模拟登陆获取脉脉好友信息
代码已经上传到github上
简介:
这是一个基于python3而写的爬虫,爬取的网站的脉脉网(https://maimai.cn/),在搜索框中搜索“CHO”,并切换到“人脉”选项卡,点击姓名,进入详情页,爬取其详细信息
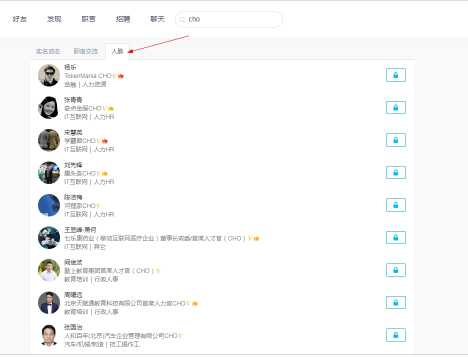
获取的具体信息有:
基本信息、工作经历、教育经历、职业标签及其认可数、点评信息
几度关系:一度、二度、三度等
写给用户的
注意:如果你只是想使用这个项目,那么你可以看这里
如何使用:
使用之前,你要已经保证安装好相关的库和软件:
- re
- requests
- selenium
- logging
- pymysql
- chrome
- mysql
使用:
- 从github上复制代码
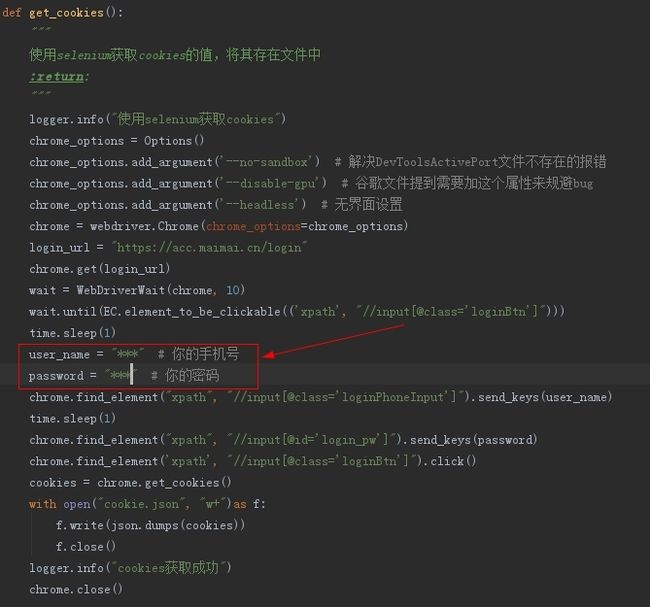
- 填写自己的脉脉手机号和密码(你可以在login.py文件中找到他)
- 建表(详细建表见下)
- 运行程序login.py
详细建表
需要5张表,下面附上代码:
- 表1:basic_info(脉脉好友基本信息)
CREATE TABLE `basic_info` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`name` varchar(56) NOT NULL COMMENT '名字',
`mmid` int(11) NOT NULL COMMENT 'mmid',
`rank` int(11) DEFAULT NULL COMMENT '影响力',
`company` varchar(128) DEFAULT NULL COMMENT '目前公司简称',
`stdname` varchar(128) DEFAULT NULL COMMENT '目前公司全称',
`position` varchar(128) DEFAULT NULL COMMENT '目前职位',
`headline` text COMMENT '自我介绍',
`ht_province` varchar(128) DEFAULT NULL COMMENT '家乡-省',
`ht_city` varchar(128) DEFAULT NULL COMMENT '家乡-城市',
`email` varchar(128) DEFAULT NULL COMMENT '邮箱',
`mobile` varchar(128) DEFAULT NULL COMMENT '手机',
`dist` tinyint(1) DEFAULT NULL COMMENT '几度关系',
PRIMARY KEY (`id`),
UNIQUE KEY `mmid` (`mmid`)
) ENGINE=InnoDB AUTO_INCREMENT=873 DEFAULT CHARSET=gbk ROW_FORMAT=DYNAMIC COMMENT='脉脉好友基本信息'
]
- 表2:education_exp(脉脉好友教育经历)
CREATE TABLE `education_exp` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`mmid` int(11) NOT NULL COMMENT 'mmid',
`school_name` varchar(128) DEFAULT NULL COMMENT '学校名称',
`department` varchar(128) DEFAULT NULL COMMENT '专业',
`education` int(5) DEFAULT NULL COMMENT '学历(0:专科,1:本科,2:硕士,3:博士,255:其他)',
`start_year` int(11) DEFAULT NULL COMMENT '开始时间(年)默认为0000',
`start_mon` int(11) DEFAULT NULL COMMENT '开始时间(月)默认为0000',
`end_year` int(11) DEFAULT NULL COMMENT '结束时间(年)默认为0000',
`end_mon` int(11) DEFAULT NULL COMMENT '结束时间(月)默认为0000',
PRIMARY KEY (`id`),
UNIQUE KEY `mmid` (`mmid`,`school_name`,`education`,`start_year`)
) ENGINE=InnoDB AUTO_INCREMENT=1064 DEFAULT CHARSET=gbk ROW_FORMAT=DYNAMIC COMMENT='脉脉好友教育经历'
- 表3:review_info(脉脉好友点评信息)
CREATE TABLE `review_info` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`mmid` int(11) NOT NULL COMMENT 'mmid',
`reviewer` varchar(128) DEFAULT NULL COMMENT '点评人',
`relationship` varchar(128) DEFAULT NULL COMMENT '关系',
`position` varchar(128) DEFAULT NULL COMMENT '点评人职位',
`eva_info` text COMMENT '评价信息',
PRIMARY KEY (`id`),
UNIQUE KEY `mmid` (`mmid`,`reviewer`)
) ENGINE=InnoDB AUTO_INCREMENT=400 DEFAULT CHARSET=gbk ROW_FORMAT=DYNAMIC COMMENT='脉脉好友点评信息'
- 表4:tag_info(脉脉好友点评信息)
CREATE TABLE `tag_info` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`mmid` int(11) NOT NULL COMMENT 'mmid',
`tag` varchar(128) DEFAULT NULL COMMENT '标签',
`rec_num` varchar(128) DEFAULT NULL COMMENT '认可度',
PRIMARY KEY (`id`),
UNIQUE KEY `UNIQUE` (`mmid`,`tag`,`rec_num`)
) ENGINE=InnoDB AUTO_INCREMENT=5881 DEFAULT CHARSET=gbk ROW_FORMAT=DYNAMIC COMMENT='脉脉好友点评信息'
- 表5:work_exp(脉脉好友工作经历)
CREATE TABLE `work_exp` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`mmid` int(11) NOT NULL COMMENT 'mmid',
`company` varchar(128) DEFAULT NULL COMMENT '公司简称',
`stdname` varchar(128) DEFAULT NULL COMMENT '公司全称',
`et_url` varchar(244) DEFAULT NULL COMMENT '公司页面url',
`description` text COMMENT '描述',
`start_year` int(11) DEFAULT NULL COMMENT '开始时间(年)默认0000',
`start_mon` int(11) DEFAULT NULL COMMENT '开始时间(月)默认0000',
`end_year` int(11) DEFAULT NULL COMMENT '结束时间(年)默认0000',
`end_mon` int(11) DEFAULT NULL COMMENT '结束时间(月)默认0000',
`position` varchar(128) DEFAULT NULL COMMENT '职位',
PRIMARY KEY (`id`),
UNIQUE KEY `UNIQUE` (`mmid`,`company`,`start_year`,`position`)
) ENGINE=InnoDB AUTO_INCREMENT=2582 DEFAULT CHARSET=gbk ROW_FORMAT=DYNAMIC COMMENT='脉脉好友工作经历'
写给开发者的
如果你是一个开发者,那么请看这里
具体的每个函数的作用,就不细说了,代码中有注释,可以自行查看
请求:
在这里我们主要说说请求这一块:
请求需要解决2个问题:
- 第一个是使用cookies模拟登陆
- 第二个是数据获取
模拟登陆
这是使用selenium驱动浏览器登录脉脉,然后获取cookie这样来就省去了自己去拼接cookie的麻烦,获取到cookie之后,在利用cookie来进行requests请求数据,这里不再使用selenium是因为selenium太慢,而且比较容易出错
看一下代码,思路是:
- 设置selenium参数
- 使用selenium打开到登录网址
- 输入手机号和密码,进行登录
- 获取cookies,并存到json文件中
这样就获取cookies成功了,之后将cookies添加到requests请求中,进行数据获取
def get_cookies():
"""
使用selenium获取cookies的值,将其存在文件中
:return:
"""
logger.info("使用selenium获取cookies")
chrome_options = Options()
chrome_options.add_argument('--no-sandbox') # 解决DevToolsActivePort文件不存在的报错
chrome_options.add_argument('--disable-gpu') # 谷歌文件提到需要加这个属性来规避bug
chrome_options.add_argument('--headless') # 无界面设置
chrome = webdriver.Chrome(chrome_options=chrome_options)
login_url = "https://acc.maimai.cn/login"
chrome.get(login_url)
wait = WebDriverWait(chrome, 10)
wait.until(EC.element_to_be_clickable(('xpath', "//input[@class='loginBtn']")))
time.sleep(1)
user_name = "***" # 你的手机号
password = "***" # 你的密码
chrome.find_element("xpath", "//input[@class='loginPhoneInput']").send_keys(user_name)
time.sleep(1)
chrome.find_element("xpath", "//input[@id='login_pw']").send_keys(password)
chrome.find_element('xpath', "//input[@class='loginBtn']").click()
cookies = chrome.get_cookies()
with open("cookie.json", "w+")as f:
f.write(json.dumps(cookies))
f.close()
logger.info("cookies获取成功")
chrome.close()
数据获取
这里面主要有2个问题:
- 第一个网站使用了ajax加载,我们需要找到我们需要的url
- 第二个是获取的html需要进行处理,才能被我们所利用
ajax加载
直接去请求https://maimai.cn/web/search_center?type=contact&query=cho&highlight=true这里,获取的信息是不全的,这里使用了ajax加载,我们打开google看一下,按F12打开开发者模式看一下
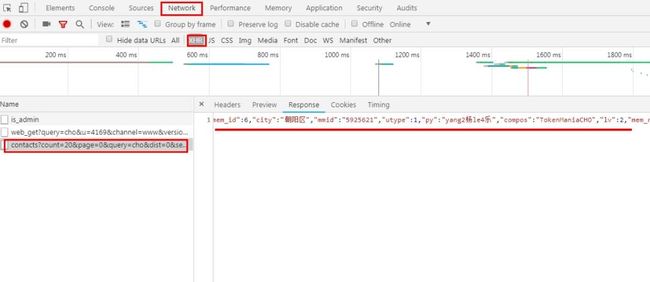
如图,我们可以在这里找我们需要的数据,这个是url:https://maimai.cn/search/contacts?count=20&page=0&query=cho&dist=0&searchTokens=&highlight=true&jsononly=1&pc=1,这里获取的是json格式的数据,非常好解析,再进一步去获取详细信息的页面的时候,其方法也是一样的,这里就不多做说明了
html页面数据处理的问题
有一部分的数据是以json的形式返回给我们的,但是还有一些数据是在原网页中一起返回的,虽然也是json的形式,但是处理起来还是有一定的麻烦,看一下原网页的数据

这个JSON.parse后面的数据也是我们需要的,可以发现这里有一些像"\u0022"的数据,这个其实是双引号的utf8编码,还有一些其他的字符,会以utf8编码的形式返回的,直接处理很不好处理,我们先将这些字符编码替换为对应的字符,之后转成json的格式进行解析,这样就方便多了,看一下代码:
def json_info(html):
"""
处理获取的html,转换为json格式
:param html:
:return:
"""
print(html.text)
c = re.search('JSON\.parse\("(.*?)"\);思路是很简单的:
- 先是将用正则匹配所需要的数据
- 拿下来之后将一些utf8编码的字符替换掉
- 转换为json的格式进行解析
主要需要解决的问题就只有这些,其他的一些数据处理,存储都是很简单和常见的,就不多做说明了