利用word2vec、textCNN、jieba对事故文本多分类及致因修复(三维向量)
中文分词 + 数据集三维向量化 + TextCNN
一、背景
经过几天的测试及模拟建模训练,尝试了机器学习中的一些常用模型,例如Lasso、LR、SVM、XGBoost、GBTD等,发现效果并不如人意,最好最好的结果也是刚刚超过60%的准确率。
思考了一下原因,发现主要还是因为在传统机器学习模型中,输入的是一条一条的行向量,正如之前文章中用到的方式,将一个文本先分词,得到一个词组,在把词组中的每一个词利用word2vec转为行向量后,用所有词的均值行向量来表示这段文本。再将所有的数据统一转成这样的一行一行的代表向量后组成一个二维表,长度为数据量,宽度为特征向量。
在这个过程中,相当于预先就将文本数据进行了初步的特征提取,对于短文本来说,本来就没几个特征点,这一提取,能够表示文本属性的值就更模糊了,大概也是因为如此,才导致传统机器学习模型对其效果并不好。
由此查了相关文献后发现,文本分类还可以利用深度学习中的卷积神经网络进行建模,这样就可以很好的描述短文本的特征属性。将之前的二维数据集,转换为三维数据集。类比图片分类来进行训练建模。
具体后面会解释怎么转换
二、数据预处理
一开始还是导入需要用到的包
#导包
import numpy as np
import pandas as pd
import sys
from gensim.models import word2vec
import os
import gensim
from gensim.models.word2vec import LineSentence#读数据
data = pd.read_csv('./data.csv')
data
数据集中,y是我们最后确定的新分类类别,x是事故案情描述,split是之前已经使用jieba分词分后的结果(这里是因为后面覆盖了原有数据集,大家就当没有这个字段吧)
分词
#判断字符串是不是中文
def check_contain_chinese(check_str):
for ch in check_str:
if u'\u4e00' <= ch <= u'\u9fff':
return True
else:
return False#分词
import jieba
jieba.load_userdict('../dic.txt')
stop = [line.strip() for line in open('../stopwords.txt').readlines()]#去停用词
out = ''
for index in range(len(data)):
ct = jieba.cut(data.loc[index,'x'])
out = ''
for word in ct:
if word not in stop:
if check_contain_chinese(word) == True:
if (word.endswith("省") == False):
if (word.endswith("市") == False):
if (word.endswith("县") == False):
if (word.endswith("镇") == False):
if (word.endswith("村") == False):
out += word
out += " "
data.loc[index,'split'] = out#训练
model = word2vec.Word2Vec(sentences,size = 100)
model.save('jk.model')向量化
#读取出数据
import pprint
text = data['split']
sentences = []
for item in text:
sentence = str(item).split(' ')
sentences.append(sentence)稍微解释一下,对数据集我是这样一个思路来构建的。
首先,原本的数据集是上文展示到的传统二维表,一维表示特征而二维表示数据数量,但那样的话,就只能进行向量平均化来用行向量代表整个文本,特征属性抽象化,效果不好。
因此,打算将一段文本的词组中的每一个词对应的行向量,上下拼接,这样的话,一段文本就可以用一个矩阵来表示,每一个词的特征都能很好的保存在矩阵中,比均值化效果好。
这样,我们就得到了(x,y)来表示一段文本,那咱们的数据集中是多段文本,怎么办呢?
没错,就再增加一个维度z,把每一个文本用一个平面来表示,用一个立体三维矩阵,来表示整个数据集,好似多个文本平面叠在一起,组成了(x,y,z)
那我们应该怎么做呢?别急,下面会慢慢解释:
def buildWordVector(imdb_w2v,text, size):
vec = np.zeros(size).reshape((1, size))
pad = np.zeros(size).reshape((1, size))
count = 0
for word in text.split():
try:
vec = np.vstack((vec, imdb_w2v[word].reshape((1, size))))
count += 1
except KeyError:
print (word)
vec = np.delete(vec, 0, 0)
#填充不满260的矩阵
if len(vec) < 260:
for i in range(260 - len(vec)):
vec = np.vstack((vec, pad))
return vec这段函数,也是核心函数,是将一段文本转换为矩阵的关键。
咱们一句一句来解释
vec = np.zeros(size).reshape((1, size)) 这一句没啥太大意义,只是做一个媒介,类似于头结点,方便后面循环链接,后面也会把他删除
pad = np.zeros(size).reshape((1, size))这一句比较重要,是创建了一个0的行向量,具体原因很好理解:
因为大家也都知道,文本的长度是不一定的,分词后的词的数量也并不都是一样的,因此,如果不对矩阵进行填充的话,一个立方体矩阵,可能就变成了畸形。也不利于作为模型的输入,因此,我们要找到一个不大不小的值n,让所有文本平面向量都能够包含在里面,例如260,若词数小于260的文本,把剩余的用0来代表。因为向量化后的值是在-1到1之间,因此,取了0这个中间数来进行填充。
而n怎么取呢,他不能太大,因为太大了会造成矩阵的稀疏性问题,会让填充的值影响到了原有特征,从而影响模型的普适性。
他也不能太小,因为太小了会造成,假如输入了一个稍长一点的文本,可能就会出错。
因此我们将所有的数据进行了统计,用词数最大值 * 1.5作为这个n值
看到这,大家就知道了这个0行向量pad的作用了吧,方便后面填充用的。
count = 0 这个是之前统计各词组词数的时候加的,这里没用
for word in text.split():
try:
vec = np.vstack((vec, imdb_w2v[word].reshape((1, size))))
count += 1
except KeyError:
print (word)这一小段循环,大家应该能够明白,就是将词组中每一个词都转换为100维的行向量,再相互连接,得到一个矩阵
vec = np.delete(vec, 0, 0) 这个就是删除掉一开始所多出来的头结点
if len(vec) < 260:
for i in range(260 - len(vec)):
vec = np.vstack((vec, pad))这个是判断,若词数小于260,则填充0向量。也能很好理解
构建立体向量数据集
result = buildWordVector(model_word, data.loc[1]['split'] , 100)
for i in range(1,len(data)):
result = np.concatenate((result, buildWordVector(model_word, data.loc[i]['split'] , 100)), axis = 0)
result.shape这几行的代码就是,把所有的文本段都转化为矩阵后,先按垂直方向上下拼接。

得到一个684060 * 100 的矩阵
而我们也知道,数据集中有2631条数据,2631 * 260 恰好等于684060
x_all = result.reshape(2631,260,100)这一行就是关键了,因为每一个文本的大小都是一样的,我们就可以直接用reshape函数,对长矩阵进行重构,重构为一个三维矩阵。
大家可能会问了,那干嘛不在前面直接就循环将每一个矩阵立体拼接起来呢,其实是因为numpy和pandas中,并没有立体拼接矩阵的函数,因此只能换一种方式来实现。

这时候我们就可以看到了这个三维矩阵已经构建完成了,之后就是对数据集进行划分的操作啦
数据集划分
import tensorflow as tf
from sklearn.preprocessing import label_binarize
from sklearn.model_selection import train_test_splity = label_binarize(y, classes=[2, 3, 4, 5])首先,将标记值y二值化

将原本值为2,3,4,5的,转换上图形式
# 训练模型并预测
random_state = np.random.RandomState(0)
# 随机化数据,并划分训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(x_all, y, test_size=0.2,random_state=0)按8:2来划分数据集和测试集合
三、建模
导入相关库
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten, Conv1D, Embedding, Dropout, MaxPool1D, GlobalMaxPool1D,Lambda, LSTM, TimeDistributed
from keras.optimizers import Adam
import kerasmodel = Sequential()
model_cnn.add(Conv1D(input_shape = (260,100),filters=100,kernel_size=3, padding='valid', activation='sigmoid',strides=1))
model_cnn.add(GlobalMaxPool1D())
model_cnn.add(Dense(y.shape[1], activation='softmax'))
model_cnn.add(Dropout(0.2))
model_cnn.compile(loss='categorical_hinge', optimizer = 'adam', metrics=['accuracy'])
model_cnn.summary()构建的和流传的有一点不太一样,这里比较坑,因为之前没有搭过CNN,所以在看别人的开源代码的时候,发现别人的第一层是embdeing层,用处是直接输入分词后的文本,利用embdeing层将词组编码,再往后输入卷积。
可我是已经做好了向量化的操作,已经将数据集转为了三维的向量矩阵,于是将第一层直接删除,谁知道就一直报错,说我没有初始化权重,研究了好久才发现,是没有给Con1D添加input_shape属性,没有规定输入的大小,这里直接用shift+tab键的参数提醒里是没有的,keras开发文档中才看到。第一层必须添加input_shape属性。
然后就构建了1层1D卷积层+全局最大池化层+Dropout防止过拟合+输出。
 四、训练
四、训练
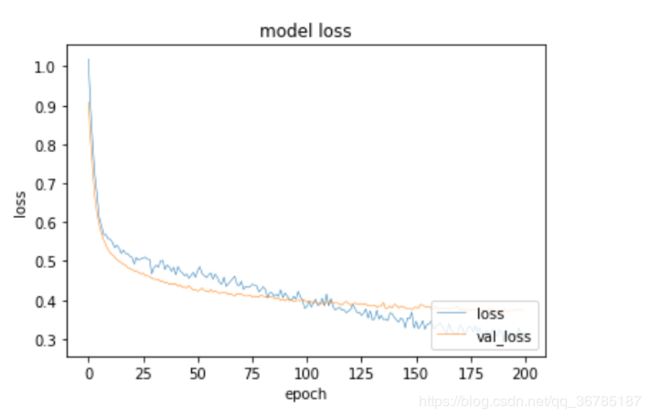
经过200epoch训练后的模型效果如下:

nb了,比传统机器模型的效果不知道好到哪里去了....(大佬勿怪,主要是不会用)
听说还有个加强版的TextRCNN,是在CNN的基础上添加了RNN的时序层,尝试了一下纯RNN的模型:
model_rnn = Sequential()
model_rnn.add(LSTM(256, input_shape=(260,100), return_sequences=True))
model_rnn.add(Dropout(0.2))
model_rnn.add(LSTM(256))
model_rnn.add(Dense(4, activation='softmax'))
opt = Adam(lr=1e-3, decay=1e-5)
model_rnn.compile(loss='categorical_hinge', optimizer=opt)
慢的要死,懒得去试了,反正80%多也够了,数据量这么少,再高也可能普适性就差了。
果断放弃更复杂的RNN+CNN
五、可视化展示
a = model_cnn.history
plt.plot(a.history['acc'], linewidth=0.5)
plt.plot(a.history['val_acc'],linewidth=0.5)
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['acc', 'val_acc'], loc = 'lower right')
plt.show()
plt.plot(a.history['loss'], linewidth=0.5)
plt.plot(a.history['val_loss'], linewidth=0.5)
plt.title('model loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['loss', 'val_loss'], loc='lower right')
plt.show()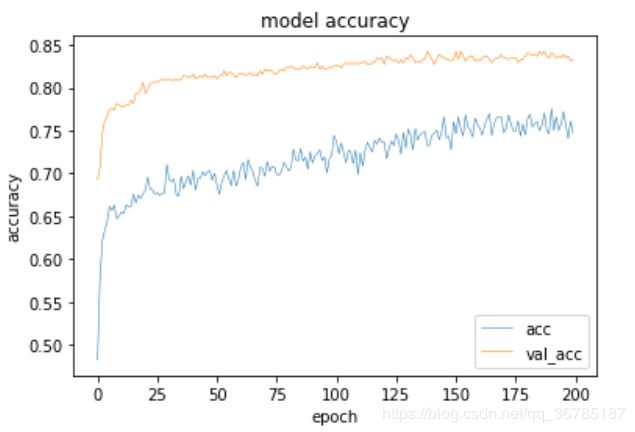
六、结语
本来是应该分1、2、3、4、5五类的,可是第一类是”其他“,也就是说是那些现实中分类不清的数据,因此模型设置分类为2,3,4,5四类,将类别为1的全部抽了出来,大概有1000多条左右,约占1/3,训练好了模型之后,将这1000多条丢进了模型进行预测,也得到了模型对其判断的输出类别,经过小伙伴们的人工检查,发现效果还挺不错的,人为没有找到什么bug,虽说这次的数据集本来就没多少条,效果不应该会很好,但可能是分类颗粒度比较大,也算是蒙混过关了吧。不出问题就好。
后面的工作就是要展示数据啦,做个桌面应用来将分类过程进行可视化展示来装逼啦之类的,重头戏已经结束。
在这一次建模的过程中,自己还是觉得提升特别大,一方面是对numpy和pandas的熟练度大大加深,另一方面,也对machine乃至deeplearning实现了很好的从理论到实践的小转换,实践能力也提高了很多,接下来就是继续学习,边动手,边学理论,加油!
(数据涉密,不能外放,见谅!)