【实战】利用爬虫实现知网高级检索后的文献预览和下载(逻辑分析)
完整项目地址:https://github.com/CyrusRenty/CNKI-download
1 背景
在使用知网时,我们一般都会遇到一个问题就是对于搜索出来的文献,如果想要看他的摘要等信息,必须要点击标题跳转到一个新的页面查看,感兴趣后再下载,这会比较大程度较低我们下载效率,同时也会增加更多时间成本。
在写这个爬虫之前,我搜索了一下目前网上实现知网检索的爬虫,以前似乎有一个下载工具有许多的star,但是最近已经关闭了。剩余的爬虫也试了一部分,有些已经不能使用了,有些是通过这个接口,但是他只能实现基本的检索功能,这样下载的文献实际上,很多都是质量比较低的无用文献,所以准备研究从知网的高级检索界面入手,实现高级检索功能,通过高级检索得到结果并保存预览信息到excel,最终再进行下载。
2 技术栈及最终效果
本爬虫在实现时主要使用的有requeset、re、beautifulsoup这一部分的基础知识在本文中不多介绍,除此之外在验证码识别部分还使用了tesserocr,但是自动识别验证码目前效果还不是很好。在分析时用到的工具为fiddler。
运行过程演示:
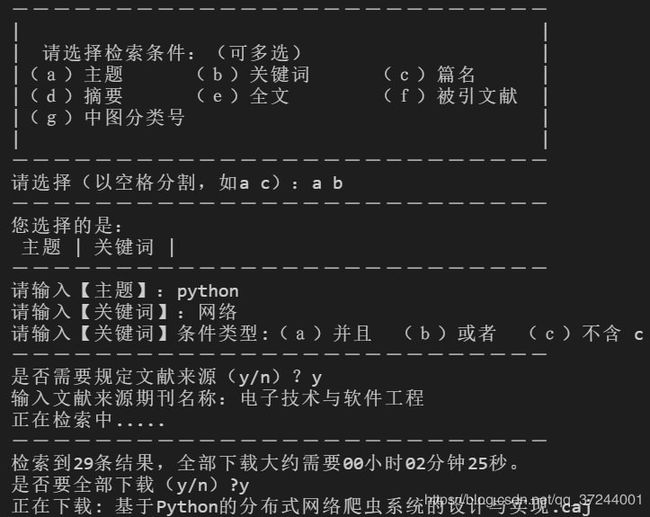
详细信息excel表格:
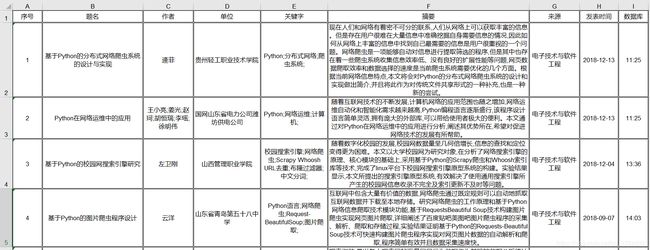
下载caj如下:

3 检索下载逻辑分析
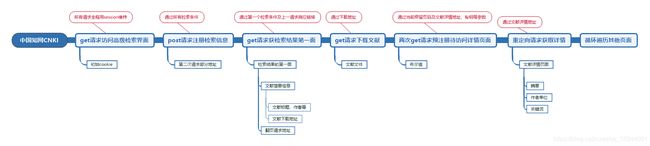
知网在检索完成后会在同一页面下方直接显示检索结果,结果中包括了文献的标题、作者等信息,同时可以直接在此处选择下载,所以将程序实现的逻辑分析分为两个部分,第一部分为检索下载,第二部分为详细信息抓取(下文也会证明,这两部分在实现时确实有一些不同)。
逻辑分析部分记录的是我在实现完成过程后的反推过程,所以如果大家按照我的思路来,可能会躲过一些不必要的坑,会节省不少时间。但是还是强烈建议在读完本文后,根据实现实例代码重新实现一遍。
3.1 检索条件如何传递
打开知网的高级检索界面,输入条件点击检索,通过fiddler观察发包情况可以看到每次输入不同的检索条件,基本上前几次请求基本一致,如下图所示:
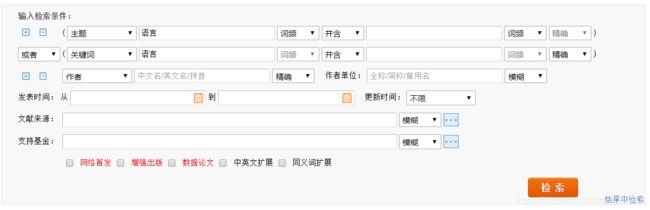

所以我们着重对以上几个请求进行分析,首先第一个post请求KNS/request/SearchHandler.ashx,观察他的RequestBody可以发现所有我们输入的检索条件都是通过这里发送给服务器的,其中参数数量根据条件的不同而变化。同时根据上面我们得到的几个请求的英文单词也可以大致猜到这个SearchHandler应该就是将检索条件第一时间发送给服务器。
知网中的每一个请求都是按照请求方法的作用进行命名,这在很大程度上能够帮助我们快速定位到我们需要的请求。
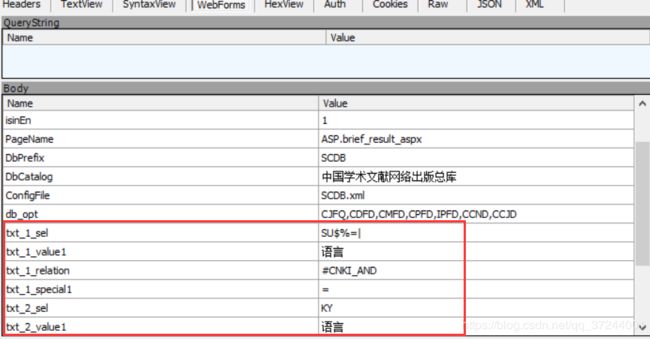
既然我们已经找到了传递参数的方法,那就可以在这里先把所有检索条件需要的参数先试出来。这些参数中有很多都是固定的,也有一部分是动态的,动态的一般就是检索条件需要的,需要注意是如果没有规定某个条件,那个这个参数是不传递的。下面列出了一部分常用的传递参数,更多参数大家自己通过这个方法查看。
| 字段 | 字段含义 | 备注 |
|---|---|---|
| txt_1_sel | 字段标识符 | 不止一个条件是数字递增 |
| txt_1_value1 | 字段值 | 无需转译中文可直接输入 |
| txt_1_relation | 固定不变字段 | 恒为#CNKI_AND |
| txt_1_special1 | 固定不变字段 | 恒为= |
| txt_2_special1 | 查询关系 | 第一个条件无该参数,编号从2开始 |
| magazine_value1 | 期刊来源 | 只能输入一个,没有2 |
相关固定字段值列出如下:
| 字段 | 可选值 |
|---|---|
| txt_1_sel | 主题(SU$%=|)、关键词(KY)、篇名(TI)、摘要(AB)、全文(FT)、被引文献(RF)、中图分类号(CLC$=|??) |
| txt_2_special1 | 并且(and)、或者(or)、不含(not) |
现在知道了所有需要传递的,需要再看一看这个请求,首先可以发现这个请求的请求头是有cookie传递的,也就是说在这个我们目前发现最早开始处理条件检索前面应该还有一个请求是用于set-cookie 的。其次可以看到这个请求的返回体中并没有传回检索到的所有文献内容,只是传回了一个类似于请求地址的东西,那么根据经验这个地址一定是后面获取关键内容需要拼接到请求地址后面的,我们下面继续来看一看其他的请求。
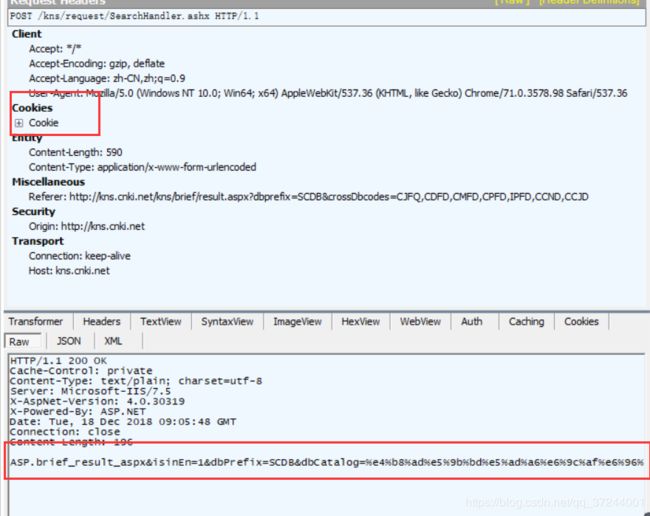
正如上面所说,因为知网的请求都是按照请求的效果来命名的,很容易就发现有一个http://kns.cnki.net/kns/brief/brief.aspx 的请求,根据名字可以发现应该是获取摘要信息,同时这个请求的响应体可以看到非常的大,在fiddler中点击后可以看到其返回内容的确就是具体的文献列表信息(第一页),那么我们接下来就主要对这个请求进行分析。
其他几个请求主要是在处理检索结果的分组游览、下方的相关搜索以及知名专家,我们一般都用不上,所以可以直接排除。
首先来看一下他的请求头,可以发现这个请求地址的前半部分正是我们上一个请求响应体发送回来的信息,后半部分则是t=后面的内容。如果我们多进行几次请求就可以发现,后半部分的请求中需要每次传入的只有一个keyValue,而这个keyValue就是我们在SearchHandler 请求的第一个检索条件txt_1_value1 的值(t参数的值是一个时间戳,任意指定一个固定的时间戳即可)。如果我们多进行几次请求就可以发现,后半部分的请求中需要每次传入的只有一个keyValue,而这个keyValue就是我们在SearchHandler 请求的第一个检索条件txt_1_value1 的值(t参数的值是一个时间戳,任意指定一个固定的时间戳即可)。
GET /kns/brief/brief.aspx?pagename=ASP.brief_result_aspx&isinEn=1&dbPrefix=SCDB&dbCatalog=%e4%b8%ad%e5%9b%bd%e5%ad%a6%e6%9c%af%e6%96%87%e7%8c%ae%e7%bd%91%e7%bb%9c%e5%87%ba%e7%89%88%e6%80%bb%e5%ba%93&ConfigFile=SCDB.xml&research=off&t=1545123950261&keyValue=python&S=1&sorttype= HTTP/1.1
目前为止,我们就找到了通过检索获取检索结果的方法。
3.2 获取网页cookie
再继续往下处理时,我们来处理一下cooike的获取,之前在分析请求时,可能已经发现上面的那些请求其实都是有cookie的,这也是必须的,要不然知网也无法判定这个用户合不合法。所有我们来寻找一些是在哪里获取cookie的。首先清楚存储了的cookie,重新刷新高级检索界面,可以看到set-cookie操作是在第一个请求是发起的。
这里要提一下就是,可能是我对fiddler用的也不深入,但是我比较推荐的是大家chrome和fiddler一起配合使用来进行网页分析。

所以在之后的代码实现时,我们还应该首先通过这个请求获取cookie并对cookie进行管理。(request库的session方法就非常有用了,具体可以看代码实现部分。)
3.3 获取下载地址
在已经有了brief.aspx 请求返回的信息后,再获取下载地址就非常方便了,因为知网在文献列表就支持直接下载,那么之后也可以直接通过这个地址下载,可以将地址复制到地址栏测试发现的确可以直接下载,那么之后就是在代码实现中如何获取地址的问题了。返回的每一个行文献信息里面都会有一个下载地址,如下:

3.4 获取下一页
目前,我们已经完成了对检索出来的第一个页面的所有信息解析,那么下面来尝试获取其他页面。查看检索结果页面下方的页码跳转工具条,可以发现每一页的跳转页面信息都是一样的,只是页码参数不同。
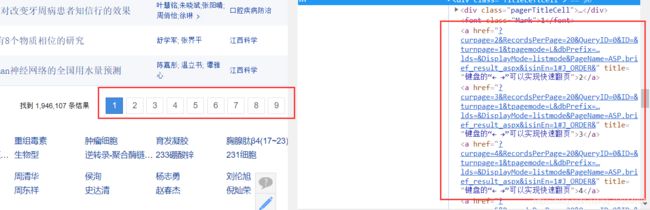
通过fiddler可以验证,当点击了其他页码时。新产生的get请求响应体内包含了第二页的内容,这个请求的地址与上方标签中的一致,同时不同的页面跳转时,只是curpage参数不同。所以我们在想实现跳转时,可以在获取到工具条中第二页地址后,每次循环更改curpage参数指向的页码即可。
4 详情页获取
4.1 点击之后的请求处理
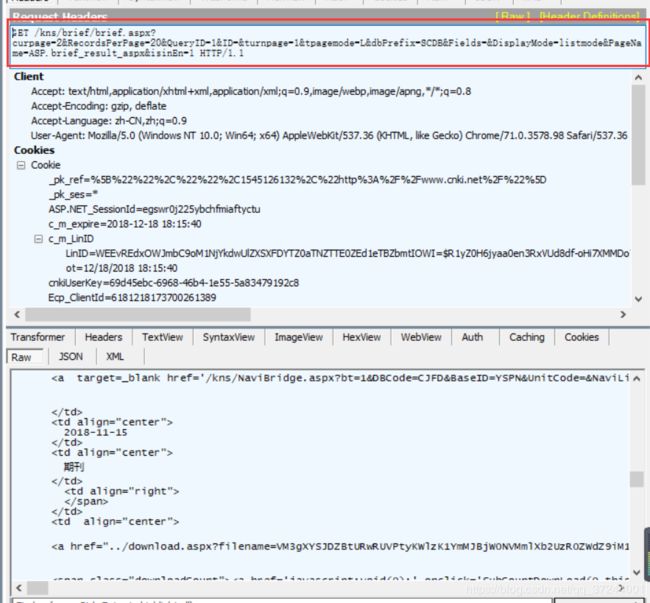
如果我们用fiddler查看点击文献检索结果列表中的某一个具体文献查看文献详情,可以发现是一个名为http://kns.cnki.net/kns/detail/detail.aspx 的get请求进行了重定向(302),之后获取到了具体的详情信息。

但是如果我们在游览器中输入请求地址,以通过这个get请求让服务器直接重定向到详情页面信息时,发现服务器会拒绝服务。

这就告诉我们,在这个请求上面的两个http://i.shufang.cnki.net/KRS/KRSWriteHandler.ashx 请求也一定是必须的,功能应该就是首先对服务器进行一次注册。下面我们就来看一下如何构造出这两个KRSWriteHandler请求。通过webForms可以发现这两个请求的请求参数完全一致。
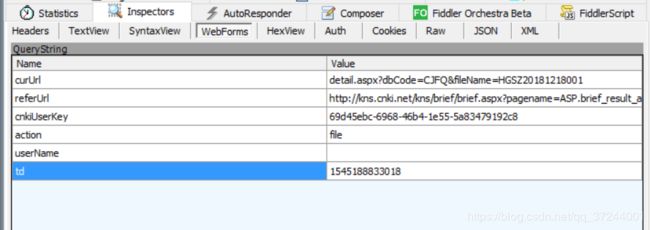
字段的含义分别如下:
| 字段 | 字段含义 |
|---|---|
| curUrl | 当前列表处于第几页,可以有之前请求某一页列表的URL拼接得出 |
| referUrl | 当前文献的具体跳转链接,隐藏在单一文献行内(文献标题的 |
| cnkiUserKey | 用户id,后面会讲到如何获取 |
| action | 固定为file |
| userName | 为空 |
| td | 时间戳,任意指定 |
有了这些信息,就可以构造出每一次打开详细页面前的两个KRSWriteHandler.ashx 预请求了。再来观察第三个请求,也就是获取具体详情页面的重定向请求地址是如何拼接的。发现每一个重定向请求地址正是单行文献标题列的标签中的地址。
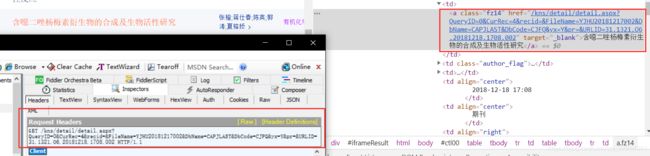
有了这些信息我们就可以像服务器请求每一篇文献的详情信息(比如摘要、关键词等)。不过我们在请求之前还要处理一下cnkiUserKey。
4.2 得到UserKey
简单地说,cookie 就是浏览器储存在用户电脑上的一小段文本文件。cookie 是纯文本格式,不包含任何可执行的代码。一个 Web 页面或服务器告知浏览器按照一定规范来储存这些信息,并在随后的请求中将这些信息发送至服务器,Web 服务器就可以使用这些信息来识别不同的用户。大多数需要登录的网站在用户验证成功之后都会设置一个 cookie,只要这个 cookie 存在并可以,用户就可以自由浏览这个网站的任意页面。
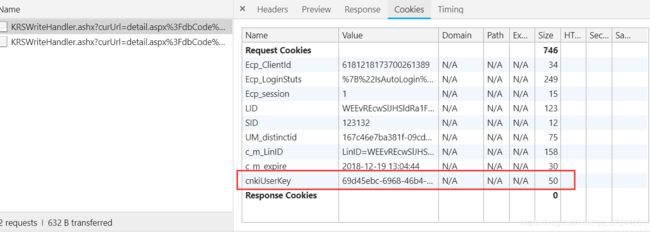
上面讲到的三个请求,每次发送请求时,都会有一个之前没有出现过的cookie,名为cnkiUserKey。一般cookie都是通过请求的响应部分通过set-cookie设置,但是如果我们即使搜索了从进入高级检索页面到点击进入详情页面的所有请求,也没有一个请求通过set-cookie设置了这样一个请求。那么必须从另一个方向入手,想到cookie设置的另一个途径,即通过js设置。进一步缩小范围,可以发现在进入高级检索界面时,这个cookie还没有被设置,当输入了条件点击检索这个cookie几乎在请求全部完成时才加入,所以我么你可以对这一阶段所有返回的js文件进行反向检索,在响应体中搜索cnkiUserKey,就会有令人激动的发现:
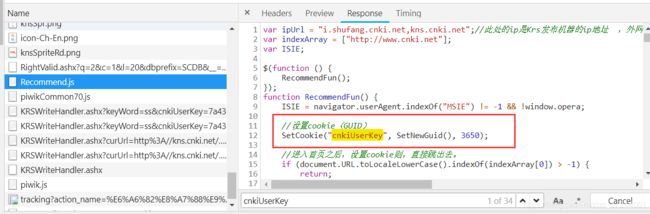
通过定位到这个语句,可以很明显发现这个秘钥是在这个js文件生成的,那接下来只需要在确定一次这个秘钥有没有在我们发送那三个请求之前先发送给服务器做一次备案。有两种方式,第一种如果大家熟悉js语法,可以把这个文件检索一遍;或者用更加暴力的方式,我们通过谷歌游览器开发者工具将游览器中目前存储的刚检索完成生成的cnkiUserKey中某一个值更改一下,比如吧上图中的69改为79,再次点击一个文献行获取详情信息,会发现还是能够正常获取。这就告诉我们生成的这个cookie服务器根本没有做验证。那么我们也只需要在发送这三个请求之前本地生成一个cnkiUserKey即可,甚至用完全静态固定的cnkiUserKey也是可以的。
以上就是我们在进行代码实现之前的所有逻辑分析,爬虫整体处理过程如下图所示,代码分析见【实战】利用爬虫实现知网高级检索后的文献预览和下载(代码实现),完整项目地址:https://github.com/CyrusRenty/CNKI-download,欢迎大家与我讨论