吴恩达深度学习第四章卷积神经网络——第三周目标检测
定义
目标检测是计算机视觉领域中一个新兴的应用方向,其任务是对输入图像进行分类的同时,检测图像中是否包含某些目标,并对他们准确定位并标识。
目标定位
定位分类问题不仅要求判断出图片中物体的种类,还要在图片中标记出它的具体位置,用边框(Bounding Box,或者称包围盒)把物体圈起来。一般来说,定位分类问题通常只有一个较大的对象位于图片中间位置;而在目标检测问题中,图片可以含有多个对象,甚至单张图片中会有多个不同分类的对象。
为了定位图片中汽车的位置,可以让神经网络多输出 4 个数字,标记为 bxbx、byby、bhbh、bwbw。将图片左上角标记为 (0, 0),右下角标记为 (1, 1),则有:
- 红色方框的中心点:(
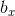 ,
,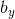 )
) - 边界框的高度:
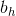
- 边界框的宽度:
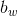
因此,训练集不仅包含对象分类标签,还包含表示边界框的四个数字。定义目标标签 Y 如下:
![]()
则有:

其中,![]() 表示存在第 n个种类的概率;如果 Pc=0,表示没有检测到目标,则输出标签后面的 7 个参数都是无效的,可以忽略(用 ? 来表示)。
表示存在第 n个种类的概率;如果 Pc=0,表示没有检测到目标,则输出标签后面的 7 个参数都是无效的,可以忽略(用 ? 来表示)。

损失函数可以表示为 ![]() ,如果使用平方误差形式,对于不同的 Pc有不同的损失函数(注意下标 i指标签的第 i个值):
,如果使用平方误差形式,对于不同的 Pc有不同的损失函数(注意下标 i指标签的第 i个值):
-
Pc=1,即y1=1:
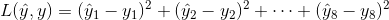
-
Pc=0,即y1=0:
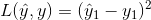
除了使用平方误差,也可以使用逻辑回归损失函数,类标签 c1,c2,c3也可以通过 softmax 输出。相比较而言,平方误差已经能够取得比较好的效果。
特征点检测
神经网络可以像标识目标的中心点位置那样,通过输出图片上的特征点,来实现对目标特征的识别。在标签中,这些特征点以多个二维坐标的形式表示。
通过检测人脸特征点可以进行情绪分类与判断,或者应用于 AR 领域等等。也可以透过检测姿态特征点来进行人体姿态检测。
目标检测
想要实现目标检测,可以采用基于滑动窗口的目标检测(Sliding Windows Detection)算法。该算法的步骤如下:
- 训练集上搜集相应的各种目标图片和非目标图片,样本图片要求尺寸较小,相应目标居于图片中心位置并基本占据整张图片。
- 使用训练集构建 CNN 模型,使得模型有较高的识别率。
- 选择大小适宜的窗口与合适的固定步幅,对测试图片进行从左到右、从上倒下的滑动遍历。每个窗口区域使用已经训练好的 CNN 模型进行识别判断。
- 可以选择更大的窗口,然后重复第三步的操作。

滑动窗口目标检测的优点是原理简单,且不需要人为选定目标区域;缺点是需要人为直观设定滑动窗口的大小和步幅。滑动窗口过小或过大,步幅过大均会降低目标检测的正确率。另外,每次滑动都要进行一次 CNN 网络计算,如果滑动窗口和步幅较小,计算成本往往很大。
所以,滑动窗口目标检测算法虽然简单,但是性能不佳,效率较低。
基于卷积的滑动窗口实现
相比从较大图片多次截取,在卷积层上应用滑动窗口目标检测算法可以提高运行速度。所要做的仅是将全连接层换成卷积层,即使用与上一层尺寸一致的滤波器进行卷积运算。
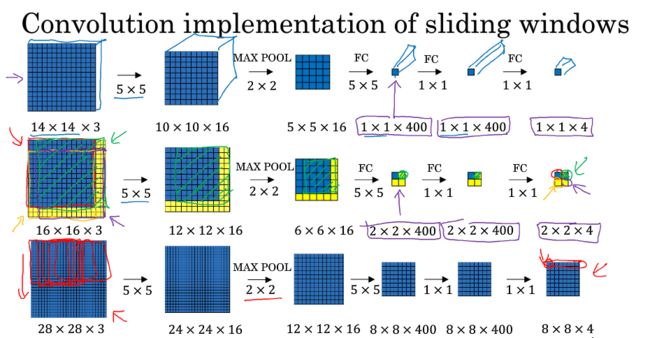
如图,对于 16x16x3 的图片,步长为 2,CNN 网络得到的输出层为 2x2x4。其中,2x2 表示共有 4 个窗口结果。对于更复杂的 28x28x3 的图片,得到的输出层为 8x8x4,共 64 个窗口结果。最大池化层的宽高和步长相等。
运行速度提高的原理:在滑动窗口的过程中,需要重复进行 CNN 正向计算。因此,不需要将输入图片分割成多个子集,分别执行向前传播,而是将它们作为一张图片输入给卷积网络进行一次 CNN 正向计算。这样,公共区域的计算可以共享,以降低运算成本。
相关论文:Sermanet et al., 2014. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
边框检测
在上述算法中,边框的位置可能无法完美覆盖目标,或者大小不合适,或者最准确的边框并非正方形,而是长方形。
YOLO(You Only Look Once)算法可以用于得到更精确的边框。YOLO 算法将原始图片划分为 n×n 网格,并将目标定位一节中提到的图像分类和目标定位算法,逐一应用在每个网格中,每个网格都有标签如:
![]()
若某个目标的中点落在某个网格,则该网格负责检测该对象。

如上面的示例中,如果将输入的图片划分为 3×3 的网格、需要检测的目标有 3 类,则每一网格部分图片的标签会是一个 8 维的列矩阵,最终输出的就是大小为 3×3×8 的结果。要得到这个结果,就要训练一个输入大小为 100×100×3,输出大小为 3×3×8 的 CNN。在实践中,可能使用更为精细的 19×19 网格,则两个目标的中点在同一个网格的概率更小。
YOLO 算法的优点:
- 和图像分类和目标定位算法类似,显式输出边框坐标和大小,不会受到滑窗分类器的步长大小限制。
- 仍然只进行一次 CNN 正向计算,效率很高,甚至可以达到实时识别。
如何编码边框 bx、by、bh、bw?YOLO 算法设 bx、by、bh、bw 的值是相对于网格长的比例。则 bx、by 在 0 到 1 之间,而 bh、bw 可以大于 1。当然,也有其他参数化的形式,且效果可能更好。这里只是给出一个通用的表示方法。
相关论文:Redmon et al., 2015. You Only Look Once: Unified, Real-Time Object Detection。Ng 认为该论文较难理解。
交互比
交互比(IoU, Intersection Over Union)函数用于评价对象检测算法,它计算预测边框和实际边框交集(I)与并集(U)之比:
![]()
IoU 的值在 0~1 之间,且越接近 1 表示目标的定位越准确。IoU 大于等于 0.5 时,一般可以认为预测边框是正确的,当然也可以更加严格地要求一个更高的阈值。
非极大值抑制
YOLO 算法中,可能有很多网格检测到同一目标。非极大值抑制(Non-max Suppression)会通过清理检测结果,找到每个目标中点所位于的网格,确保算法对每个目标只检测一次。
进行非极大值抑制的步骤如下:
- 将包含目标中心坐标的可信度 Pc 小于阈值(例如 0.6)的网格丢弃;
- 选取拥有最大 Pc的网格;
- 分别计算该网格和其他所有网格的 IoU,将 IoU 超过预设阈值的网格丢弃;
- 重复第 2~3 步,直到不存在未处理的网格。
上述步骤适用于单类别目标检测。进行多个类别目标检测时,对于每个类别,应该单独做一次非极大值抑制。
Anchor Boxes
到目前为止,我们讨论的情况都是一个网格只检测一个对象。如果要将算法运用在多目标检测上,需要用到 Anchor Boxes。一个网格的标签中将包含多个 Anchor Box,相当于存在多个用以标识不同目标的边框。

在上图示例中,我们希望同时检测人和汽车。因此,每个网格的的标签中含有两个 Anchor Box。输出的标签结果大小从 3×3×8 变为 3×3×16。若两个 Pc都大于预设阈值,则说明检测到了两个目标。
在单目标检测中,图像中的目标被分配给了包含该目标中点的那个网格;引入 Anchor Box 进行多目标检测时,图像中的目标则被分配到了包含该目标中点的那个网格以及具有最高 IoU 值的该网格的 Anchor Box。
Anchor Boxes 也有局限性,对于同一网格有三个及以上目标,或者两个目标的 Anchor Box 高度重合的情况处理不好。
Anchor Box 的形状一般通过人工选取。高级一点的方法是用 k-means 将两类对象形状聚类,选择最具代表性的 Anchor Box。
如果对以上内容不是很理解,在“3.9 YOLO 算法”一节中视频的第 5 分钟,有一个更为直观的示例。
R-CNN
前面介绍的滑动窗口目标检测算法对一些明显没有目标的区域也进行了扫描,这降低了算法的运行效率。为了解决这个问题,R-CNN(Region CNN,带区域的 CNN)被提出。通过对输入图片运行图像分割算法,在不同的色块上找出候选区域(Region Proposal),就只需要在这些区域上运行分类器。

R-CNN 的缺点是运行速度很慢,所以有一系列后续研究工作改进。例如 Fast R-CNN(与基于卷积的滑动窗口实现相似,但得到候选区域的聚类步骤依然很慢)、Faster R-CNN(使用卷积对图片进行分割)。不过大多数时候还是比 YOLO 算法慢。
相关论文:
- R-CNN:Girshik et al., 2013. Rich feature hierarchies for accurate object detection and semantic segmentation
- Fast R-CNN:Girshik, 2015. Fast R-CNN
- Faster R-CNN:Ren et al., 2016. Faster R-CNN: Towards real-time object detection with region proposal networks