【Python3.6爬虫学习记录】(五)Cookie的使用以及简单的爬取知乎
前言
Cookie,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)。
有些网站需要登录后才能访问某个页面,比如知乎的回答,QQ空间的好友列表、微博上关注的人和粉丝等,在登录之前,你想抓取某个页面内容是不允许的。那么我们可以利用某些库保存我们登录后的Cookie,然后爬虫使用保存的Cookie可以打开网页进行相关爬取,此时该页面仍然以为是我们人为的在访问,孰不知是爬虫。当然,一个Cookie也不能永久的使用,一段时间后需要更换。
对于登陆情况的处理
1 使用表单登陆
这种情况属于post请求,即先向服务器发送表单数据,服务器再将返回的cookie存入本地。
data = {‘data1’:’XXXXX’, ‘data2’:’XXXXX’}
Requests:data为dict,json
import requests
response = requests.post(url=url, data=data)
2 使用cookie登陆
使用cookie登陆,服务器会认为你是一个已登陆的用户,所以就会返回给你一个已登陆的内容。因此,需要验证码的情况可以使用带验证码登陆的cookie解决,此为后话。
import requests
requests_session = requests.session()
response = requests_session.post(url=url_login, data=data)
本文只用到简单的cookie模拟登陆,详细教程戳这里
# 爬取知乎,-headers的应用
from http import cookiejar
from urllib import request
from bs4 import BeautifulSoup
# # cookie的测试
# # 声明一个CookieJar实例对象
# cookie = cookiejar.CookieJar()
# # 创建cookie处理器
# handle = request.HTTPCookieProcessor(cookie)
# # 通过cookie处理器创建opener实例
# opener = request.build_opener(handle)
# # 通过opener实例打开网页
# response = opener.open('https://www.zhihu.com/question/25313930')
# # 打印cookie
# for item in cookie:
# print('Name = %s' % item.name)
# print('Value = %s' % item.value)
# 命名保存cookie的文件的文件名
filename = 'cookie.txt'
#保存cookie到文件
def saveCookie():
cookie = cookiejar.MozillaCookieJar(filename)
handler = request.HTTPCookieProcessor(cookie)
opener = request.build_opener(handler)
response = opener.open('https://www.zhihu.com/question/25313930')
# ignore_discard的意思是即使cookies将被丢弃也将它保存下来;
# ignore_expires的意思是如果在该文件中cookies已经存在,则覆盖原文件写入
cookie.save(ignore_discard=True, ignore_expires=True)
saveCookie()
# 从文件中获取cookie并访问
# 创建MozillaCookieJar实例
cookie = cookiejar.MozillaCookieJar()
# 从文件中读取cookie内容到变量
cookie.load(filename,ignore_discard=True,ignore_expires=True)
# 创建cookie处理器
handle = request.HTTPCookieProcessor(cookie)
# 通过cookie处理器创建opener对象
opener = request.build_opener(handle)
# 通过opener对象的open方法打开网页
response = opener.open('https://www.zhihu.com/question/25313930')
html = response.read()
soup = BeautifulSoup(html,'lxml')
storys = soup.find_all('div',class_="List-item")
print(len(storys))
for story in storys :
nameLabel = story.find('meta',itemprop="name")
name = nameLabel["content"]
with open('By '+str(name)+'.txt','w') as f:
storyText = story.find('span', class_="RichText CopyrightRichText-richText")
#storyPages = storyText.find_all('p')
try:
# 获取多个内容,不过需要遍历获取,比如下面的例子
for string in storyText.strings:
f.write(repr(string)+'\n')
print('By '+str(name)+' has been finished')
except Exception:
print('Something is wrong on writing to txt')
print('That is all')相关问题
①解决更新Cookie问题的思路
创建saveCookie()方法,每次获取并保存前一次登陆获得的cookie
②爬取某个回答的全文
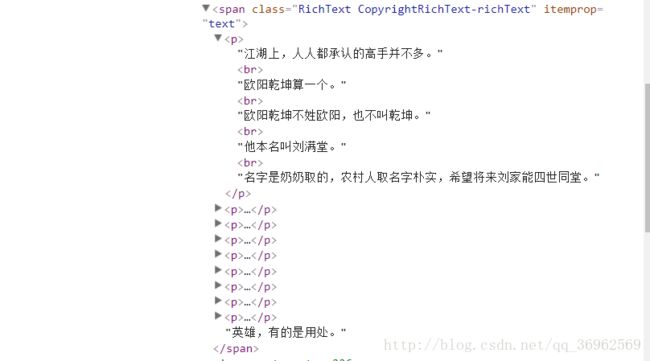
使用下面的代码出现问题,并且打印storyPages为空
storyPages = storyText.find_all('p')
for storyPage in storyPages:
f.write(str(storyPage)+'\n')遂再次查看BeautifulSoup的使用教程,改为以下用法
for string in storyText.strings:
f.write(repr(string)+'\n')③未能爬起该页面下全部回答
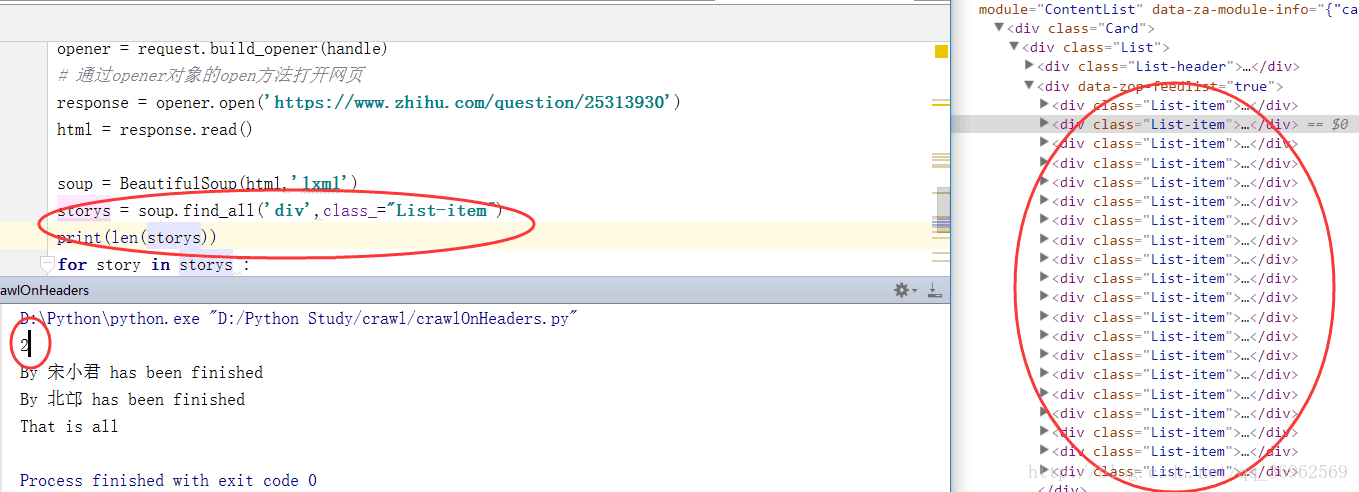
④获得url的源码的等价处理
使用cookie与不使用时,以下两个方法,打印,得到相同结果
#当使用cookie时
response = opener.open('https://www.zhihu.com/question/25313930')
html = response.read()#当不使用cookie时
url = 'http://www.jianshu.com/p/82833d443e76'
html = requests.get(url).content