java用tabula解析pdf文件中的表格
前面写了一个用pdf解析pdf格式的发票,因为发票的样式相当于一个表格,之前那篇博客已经说过了,pdfbox没找到能定位表格的线坐标的方法,所以明细部分的解析不能说是100%的正确,今天又找到一个新的东西,就是tabula,专门解析pdf表格,可以解析各种连分割线都没有的表格,真强,是在pdfbox的基础上再封装的,底层还是pdfbox实现的,github地址tabula-java
因为找了半天能找到的博客很少,所以下载了源码看一看,里面有很多test类
我就试了一下TestWriters,解出来的和直接用pdfbox的PDFTextStripper解析出来是一模一样的。
在网上看到的是用CommandLineApp这个类来解析的,研究一下这个吧
导入依赖
technology.tabula
tabula
1.0.3
slf4j-simple
org.slf4j
开始控制台报了一个slf4j的错,是jar冲突导致的,移除tabula依赖里的slf4j就好了
@Test
public void test1() {
String[] args = new String[]{"-f=JSON","-o=d:/output.txt", "-p=all", "D:\\work\\file\\temp\\111.pdf"};
CommandLineApp.main(args);
}这样子解析出来的直接就是按照从上到下从左到右单元格划分的,而且带着单元格的坐标,这不就是我之前苦苦要找的吗!!!!!!!!!!!开心!

可以用之前的方法读取表格外面的那些字段,用tabula来读表格里面的字段,完美!
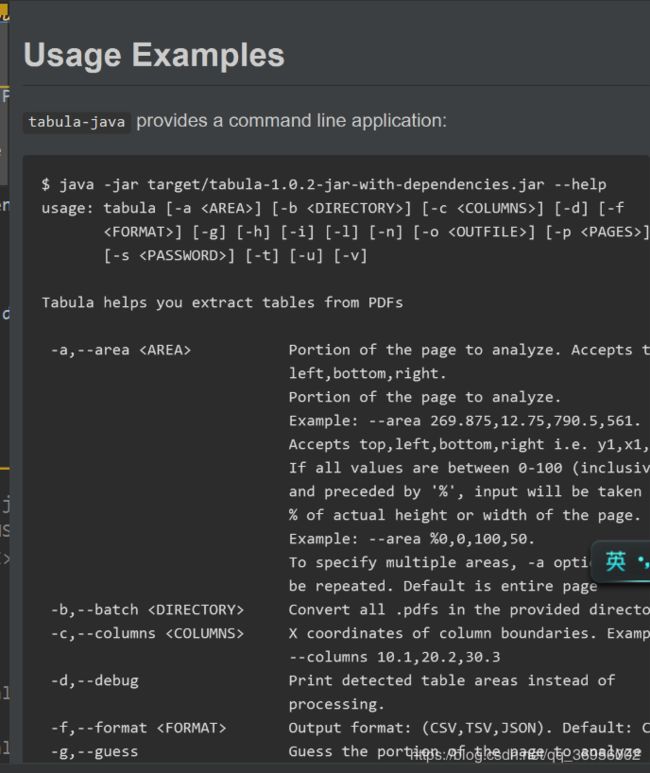
在readme文件中介绍了参数都是什么意思,虽然我也没怎么看懂
-f=JSON 就是输出json格式,默认是csv的
-o=d:/output.txt 就是输出到文件,当然我们解析肯定不用输出到文件,只要获得字符串就可以了,等下找找参数应该写什么
-p=all 就是解析的页数吧,我这个只有这一页
最后一个参数就是要读取的pdf文件路径了
参数的可以加的,之所以是数组,就是因为参数的个数可以随便传
@Test
public void test1() {
String[] args = new String[]{"-f=JSON", "-p=all", "D:\\work\\file\\temp\\111.pdf"};
CommandLineApp.main(args);
}去掉-o=d:/output.txt的话,直接就输出到控制台了,那么怎么接收呢?
@Test
public void test1() throws Exception {
String[] args = new String[]{"-f=JSON", "-p=all", "D:\\work\\file\\temp\\111.pdf"};
// CommandLineApp.main(args);
CommandLineParser parser = new DefaultParser();
CommandLine cmd = parser.parse(CommandLineApp.buildOptions(), args);
StringBuilder stringBuilder = new StringBuilder();
new CommandLineApp(stringBuilder, cmd).extractTables(cmd);
System.out.println("============");
System.out.println(stringBuilder.toString());
}完美!哈哈哈,其实那个源码的test里就是这么写的
那么接下来就是先去掉坐标为0的元素(不知道为啥,有好多坐标0长宽0的元素),然后按照发票的样子,按顺序去取值,然后按照行,冒号等等分隔,就可以拿到我们要的内容啦!