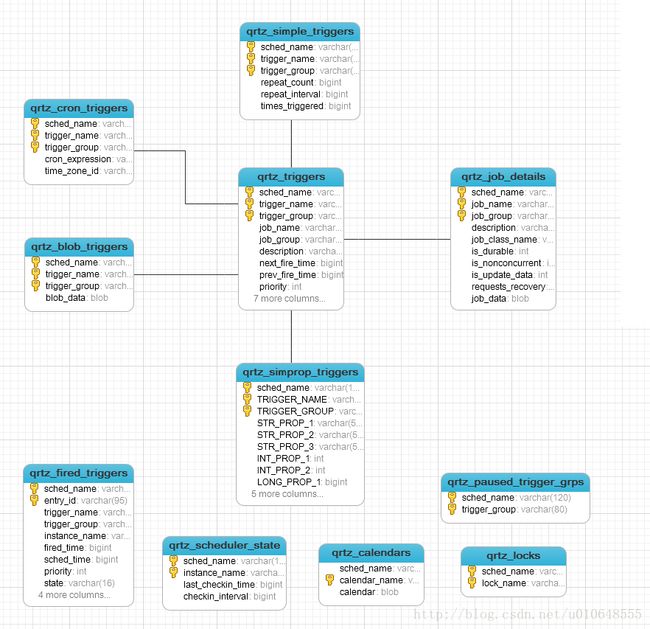
-
解释
| 表名称 | 说明 |
|---|---|
| qrtz_blob_triggers | Trigger作为Blob类型存储(用于Quartz用户用JDBC创建他们自己定制的Trigger类型,JobStore 并不知道如何存储实例的时候) |
| qrtz_calendars | 以Blob类型存储Quartz的Calendar日历信息, quartz可配置一个日历来指定一个时间范围 |
| qrtz_cron_triggers(最常用) | 存储Cron Trigger,包括Cron表达式和时区信息。 |
| qrtz_fired_triggers(最常用) | 存储与已触发的Trigger相关的状态信息,以及相联Job的执行信息 |
| qrtz_job_details(最常用) | 存储每一个已配置的Job的详细信息 |
| qrtz_locks(最常用) | 存储程序的悲观锁的信息(假如使用了悲观锁) |
| qrtz_paused_trigger_graps | 存储已暂停的Trigger组的信息 |
| qrtz_scheduler_state | 存储少量的有关 Scheduler的状态信息,和别的 Scheduler 实例(假如是用于一个集群中) |
| qrtz_simple_triggers | 存储简单的 Trigger,包括重复次数,间隔,以及已触的次数 |
| qrtz_triggers | 存储已配置的 Trigger的信息 |
| qrzt_simprop_triggers |
Quartz框架的核心类以及三要素之间联系
- 核心类
QuartzSchedulerThread :负责执行向QuartzScheduler注册的触发Trigger的工作的线程。
ThreadPool:Scheduler使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程提供运行效率。
QuartzSchedulerResources:包含创建QuartzScheduler实例所需的所有资源(JobStore,ThreadPool等)。
SchedulerFactory :提供用于获取调度程序实例的客户端可用句柄的机制。
JobStore: 通过类实现的接口,这些类要为org.quartz.core.QuartzScheduler的使用提供一个org.quartz.Job和org.quartz.Trigger存储机制。任务和触发器的存储应该以其名称和组的组合为唯一性。
QuartzScheduler :这是Quartz的核心,它是org.quartz.Scheduler接口的间接实现,包含调度org.quartz.Jobs,注册org.quartz.JobListener实例等的方法。
Scheduler :这是Quartz Scheduler的主要接口,代表一个独立运行容器。调度程序维护JobDetails和触发器的注册表。 一旦注册,调度程序负责执行任务,当他们的相关联的触发器触发(当他们的预定时间到达时)。
Trigger :具有所有触发器通用属性的基本接口,描述了job执行的时间出发规则。 - 使用TriggerBuilder实例化实际触发器。
JobDetail :传递给定任务实例的详细信息属性。 JobDetails将使用JobBuilder创建/定义。
Job:要由表示要执行的“任务”的类实现的接口。只有一个方法 void execute(jobExecutionContext context)
(jobExecutionContext 提供调度上下文各种信息,运行时数据保存在jobDataMap中)
Job有个子接口StatefulJob ,代表有状态任务。
有状态任务不可并发,前次任务没有执行完,后面任务处于阻塞等到。 - 联系

前提、每个定时任务都是一个线程,这些线程都在quartz的线程池中。
第一步、job和trigger必须先要注册在scheduler中。
第二步、scheduler调用注册的trigger。
第三步、trigger被唤醒,调用job,开始执行。
一个job可以被多个Trigger 绑定,但是一个Trigger只能绑定一个job!
配置文件
quartz.properties
//调度标识名 集群中每一个实例都必须使用相同的名称 (区分特定的调度器实例)
org.quartz.scheduler.instanceName:DefaultQuartzScheduler
//ID设置为自动获取 每一个必须不同 (所有调度器实例中是唯一的)
org.quartz.scheduler.instanceId :AUTO
//数据保存方式为持久化
org.quartz.jobStore.class :org.quartz.impl.jdbcjobstore.JobStoreTX
//表的前缀
org.quartz.jobStore.tablePrefix : QRTZ_
//设置为TRUE不会出现序列化非字符串类到 BLOB 时产生的类版本问题
//org.quartz.jobStore.useProperties : true
//加入集群 true 为集群 false不是集群
org.quartz.jobStore.isClustered : false
//调度实例失效的检查时间间隔
org.quartz.jobStore.clusterCheckinInterval:20000
//容许的最大任务延长时间
org.quartz.jobStore.misfireThreshold :60000
//ThreadPool 实现的类名
org.quartz.threadPool.class:org.quartz.simpl.SimpleThreadPool
//线程数量
org.quartz.threadPool.threadCount : 10
//线程优先级
org.quartz.threadPool.threadPriority : 5(threadPriority 属性的最大值是常量 java.lang.Thread.MAX_PRIORITY,等于10。最小值为常量 java.lang.Thread.MIN_PRIORITY,为1)
//自创建父线程
//org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread: true
//数据库别名
org.quartz.jobStore.dataSource : qzDS
//设置数据源
org.quartz.dataSource.qzDS.driver:com.mysql.jdbc.Driver
org.quartz.dataSource.qzDS.URL:jdbc:mysql://localhost:3306/quartz
org.quartz.dataSource.qzDS.user:root
org.quartz.dataSource.qzDS.password:123456
org.quartz.dataSource.qzDS.maxConnection:10
7.JDBC插入表顺序
主要的JDBC操作类,执行sql顺序。
Simple_trigger :插入顺序
qrtz_job_details —> qrtz_triggers —> qrtz_simple_triggers
qrtz_fired_triggers
Cron_Trigger:插入顺序
qrtz_job_details —> qrtz_triggers —> qrtz_cron_triggers
qrtz_fired_triggers
Quartz的基本运用
ssm项目结构没有变化,只是想在ssm中使用Quartz需要(MAVEN导包就不多说了):
1、在实体类包中建两个POJO
2、新建一个job包,里边放任务逻辑类,这个job类必须实现job接口,很特别
3、在service层和平时一样写业务逻辑,关于Quartz的service代码在下面贴了个通用DEMO
4、控制层调用就不多说了
5、添加quartz.properties配置文件
6、在spring的xml配置文件里加以下内容

public class HelloWorldJob implements Job{
private final static Logger logger = LoggerFactory.getLogger(HelloWorldJob.class);
/**
* "0/10 * * * * ?
*/
@Override
//只需实现这个方法就行
public void execute(JobExecutionContext arg0) throws JobExecutionException {
logger.info("----hello world---" + new Date());
}
}@Service("quartzService")
public class QuartzServiceImpl implements QuartzService {
@Autowired
private Scheduler quartzScheduler;
@Override
public void addJob(String jobName, String jobGroupName, String triggerName,
String triggerGroupName, Class cls, String cron) {
try {
// 获取调度器
Scheduler sched = quartzScheduler;
// 创建一项任务
JobDetail job = JobBuilder.newJob(cls)
.withIdentity(jobName, jobGroupName).build();
// 创建一个触发器
CronTrigger trigger = TriggerBuilder.newTrigger()
.withIdentity(triggerName, triggerGroupName)
.withSchedule(CronScheduleBuilder.cronSchedule(cron))
.build();
// 告诉调度器使用该触发器来安排任务
sched.scheduleJob(job, trigger);
// 启动
if (!sched.isShutdown()) {
sched.start();
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
细说三要素API(基本操作,会了就可以上手项目了)
一、Scheduler实例的骚操作(没有顺序)
1、获取调度器
@Autowired
private Scheduler quartzScheduler;
// 获取调度器
Scheduler sched = quartzScheduler;2、告诉调度器使用该触发器来安排任务,相当于初始化了一个调度器
sched.scheduleJob(JobDetail , Trigger);
/ / 能初始化,也能格式化清零
sched.unscheduleJob(triggerKey); // 移除触发器
sched.deleteJob(jobKey); // 删除任务
3、使调度器开始执行,我们的最终目标
sched.start()
/ / 与之对应,能开就能关,也必须要关,不然占着线程池,其他任务就无法进行了
sched.shutdown();
// 启动
if (!sched.isShutdown()) {
sched.start();
}4、如果只是想让定时任务先挂起,而不是彻底销毁
/ / 这个不是完全关闭,只是暂停,还在线程池中占着坑,只不过变成等待状态(多线程知识)
sched.pauseTrigger(triggerKey);
/ / 当然,能暂停就能重新开启,重新唤醒线程
sched.resumeTrigger(TriggerKey.triggerKey(triggerName, triggerGroupName));
5、通过调度器获取触发器和任务信息
CronTrigger trigger = (CronTrigger) sched.getTrigger(TriggerKey.triggerKey(triggerName, triggerGroup));
JobDetail job = sched.getJobDetail(JobKey.jobKey(jobName, jobGroup));
二、JobDetail实例的骚操作(没有顺序)
1、JobDetail实例的最常用,也是最关键的操作,只有一个,初始化!!!!
JobDetail job=JobBuilder.newJob() //初始化任务第一步 必写!!
.ofType(DoNothingJob.class) //引用Job Class 必写!!
.withIdentity("job1", "group1") //设置name/group 必写!!
.withDescription("this is a test job") //设置描述,数据库表里就有一列描述栏
.usingJobData("age", 18) //加入属性到age到JobDataMap,后边会解释
.build(); //大功告成2、这里要引入一个比较常见,也是比较重要的概念,学完这个就job类就ok了!!!!!
Quartz调度一次任务,会干如下的事:
- JobClass jobClass=JobDetail.getJobClass()
- Job jobInstance=jobClass.newInstance()。所以Job实现类,必须有一个public的无参构建方法。
- jobInstance.execute(JobExecutionContext context)。JobExecutionContext是Job运行的上下文,可以获得Trigger、Scheduler、JobDetail的信息。
也就是说,每次调度都会创建一个新的Job实例,这样的好处是有些任务并发执行的时候,不存在对临界资源的访问问题——当然,如果需要共享JobDataMap的时候,还是存在临界资源的并发访问的问题。
JobDataMap
每次调度任务,Job都是用无参构造器创建的一个新实例,那我怎么传值给它? 比如我现在有两个发送邮件的任务,一个是发给"liLei",一个发给"hanmeimei",不能说我要新写两个Job实现类LiLeiSendEmailJob和HanMeiMeiSendEmailJob。实现的办法是通过JobDataMap。
每一个JobDetail都会有一个JobDataMap。JobDataMap本质就是一个Map的扩展类。
我们可以在定义JobDetail,加入属性值,方式有二:
newJob().usingJobData("age", 18) //加入属性到ageJobDataMap
or
job.getJobDataMap().put("name", "quertz"); //加入属性name到JobDataMap然后在Job中可以获取这个JobDataMap的值,方式同样有二:
public class HelloQuartz implements Job {
private String name;
public void execute(JobExecutionContext context) throws JobExecutionException {
JobDetail detail = context.getJobDetail();
JobDataMap map = detail.getJobDataMap(); //方法一:获得JobDataMap
System.out.println("say hello to " + name + "[" + map.getInt("age") + "]" + " at "
+ new Date());
}
//方法二:属性的setter方法,会将JobDataMap的属性自动注入
public void setName(String name) {
this.name = name;
}
}对于同一个JobDetail实例,可能对应的是多个Job实例,但是共享同样的JobDataMap,也就是说,如果你在任务里修改了里面的值,会对其他Job实例(并发的或者后续的)造成影响。
除了JobDetail,Trigger同样有一个JobDataMap,共享范围是所有使用这个Trigger的Job实例。
二、trigger实例的骚操作(没有顺序)
1、和JobDetail一样,最常用,也是最关键的操作,只有一个,初始化!!!!
AnnualCalendar cal = new AnnualCalendar();
//定义一个每年执行Calendar,精度为天,即不能定义到2.25号下午2:00
java.util.Calendar excludeDay = new GregorianCalendar();
excludeDay.setTime(newDate().inMonthOnDay(2, 25).build());
cal.setDayExcluded(excludeDay, true); //设置排除2.25这个日期
scheduler.addCalendar("FebCal", cal, false, false); //scheduler加入这个Calendar
//这些都是选写
CronTrigger trigger = TriggerBuilder.newTrigger() //初始化开始
.withIdentity(triggerName, triggerGroupName) //必写
.startNow()//一旦加入scheduler,立即生效 选写
.modifiedByCalendar("FebCal") //使用Calendar !! 选写
.withSchedule(CronScheduleBuilder.cronSchedule("0 0/2 8-17 * * ?"))
//必写
.build(); //大功告成2、trigger其中涉及了一些重要属性,可以看看数据库的qrtz_triggers的表结构,这些东西其实就是成员变量
StartTime & EndTime
startTime和endTime指定的Trigger会被触发的时间区间。在这个区间之外,Trigger是不会被触发的。
** 所有Trigger都会包含这两个属性 **
优先级(Priority)
当scheduler比较繁忙的时候,可能在同一个时刻,有多个Trigger被触发了,但资源不足(比如线程池不足)。那么这个时候比剪刀石头布更好的方式,就是设置优先级。优先级高的先执行。
需要注意的是,优先级只有在同一时刻执行的Trigger之间才会起作用,如果一个Trigger是9:00,另一个Trigger是9:30。那么无论后一个优先级多高,前一个都是先执行。
优先级的值默认是5,当为负数时使用默认值。最大值似乎没有指定,但建议遵循Java的标准,使用1-10,不然鬼才知道看到【优先级为10】是时,上头还有没有更大的值。
Misfire(错失触发)策略
类似的Scheduler资源不足的时候,或者机器崩溃重启等,有可能某一些Trigger在应该触发的时间点没有被触发,也就是Miss Fire了。这个时候Trigger需要一个策略来处理这种情况。每种Trigger可选的策略各不相同。
这里有两个点需要重点注意:
- MisFire的触发是有一个阀值,这个阀值是配置在JobStore的。比RAMJobStore是org.quartz.jobStore.misfireThreshold。只有超过这个阀值,才会算MisFire。小于这个阀值,Quartz是会全部重新触发。
所有MisFire的策略实际上都是解答两个问题:
- 已经MisFire的任务还要重新触发吗?
- 如果发生MisFire,要调整现有的调度时间吗?
MisFire的东西挺繁杂的,可以参考这篇
Calendar(例子上边写了)
这里的Calendar不是jdk的java.util.Calendar,不是为了计算日期的。它的作用是在于补充细化Trigger的触发时间。可以排除或加入某一些特定的时间点。
以”每月25日零点自动还卡债“为例,我们想排除掉每年的2月25号零点这个时间点(因为有2.14,所以2月一定会破产)。这个时间,就可以用Calendar来实现。
Quartz体贴地为我们提供以下几种Calendar,注意,所有的Calendar既可以是排除,也可以是包含,取决于:
- HolidayCalendar。指定特定的日期,比如20140613。精度到天。
- DailyCalendar。指定每天的时间段(rangeStartingTime, rangeEndingTime),格式是HH:MM[:SS[:mmm]]。也就是最大精度可以到毫秒。
- WeeklyCalendar。指定每星期的星期几,可选值比如为java.util.Calendar.SUNDAY。精度是天。
- MonthlyCalendar。指定每月的几号。可选值为1-31。精度是天
- AnnualCalendar。 指定每年的哪一天。使用方式如上例。精度是天。
- CronCalendar。指定Cron表达式。精度取决于Cron表达式,也就是最大精度可以到秒。
本文在大神的基础上加入了一些自己的理解和修改,入门的话这些东西基本就够了,详情请看下面两位大神的文章
https://blog.csdn.net/u010648555/article/details/60767633
https://www.cnblogs.com/drift-ice/p/3817269.html