sklearn机器学习:随机森林学习与调参
这部分sklearn学习笔记不会过多的涉及随机森林的原理(但还是会介绍),但是个人建议还是得知道随机森林的原理再来用sklearn会容易懂的多,西瓜书上集成学习部分讲到了bagging和随机森林,只有4页纸还是容易看懂的。接下来会依次介绍以下内容
- 集成算法介绍
- 随机森林分类器
- 随机森林回归器
- 随机森林调参实例
使用sklearn的时候肯定会使用到python语法,numpy,pandas,matplotlib的使用,个人的机器学习目录里面写到了半小时入门这些数据分析必备内容,建议先看下。
集成学习
集成学习通过构建并结合多个学习器来完成学习任务的,这多个学习器又称为弱学习期或者说基学习期,指的是预测的效果不那么好。通过对这多个弱学习器进行结合,比如进行线性组合形成一个强学习器,指的是预测效果较好的学习器。
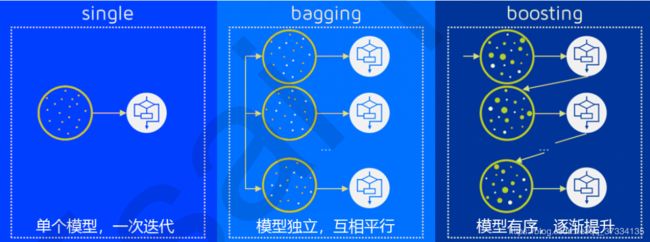
目前有两类比较流行的集成学习方法
(1)、基学习器之间存在强依赖关系,必须串行生成的序列化方法,代表是Boosting,比如Adaboost、GBDT和XGBoost;
(2)、基学习器之间不存在强依赖关系,可同时生成的并行化方法,代表是Bagging和随机森林。
sklearn中的集成学习模块如下

接下来介绍随机森林分类和随机森林回归
随机森林分类
随机森林分类的思想简单来说是这样的,对于分类问题来说,一棵分类的决策树的预测效果不好,那么就采用多棵树来进行分类然后采用投票的方法,比如对于二分类问题来说,有25课树,其中13课判定为正类,12课判断为负类,最终判断为正类。稍微具体点就是,可以认为是增强版的Baggging,也就是对样本分25次采样,每次采样的样本数为n,然后也是从所有特征中抽取部分出来最后建立决策树,最后预测的时候采用投票规则。
class sklearn.ensemble.RandomForestClassifier (n_estimators=’10’, criterion=’gini’, max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’,
max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False,
n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None)
可以发现这些参数大部分跟决策树是一样的,需要注意的是这里有个参数n_estimators十分重要,表示的是生成决策树的个数,默认是10,0.22版本后就会改成了100,显然就是树越多,模型的效果越好了。
下面的操作全在jupyter lab中完成
#一、在红酒数据集上看看决策树和随机森林的效果
#导入需要的包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
#加载到红酒数据集 是个字典
wine = load_wine()
#实例化决策树模型和随机森林模型
clf = DecisionTreeClassifier(random_state=15)
rfc = RandomForestClassifier(random_state=15)
#训练集和测试集的划分
Xtrain,Xtest,Ytrain,Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
#进行模型的拟合
clf.fit(Xtrain,Ytrain)
rfc.fit(Xtrain,Ytrain)
#获取模型的评分
score_1 = clf.score(Xtest,Ytest)
score_2 = rfc.score(Xtest,Ytest)
print("决策树:评分{}".format(score_1),"随机森林:评分{}".format(score_2))
输出:决策树:评分0.9074074074074074 随机森林:评分0.9444444444444444
显然随机森林的效果比决策树好多了
#二、决策树和随机森林在一组交叉验证下的对比
from sklearn.model_selection import cross_val_score
clf = DecisionTreeClassifier(random_state=15)
rfc = RandomForestClassifier(random_state=15)
#进行交叉验证 数据分成的是10等分
score_1 = cross_val_score(clf,wine.data,wine.target,cv=10)
score_2 = cross_val_score(rfc,wine.data,wine.target,cv=10)
plt.plot(range(1,11),score_1,label="Decision Tree")
plt.plot(range(1,11),score_2,label="RandomForest")
plt.legend()
plt.show()
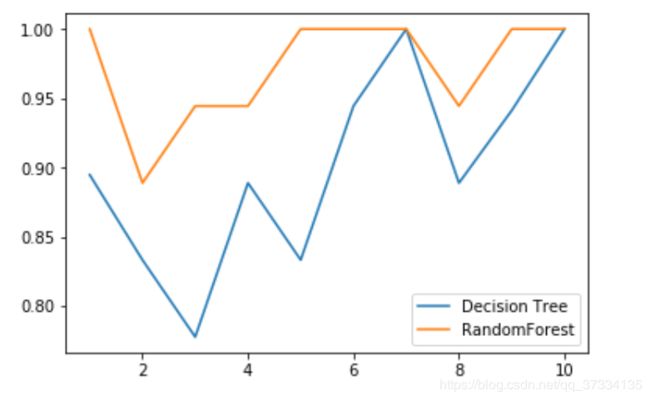
在十组训练集和测试集中都可以看出,随机森林的效果比决策树好不少。
#三、随机森林和决策树在十组交叉验证下的效果对比
clf_l = []
rfc_l = []
for i in range(10):
clf = DecisionTreeClassifier()
rfc = RandomForestClassifier()
l1 = cross_val_score(clf,wine.data,wine.target,cv=5).mean()
l2 = cross_val_score(rfc,wine.data,wine.target,cv=5).mean()
clf_l.append(l1)
rfc_l.append(l2)
plt.plot(range(1,11),clf_l,label="Decision Tree")
plt.plot(range(1,11),rfc_l,label="RandomForest")
plt.legend()
plt.show()

十次交叉验证的结果同样也是随机森林的效果比决策树好的多。
之前不是说了n_estimators这个参数的值越大效果越好吗,画一下学习曲线来观测下
#四、n_estimators的学习曲线2分多钟
rfc_l = []
for i in range(200):
rfc = RandomForestClassifier(n_estimators=i+1)
rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean()
rfc_l.append(rfc_s)
print(max(rfc_l),rfc_l.index(max(rfc_l))+1)
plt.plot(range(1,201),rfc_l,label='随机森林')
plt.legend()
plt.show()

从1到22左右都是明显递增,后面就呈现了上下波动的情况,所以说明前面说的没问题了,但是实际上也不会设置不必要的大的值,因为当数据量大的时候模型跑的就很慢了,我上面那个几百行数据都跑了好几分钟。
对于图上的乱码问题,是matplotlib的问题,加上下面两行
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
那么为什么随机森林的效果比决策树好那么多呢?假设决策树的准确率为0.8误判率为 ϵ = 0.2 \epsilon=0.2 ϵ=0.2,随机森林生成的是25课决策树,至少有13棵树误判了才会误判,所以可以算下随机森林的误判率。
ϵ = ∑ i = 13 25 C 25 i ϵ i ( 1 − ϵ ) 25 − i = 0.00036904803455582827 \epsilon=\sum\limits_{i=13}^{25}C_{25}^{i}\epsilon^i(1-\epsilon)^{25-i}=0.00036904803455582827 ϵ=i=13∑25C25iϵi(1−ϵ)25−i=0.00036904803455582827
计算使用如下的代码
#五、计算误判率
from scipy.special import comb
np.array([comb(25,i)*(0.2**i)*(0.8**(25-i)) for i in range(13,26)]).sum()
在介绍决策树的时候说过,参数random_state参数可以控制每次生成的树都是一样的,而对于随机森林来说,该参数用来控制每次生成的森林是一样的,也就是森林中的每棵树每次生成的时候是一样的,这里顺便也介绍随机森林的属性estimators_
#六、random_state在决策树中控制一棵树,在随机森林中是控制一片森林
rfc = RandomForestClassifier(random_state=10)
rfc.fit(Xtrain,Ytrain)
#使用estimators_属性查看森林中树的情况 可以看单独的一棵树,甚至可以看到参数 决策树是不可以的
#rfc.estimators_[0].random_state
for i in range(len(rfc.estimators_)):
print(rfc.estimators_[i].random_state) #每次都是不变的
每次运行输出的结果都是不变的,如下

前面说了随机森林还是以决策树为基础的,如果所有的决策树都是一样的那么预测效果就不会比单棵决策树好了,所以尽量让这些决策树尽量不一样,sklearn实现随机森林的思想就是让每次采集的样本尽可能不相同,也就是随机采用,而随机森林不是Bagging的提升版本吗。
再说回Bagging,它是bootstrap aggregating的缩写,采用了bootstrap的思想,称为自助法,是一种有放回的抽样方法,见如下介绍
在一个含有n个样本的原始训练集中,我们进行随机采样,每次采样一个样本,并在抽取下一个样本之前将该样本放回原始训练集,也就是说下次采样时这个样本依然可能被采集到,这样采集n次,最终得到一个和原始训练集一样大的,n个样本组成的自助集。由于是随机采样,这样每次的自助集和原始数据集不同,和其他的采样集也是不同的。这样我们就可以自由创造取之不尽用之不竭,并且互不相同的自助集,用这些自助集来训练我们的基分类器,我们的基分类器自然也就各不相同了。
bootstrap参数默认True,代表采用这种有放回的随机抽样技术。通常也不会设置为False。
注意到一点,由于是有放回的抽样,那么就会存在有的数据被抽取多次,有的甚至一次都没抽到,可以计算n次抽取中一个数据最终 被抽到的概率 p = 1 − ( 1 − 1 n ) n p=1-(1-\frac{1}{n})^n p=1−(1−n1)n当n很大的时候那么p就接近 1 − 1 e = 0.632 1-\frac{1}{e}=0.632 1−e1=0.632了,可以认为会有36.8%的数据被浪费了,称为袋外数据(out of bag data 简称oob)。那么我们就可以不用划分训练集,而是使用者36.8%的数据来做测试集了。使用参数oob_score=True即可,此时可以使用属性oob_score_来获取得分。不过对于数据量小的时候就别这样了
#七、oob_score_属性 参数oob_score=True表示使用袋外数据进行测试
rfc = RandomForestClassifier(random_state=20,oob_score=True)
rfc.fit(wine.data,wine.target)
rfc.oob_score_ #查看分数
随机森林回归
#八、随机森林回归 和分类基本一样
from sklearn.datasets import load_boston
from sklearn.ensemble import RandomForestRegressor
#使用波士顿房价数据集
boston = load_boston()
frr = RandomForestRegressor(random_state=20)
#评分标准是R平方,如果想使用MSE那么就使用交叉验证好了
frr_s = cross_val_score(frr,boston.data,boston.target,cv=10,scoring="neg_mean_squared_error")
下面介绍一个使用回归来填补缺失值的方法,主要还是用来练手下数据分析库numpy,pandas。大过年的就不想解释一步步咋做了,大概说一次步骤
加载数据集,将数据集中一半元素设置为缺失值nan,然后分别使用0,均值和回归值来填补缺失值,最后分别使用这些数据集来进行打分看看哪种填补缺失值的方法会好一些。
关于怎么使用回归来填补缺失值,大概介绍下
对于设置了nan后的矩阵,价格nan个数最多的列(特征)抽取出来,该列中将所有未缺失的记录看做Ytrain,对应的其他特征+标签看做Xtrain,缺失的部分看做Ytest,对应的其他特征+标签看做Xtest。同时将其他缺失值全部补0,此时使用回归得到Ytest,重复以上过程。
#九、用随机森林回归来填补缺失值
from sklearn.impute import SimpleImputer
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_boston
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
boston = load_boston()
#boston.data.shape #(506, 13) =6578个数据
X_mat,Y_mat = boston.data, boston.target
X_ori,Y_ori = X_mat.copy(), Y_mat.copy()#记住要用copy不能直接赋值,负责最后X_ori就变了
samples_ = X_mat.shape[0]
features_ = X_mat.shape[1]
#让一半数据缺失
missing_rate = 0.5
missing_num = int(round(samples_*features_*missing_rate))
rng = np.random.RandomState(10)
missing_rec = rng.randint(0,samples_,missing_num)
missging_features = rng.randint(0,features_,missing_num)
X_mat[missing_rec,missging_features] = np.nan
X_mat = pd.DataFrame(X_mat)
#使用均值填充缺失值
strategy_mean = SimpleImputer(missing_values=np.nan,strategy='mean')
X_mat_mean = strategy_mean.fit_transform(X_mat)
#使用0填补缺失值
strategy_0 = SimpleImputer(missing_values = np.nan, strategy='constant', fill_value= 0)
X_mat_0 = strategy_0.fit_transform(X_mat)
#使用回归填补缺失值
X_mat_reg = X_mat.copy()
sorted_index = np.argsort(X_mat_reg.isnull().sum(axis=0))
for i in sorted_index:
df = X_mat_reg
Y_fill = df.iloc[:,i]#获取需要填补的列 行对行进行拼接
new_matrix = pd.concat([df.iloc[:,df.columns != i],pd.DataFrame(Y_mat)],axis=1)#新的特征矩阵
#缺失的位置填补0 此时得到了numpy类型的数组ndarray
new_matrix = SimpleImputer(missing_values=np.nan,strategy='constant',fill_value=0).fit_transform(new_matrix)
#获取新的训练集和测试集
Ytrain = Y_fill[Y_fill.notnull()]
Ytest = Y_fill[Y_fill.isnull()]
Xtrain = new_matrix[Ytrain.index,:]
Xtest = new_matrix[Ytest.index]
#进行拟合
rfr = RandomForestRegressor(n_estimators=100)
rfr.fit(Xtrain,Ytrain)
Y_predict = rfr.predict(Xtest)
#进行填补
X_mat_reg.loc[X_mat_reg.iloc[:,i].isnull(),i] = Y_predict
#进行建模
mse = []
for i in [X_ori,X_mat_mean,X_mat_0,X_mat_reg]:
rfr = RandomForestRegressor(n_estimators=100)
score_ = cross_val_score(rfr,i,Y_ori,cv = 10,scoring="neg_mean_squared_error").mean()
mse.append(score_*-1)
print(mse)
输出
[21.964833688980388, 31.832657715450978, 37.473234113960785, 18.107877085411765]
能够看出效果比使用均值和0填充效果要好。
随机森林调参
当模型在未知数据(测试集或者袋外数据)上表现糟糕时,我们说模型的泛化程度不够,泛化误差大,模型的效果不好。泛化误差受到模型的结构(复杂度)影响。看下面这张图,它准确地描绘了泛化误差与模型复杂度的关系,当模型太复杂,模型就会过拟合,泛化能力就不够,所以泛化误差大。当模型太简单,模型就会欠拟合,拟合能力就不够,所以误差也会大。只有当模型的复杂度刚刚好的才能够达到泛化误差最小的目标。

考虑随机森林模型,对于里面的单棵决策树来说,树越茂盛,深度越深,叶子节点过多那么树的模型就越复杂,而默认的决策树参数是可以让树无限生长下去直到满足停止条件(比如全部归为了一类,或者达到了min_samples_leaf、min_samples_split的限制),所以一般来说,决策树很容易过拟合,几乎天生就位于上图的右上角,大部分情况都是想办法使得复杂度降低到上图中的最佳模型复杂度附近,随机森林是由多棵决策树组成的,所以情况也和决策树一样。调参主要关注以下几点
- 模型太复杂或者太简单,都会让泛化误差高,我们追求的是位于中间的平衡点
- 模型太复杂就会过拟合,模型太简单就会欠拟合
- 对树模型和树的集成模型来说,树的深度越深,枝叶越多,模型越复杂
- 树模型和树的集成模型的目标,都是减少模型复杂度,把模型往图像的左边移动
主要关注的是以下几个参数
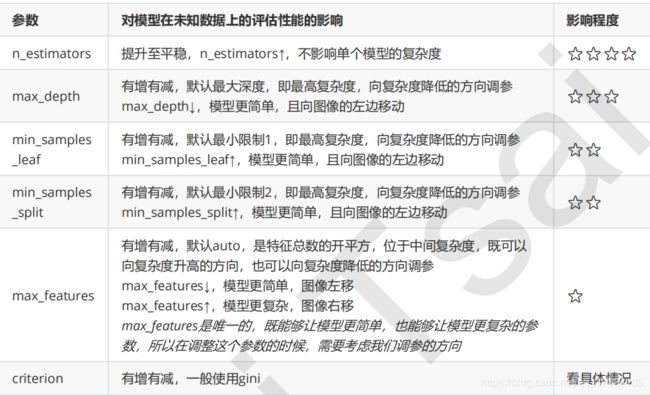
关于n_estimators的调参,如果数据量大,跑学习曲线时间会很多,可以考虑,先确定个大致范围再最终确认具体数值。
#十一、乳腺癌数据上的调参
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
rf = RandomForestClassifier(random_state=10)
score = cross_val_score(rf,cancer.data,cancer.target,cv=10).mean()
score
输出是0.9580427361507218
#n_estimators的学习曲线 确定大致范围 间隔是10
scores = []
for i in range(0,200,10):
rf = RandomForestClassifier(n_estimators=i+1,random_state=10)
score = cross_val_score(rf,cancer.data,cancer.target,cv=10).mean()
scores.append(score)
print(max(scores))
plt.plot(range(1,201,10),scores)
plt.show()
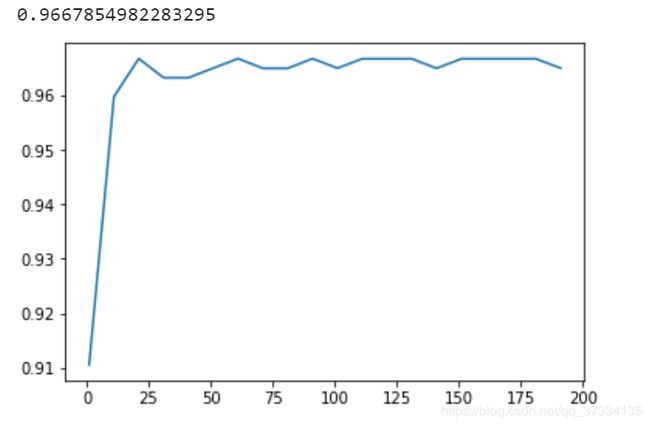
发现了在10棵树和25棵树之间模型最好,那么再确定具体数值
#n_estimators的学习曲线 最终确定
scores_2 = []
for i in range(10,25):
rf = RandomForestClassifier(n_estimators=i+1,random_state=10)
score = cross_val_score(rf,cancer.data,cancer.target,cv=10).mean()
scores_2.append(score)
print(max(scores_2),scores_2.index(max(scores_2))+10+1)
plt.plot(range(11,26),scores_2)
plt.show()

最后确定了是21棵树的时候模型效果最好。
接下来就进入网格搜索,我们将使用网格搜索对参数一个个进行调整。为什么我们不同时调整多个参数呢?原因有两个:1)同时调整多个参数会运行非常缓慢,2)同时调整多个参数,会让我们无法理解参数的组合是怎么得来的,所以即便网格搜索调出来的结果不好,我们也不知道从哪里去改
个人觉得,如果知道大致趋势那么使用学习曲线来确定范围和趋势,否则使用网格搜索比较好。
#耍一下网格搜索,其实一般是不大好进行预测的时候用
from sklearn.model_selection import GridSearchCV
grid_params = {"max_depth":np.arange(1,11,1)}
rf = RandomForestClassifier(n_estimators=21,random_state=20)
grid = GridSearchCV(rf,grid_params,cv = 10)
grid.fit(cancer.data,cancer.target)
print(grid.best_params_,grid.best_score_)
输出 {‘max_depth’: 7} 0.9630931458699473
发现其实并没有有所提升,说明了调整了n_estimators后模型可能就几乎达到了最佳复杂度,如果此时还非要限制每课树的深度,那么无异于将复杂度从模型最低点往左推了,使得泛华误差更大,对于max_depth,min_samples_leaf ,min_samples_split也是一样的,就不去写出来 了。
注意:sklearn自带的乳腺癌数据效果太好了,所以很难看出来一下调出巨好的效果,可以去kaggle上去试试,我比较赶时间就不去整了。